统计英文文章中各单词的频率,打印频率最高的十个单词(C语言实现)
一、程序思路及相关代码
首先打开文件,代码如下
FILE *fp;
char fname[10];
printf("请输入要分析的文件名:\n");
scanf("%s",fname);
if((fp=fopen(fname,"r"))==NULL){ //读取文件内容,并返回文件指针,该指针指向文件的第一个字符
fprintf(stderr,"error opening.\n");
exit(1);
}
对于文件的扫描,以字符为单位
do{
ch=fgetc(fp);
if(ch==' '||ch==','||ch=='.'||ch==';') //如果是空格,自动跳到下个字符
scanner(fp);
else{
fseek(fp,-1,1); //如果不是空格,则回退一个字符并扫描
scanner(fp);
}
}while (ch!=EOF);
要统计单词频率,首先要将文章分为单个单词
int zimu(char ch){
if((ch >= 'A' && ch <= 'Z')
|| (ch >= 'a' && ch <= 'z'))
return ch;
else
return 0;
}
void scanner(FILE *fp)
{
char b[20];
ch=fgetc(fp);
if(zimu(ch))
{ //判断该字符是否是字母
b[0]=ch;
ch=fgetc(fp); //调用函数扫描字符
i=1;
while(zimu(ch))
{
b[i] = ch;
i++;
ch = fgetc(fp);
}
fseek(fp,-1,1);
b[i] = '\0';
k++;
strcpy(w[k].c,b);
}
}
对于单词,为单词创建结构体
struct word
{
char c[];//单词词组
int n;//单词个数
}w[];
统计各个单词的个数
for(i=1;i<k+1;i++)
w[i].n=1;
for(i=1;i<k+1;i++)
{
for(j=i+1;j<k+1;j++)
{
if(strcmp(w[i].c,w[j].c)==0)
{
w[i].n++;
w[j].n=0;
}
if(w[i].n==0)//将已统计的单词跳过
break;
}
}
将单词按个数多少进行排序
for(i=;i<k+;i++)
{
for(j=;j<k+-i;j++)
{
if(w[i].n>w[j].n)//交换结构体内数据
{
t=w[i].n;
strcpy(a,w[i].c);
w[i].n=w[j].n;
strcpy(w[i].c,w[j].c);
w[j].n=t;
strcpy(w[j].c,a);
}
}
}
printf("英文文章中频率最高10个单词及个数为:\n");
for(i=;i<;i++)
printf("%d: %s %d\n",i,w[i].c,w[i].n);
}
二、遇到问题
(1)对于单词的扫描,后来查看编译中的词法分析解决了
(2)对于词组的复制,使用strcpy(w[k].c,b);解决将词组c复制到结构体数组中
(3)对于单词个数统计,
if(w[i].n==)//将已统计的单词跳过
break;
将与后面单词相同的跳过,避免出现重复
三、程序过程统计
二月26号下午,2个小时思考程序思路,并书写大体框架
二月27号上机时间,将扫描和单词分解完成
二月27号完成程序
四、程序运行截图
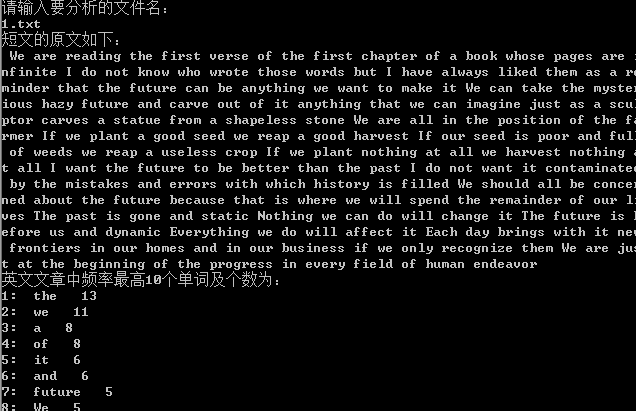
统计英文文章中各单词的频率,打印频率最高的十个单词(C语言实现)的更多相关文章
- C++语言,统计一篇英文文章中的单词数(用正则表达式实现)
下面的例子展示了如何在C++11中,利用regex_search()统计一篇英文文章中的单词数: #include <iostream> #include <regex> #i ...
- Linux作业(三)-shell统计某文章中出现频率最高的N个单词并排序输出出现次数
Linux课上的作业周三交,若有考虑不周到的地方,还请多多不吝赐教. shell处理文本相关的经常使用命令见此博客 # #假设输入两个參数 则第一个为统计单词的个数.第二个为要统计的文章 #假设输入一 ...
- python统计英文文本中的回文单词数
1. 要求: 给定一篇纯英文的文本,统计其中回文单词的比列,并输出其中的回文单词,文本数据如下: This is Everyday Grammar. I am Madam Lucija And I a ...
- C#统计英文文本中的单词数并排序
思路如下:1.使用的Hashtable(高效)集合,记录每个单词出现的次数2.采用ArrayList对Hashtable中的Keys按字母序排列3.排序使用插入排序(稳定) public void S ...
- 练习1-12:编写一个程序,以每行一个单词的形式打印其输入(C程序设计语言 第2版)
#include <stdio.h> #define NOT_BLANK 1 #define BLANK 0 main() { int c; int last_ch = NOT_BLANK ...
- JAVA实验--统计文章中单词的个数并排序
分析: 1)要统计单词的个数,就自己的对文章中单词出现的判断的理解来说是:当出现一个非字母的字符的时候,对前面的一部分字符串归结为单词 2)对于最后要判断字母出现的个数这个问题,我认为应该是要用到ma ...
- N个任务掌握java系列之统计一篇文章中单词出现的次数
问题:统计一篇文章中单词出现的次数 思路: (1)将文章(一个字符串存储)按空格进行拆分(split)后,存储到一个字符串(单词)数组中. (2)定义一个Map,key是字符串类型,保存单词:valu ...
- 1st 英文文章词频统计
英文文章词频统计: 功能:统计一篇英文文章的单词总数及出现频数并输出,之后排序,输出频数前十的单词及其频数. 实现方法:使用C语言,用fopen函数读入txt文件,fscanf函数逐个读入单词,结构体 ...
- 『转』统计一个日志文件里,单词出现频率的shell脚本
原文地址:http://blog.csdn.net/taiyang1987912/article/details/39995175 #查找文本中n个出现频率最高的单词 #!/bin/bash coun ...
随机推荐
- zabbix 布署实践【1 server安装】
通过openstack环境,开通了2台只有根分区的虚拟机, 目的是为了监控公司所有的物理机,网络设备,虚拟机,总计300个台以上,推荐配置,zabbix官方文档是有给出指引的 环境:CentO ...
- 在VMware上安装CentOS -7步骤详解
在VMware上安装CentOS -7 一.下载好VMware虚拟机 二.准备好CentOS的镜像文件 在这里安装之前博主都已准备好了. 废话就少啰嗦啦!现在开始安装步骤了 1.首先打开VMware创 ...
- Dubbo服务的搭建与使用
官方地址Dubbo.io Dubbo 主要功能 高并发的负载均衡,多系统的兼容合并(理解不深,不瞎掰了) Dubbo 主要组成有四部分 Zookeeper(服务注册中心) Consumer(服务消费方 ...
- 5.MyBaits调用存储过程
1.创建一个javaweb项目MyBatis_Part4_Procedure 2.在src下创建procedure.sql文件 --创建表 create table p_user( id number ...
- ubuntu搭建git服务器
1.准备两台ubuntu虚拟机,其中一个作为server,另一个作为client.检查是否安装ssh,如果没有安装:sudo apt-get install openssh-server, 然后在se ...
- SAP HANA 能做什么
HANA不是一个数据仓库,而是一个平台,在这个平台之上用户可以构建数据仓库或集市.报表和仪表盘等. HANA能做的,首先是作为内存数据库,提供数据插入.修改和高效的查询功能. 其次,作为一个平台,在H ...
- 灾情巡视C语言代码
/*"水灾巡视问题"模拟退火算法.这是一个推销员问题,本题有53个点,所有可能性大约为exp(53),目前没有好方法求出精确解,既然求不出精确解,我们使用模拟退火法求出一个较优解, ...
- Framebuffer原理、使用、测试系列文章,非常好的资料,大家一起学习
转载:http://blog.csdn.net/tju355/article/details/6881372 *一.FrameBuffer的原理* FrameBuffer 是出现在 2.2.xx 内核 ...
- history对象 back() forward() go() 和pushState() replaceState()
History(Window.history对象)对象保存着用户上网的历史记录.处于安全方面的考虑,开发人员无法得知用户浏览过的URL,但是借由用户访问过的页面列表,同样可以在不知道实际URL的情况下 ...
- @NotNull和@NotEmpty和@NotBlank区别
1.@NotNull:不能为null,但可以为empty (""," "," ") 2.@NotEmpty:不能为null,而且长度必须大于 ...