深度神经网络(DNN)模型与前向传播算法
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一个总结。
1. 从感知机到神经网络
在感知机原理小结中,我们介绍过感知机的模型,它是一个有若干输入和一个输出的模型,如下图:
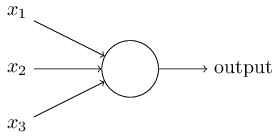
输出和输入之间学习到一个线性关系,得到中间输出结果:$$z=\sum\limits_{i=1}^mw_ix_i + b$$
接着是一个神经元激活函数:
$$sign(z)=
\begin{cases}
-1& {z<0}\\
1& {z\geq 0}
\end{cases}$$
从而得到我们想要的输出结果1或者-1。
这个模型只能用于二元分类,且无法学习比较复杂的非线性模型,因此在工业界无法使用。
而神经网络则在感知机的模型上做了扩展,总结下主要有三点:
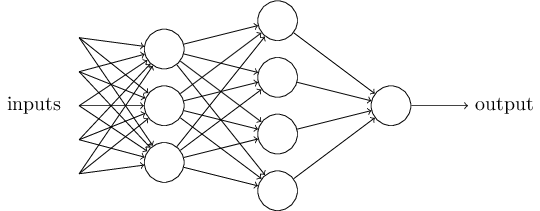
1)加入了隐藏层,隐藏层可以有多层,增强模型的表达能力,如下图实例,当然增加了这么多隐藏层模型的复杂度也增加了好多。
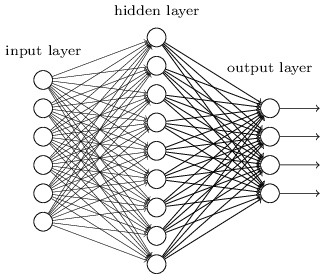
2)输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活的应用于分类回归,以及其他的机器学习领域比如降维和聚类等。多个神经元输出的输出层对应的一个实例如下图,输出层现在有4个神经元了。
3) 对激活函数做扩展,感知机的激活函数是$sign(z)$,虽然简单但是处理能力有限,因此神经网络中一般使用的其他的激活函数,比如我们在逻辑回归里面使用过的Sigmoid函数,即:$$f(z)=\frac{1}{1+e^{-z}}$$
还有后来出现的tanx, softmax,和ReLU等。通过使用不同的激活函数,神经网络的表达能力进一步增强。对于各种常用的激活函数,我们在后面再专门讲。
2. DNN的基本结构
上一节我们了解了神经网络基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。这个很多其实也没有什么度量标准, 多层神经网络和深度神经网络DNN其实也是指的一个东西,当然,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP), 名字实在是多。后面我们讲到的神经网络都默认为DNN。
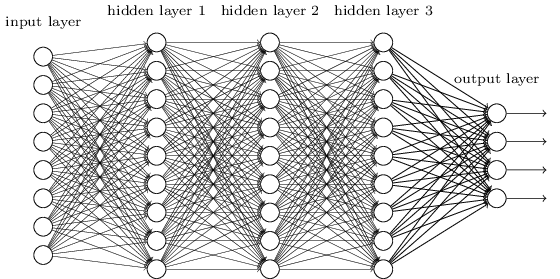
从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输出层,最后一层是输出层,而中间的层数都是隐藏层。
层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系$z=\sum\limits w_ix_i + b$加上一个激活函数$\sigma(z)$。
由于DNN层数多,则我们的线性关系系数$w$和偏倚$b$的数量也就是很多了。具体的参数在DNN是如何定义的呢?
首先我们来看看线性关系系数$w$的定义。以下图一个三层的DNN为例,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为$w_{24}^3$。上标3代表线性系数$w$所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。你也许会问,为什么不是$w_{42}^3$, 而是$w_{24}^3$呢?这主要是为了便于模型用于矩阵表示运算,如果是$w_{24}^3$而每次进行矩阵运算是$w^Tx+b$,需要进行转置。将输出的索引放在前面的话,则线性运算不用转置,即直接为$wx+b$。总结下,第$l-1$层的第k个神经元到第$l$层的第j个神经元的线性系数定义为$w_{jk}^l$。注意,输入层是没有$w$参数的。
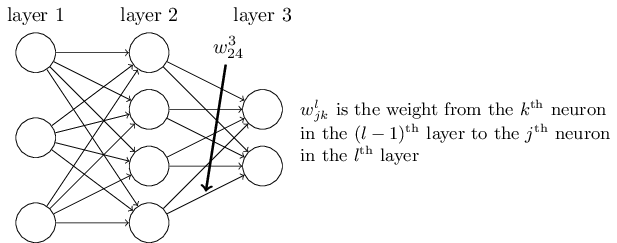
再来看看偏倚$b$的定义。还是以这个三层的DNN为例,第二层的第三个神经元对应的偏倚定义为$b_3^{2}$。其中,上标2代表所在的层数,下标3代表偏倚所在的神经元的索引。同样的道理,第三个的第一个神经元的偏倚应该表示为$b_1^{3}$。同样的,输入层是没有偏倚参数$b$的。
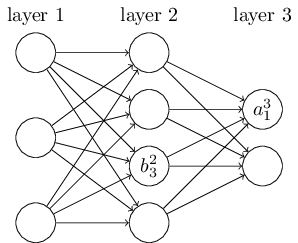
3. DNN前向传播算法数学原理
在上一节,我们已经介绍了DNN各层线性关系系数$w$,偏倚$b$的定义。假设我们选择的激活函数是$\sigma(z)$,隐藏层和输出层的输出值为$a$,则对于下图的三层DNN,利用和感知机一样的思路,我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法。
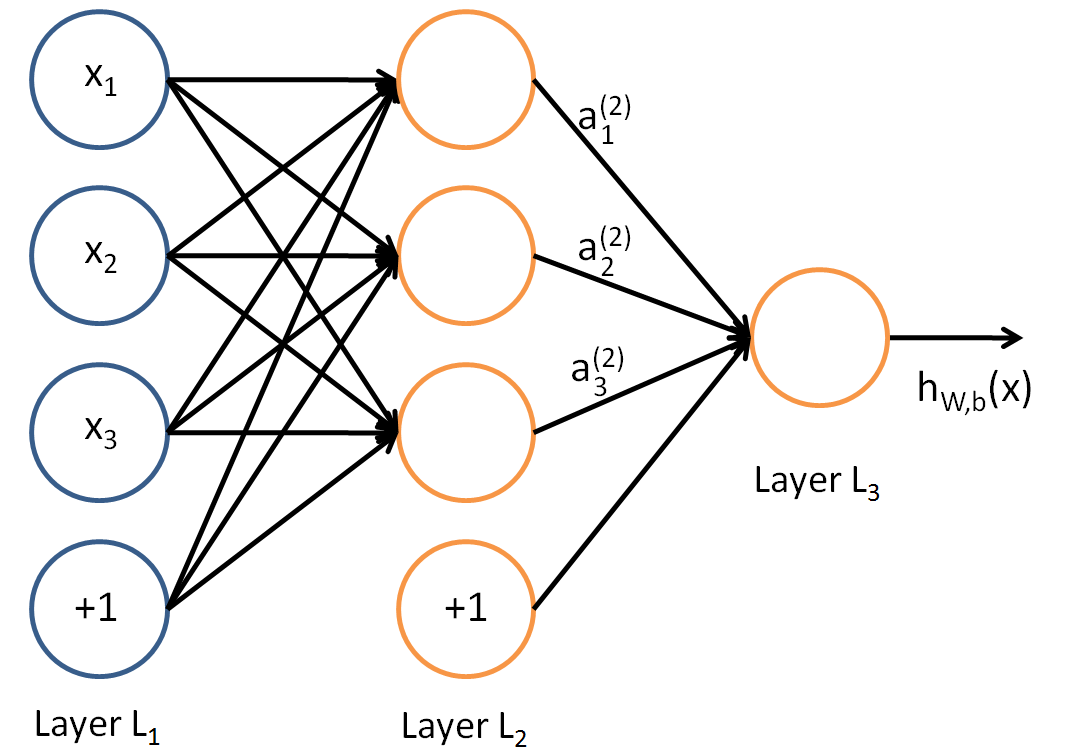
对于第二层的的输出$a_1^2,a_2^2,a_3^2$,我们有:$$a_1^2=\sigma(z_1^2) = \sigma(w_{11}^2x_1 + w_{12}^2x_2 + w_{13}^2x_3 + b_1^{2})$$$$a_2^2=\sigma(z_2^2) = \sigma(w_{21}^2x_1 + w_{22}^2x_2 + w_{32}^2x_3 + b_2^{2})$$$$a_3^2=\sigma(z_3^2) = \sigma(w_{31}^2x_1 + w_{32}^2x_2 + w_{33}^2x_3 + b_3^{2})$$
对于第三层的的输出$a_1^3$,我们有:$$a_1^3=\sigma(z_1^3) = \sigma(w_{11}^3a_1^2 + w_{12}^3a_2^2 + w_{13}^3a_3^2 + b_3^{3})$$
将上面的例子一般化,假设第$l-1$层共有m个神经元,则对于第$l$层的第j个神经元的输出$a_j^l$,我们有:$$a_j^l = \sigma(z_j^l) = \sigma(\sum\limits_{k=1}^mw_{jk}^la_k^{l-1} + b_j^l)$$
其中,如果$l=2$,则对于的$a_k^1$即为输入层的$x_k$。
从上面可以看出,使用代数法一个个的表示输出比较复杂,而如果使用矩阵法则比较的简洁。假设第$l-1$层共有m个神经元,而第$l$层共有n个神经元,则第$l$层的线性系数$w$组成了一个$n \times m$的矩阵$W^l$, 第$l$层的偏倚$b$组成了一个$n \times 1$的向量$b^l$ , 第$l-1$层的的输出$a$组成了一个$m \times 1$的向量$a^{l-1}$,第$l$层的的未激活前线性输出$z$组成了一个$n \times 1$的向量$z^{l}$, 第$l$层的的输出$a$组成了一个$n \times 1$的向量$a^{l}$。则用矩阵法表示,第l层的输出为:$$a^l = \sigma(z^l) = W^la^{l-1} + b^l$$
这个表示方法简洁漂亮,后面我们的讨论都会基于上面的这个矩阵法表示来。
4. DNN前向传播算法
有了上一节的数学推导,DNN的前向传播算法也就不难了。所谓的DNN的前向传播算法也就是利用我们的若干个权重系数矩阵$W$,偏倚向量$b$来和输入值向量$x$进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。
输入: 总层数L,所有隐藏层和输出层对应的矩阵$W$,偏倚向量$b$,输入值向量$x$
输出:输出层的输出$a^L$
1) 初始化$a^1 = x $
2) for $l = 2$ to $L$, 计算:$$a^l = \sigma(z^l) = W^la^{l-1} + b^l$$
最后的结果即为输出$a^L$。
5. DNN前向传播算法小结
单独看DNN前向传播算法,似乎没有什么大用处,而且这一大堆的矩阵$W$,偏倚向量$b$对应的参数怎么获得呢?怎么得到最优的矩阵$W$,偏倚向量$b$呢?这个我们在讲DNN的反向传播算法时再讲。而理解反向传播算法的前提就是理解DNN的模型与前向传播算法。这也是我们这一篇先讲的原因。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
深度神经网络(DNN)模型与前向传播算法的更多相关文章
- 循环神经网络(RNN)模型与前向反向传播算法
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系.今天我们就讨论另一类输出和模型间有反馈的神经网络:循环神经网络(Rec ...
- 《神经网络的梯度推导与代码验证》之FNN(DNN)的前向传播和反向推导
在<神经网络的梯度推导与代码验证>之数学基础篇:矩阵微分与求导中,我们总结了一些用于推导神经网络反向梯度求导的重要的数学技巧.此外,通过一个简单的demo,我们初步了解了使用矩阵求导来批量 ...
- 卷积神经网络(CNN)前向传播算法
在卷积神经网络(CNN)模型结构中,我们对CNN的模型结构做了总结,这里我们就在CNN的模型基础上,看看CNN的前向传播算法是什么样子的.重点会和传统的DNN比较讨论. 1. 回顾CNN的结构 在上一 ...
- 深度神经网络DNN的多GPU数据并行框架 及其在语音识别的应用
深度神经网络(Deep Neural Networks, 简称DNN)是近年来机器学习领域中的研究热点,产生了广泛的应用.DNN具有深层结构.数千万参数需要学习,导致训练非常耗时.GPU有强大的计算能 ...
- 卷积神经网络 cnnff.m程序 中的前向传播算法 数据 分步解析
最近在学习卷积神经网络,哎,真的是一头雾水!最后决定从阅读CNN程序下手! 程序来源于GitHub的DeepLearnToolbox 由于确实缺乏理论基础,所以,先从程序的数据流入手,虽然对高手来讲, ...
- 前向传播算法(Forward propagation)与反向传播算法(Back propagation)
虽然学深度学习有一段时间了,但是对于一些算法的具体实现还是模糊不清,用了很久也不是很了解.因此特意先对深度学习中的相关基础概念做一下总结.先看看前向传播算法(Forward propagation)与 ...
- 2. CNN卷积网络-前向传播算法
1. CNN卷积网络-初识 2. CNN卷积网络-前向传播算法 3. CNN卷积网络-反向更新 1. 前言 我们已经了解了CNN的结构,CNN主要结构有输入层,一些卷积层和池化层,后面是DNN全连接层 ...
- 深度学习——前向传播算法和反向传播算法(BP算法)及其推导
1 BP算法的推导 图1 一个简单的三层神经网络 图1所示是一个简单的三层(两个隐藏层,一个输出层)神经网络结构,假设我们使用这个神经网络来解决二分类问题,我们给这个网络一个输入样本,通过前向运算得到 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
随机推荐
- 微信公众号支付开发全过程 --JAVA
按照惯例,开头总得写点感想 ------------------------------------------------------------------ 业务流程 这个微信官网说的还是很详细的 ...
- iOS学习笔记(十三)——获取手机信息(UIDevice、NSBundle、NSLocale)
iOS的APP的应用开发的过程中,有时为了bug跟踪或者获取用反馈的需要自动收集用户设备.系统信息.应用信息等等,这些信息方便开发者诊断问题,当然这些信息是用户的非隐私信息,是通过开发api可以获取到 ...
- WINDOWS下搭建SVN服务器端的步骤分享(Subversion)
1.获取svn程序 2.安装 Subversion(以下简称SVN)的服务器端和客户端.下载下来的服务器端是个 zip压缩包,直接解压缩即可,比如我解压到 E:\subversion .客户端安装文件 ...
- 编译uboot提示libasm-offsets.c10 error bad value (armv5)解决方法
编译uboot-2016.09提示如下错误: lib/asm-offsets.c:1:0: error: bad value (armv5) for -march= switch 解决方法: 1.在命 ...
- 单纯觉得是篇好文——跨终端Web之Hybrid App
[reference]http://www.infoq.com/cn/articles/hybrid-app#theCommentsSection 编者按:InfoQ开设新栏目“品味书香”,精选技术书 ...
- Bzoj1479: [Nerrc1997]Puncher打孔机
1479: [Nerrc1997]Puncher打孔机 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 22 Solved: 14[Submit][Sta ...
- OI队内测试一【数论概率期望】
版权声明:未经本人允许,擅自转载,一旦发现将严肃处理,情节严重者,将追究法律责任! 序:代码部分待更[因为在家写博客,代码保存在机房] 测试分数:110 本应分数:160 改完分数:200 T1: 题 ...
- 画廊视图(Gallery)的功能和用法
Gallery与Spinner组件有共同的父类:AbsSpinner,表明Gallery和Spinner是同一个列表框.它们之间的区别是Spinner显示的垂直的列表选择框,而Gallery显示的是一 ...
- C语言中strcpy,strcmp,strlen,strcat函数原型
//strcat(dest,src)把src所指字符串添加到dest结尾处(覆盖dest结尾处的'\0')并添加'\0' char *strcat(char * strDest, const char ...
- Ninja介绍
什么是Ninja 在Unix/Linux下通常使用Makefile来控制代码的编译,但是Makefile对于比较大的项目有时候会比较慢,看看上面那副漫画,代码在编译都变成了程序员放松的借口了.所以这个 ...