统计英文文章中各单词的频率,打印频率最高的十个单词(C语言实现)
一、程序思路及相关代码
首先打开文件,代码如下
FILE *fp;
char fname[10];
printf("请输入要分析的文件名:\n");
scanf("%s",fname);
if((fp=fopen(fname,"r"))==NULL){ //读取文件内容,并返回文件指针,该指针指向文件的第一个字符
fprintf(stderr,"error opening.\n");
exit(1);
}
对于文件的扫描,以字符为单位
do{
ch=fgetc(fp);
if(ch==' '||ch==','||ch=='.'||ch==';') //如果是空格,自动跳到下个字符
scanner(fp);
else{
fseek(fp,-1,1); //如果不是空格,则回退一个字符并扫描
scanner(fp);
}
}while (ch!=EOF);
要统计单词频率,首先要将文章分为单个单词
int zimu(char ch){
if((ch >= 'A' && ch <= 'Z')
|| (ch >= 'a' && ch <= 'z'))
return ch;
else
return 0;
}
void scanner(FILE *fp)
{
char b[20];
ch=fgetc(fp);
if(zimu(ch))
{ //判断该字符是否是字母
b[0]=ch;
ch=fgetc(fp); //调用函数扫描字符
i=1;
while(zimu(ch))
{
b[i] = ch;
i++;
ch = fgetc(fp);
}
fseek(fp,-1,1);
b[i] = '\0';
k++;
strcpy(w[k].c,b);
}
}
对于单词,为单词创建结构体
struct word
{
char c[];//单词词组
int n;//单词个数
}w[];
统计各个单词的个数
for(i=1;i<k+1;i++)
w[i].n=1;
for(i=1;i<k+1;i++)
{
for(j=i+1;j<k+1;j++)
{
if(strcmp(w[i].c,w[j].c)==0)
{
w[i].n++;
w[j].n=0;
}
if(w[i].n==0)//将已统计的单词跳过
break;
}
}
将单词按个数多少进行排序
for(i=;i<k+;i++)
{
for(j=;j<k+-i;j++)
{
if(w[i].n>w[j].n)//交换结构体内数据
{
t=w[i].n;
strcpy(a,w[i].c);
w[i].n=w[j].n;
strcpy(w[i].c,w[j].c);
w[j].n=t;
strcpy(w[j].c,a);
}
}
}
printf("英文文章中频率最高10个单词及个数为:\n");
for(i=;i<;i++)
printf("%d: %s %d\n",i,w[i].c,w[i].n);
}
二、遇到问题
(1)对于单词的扫描,后来查看编译中的词法分析解决了
(2)对于词组的复制,使用strcpy(w[k].c,b);解决将词组c复制到结构体数组中
(3)对于单词个数统计,
if(w[i].n==)//将已统计的单词跳过
break;
将与后面单词相同的跳过,避免出现重复
三、程序过程统计
二月26号下午,2个小时思考程序思路,并书写大体框架
二月27号上机时间,将扫描和单词分解完成
二月27号完成程序
四、程序运行截图
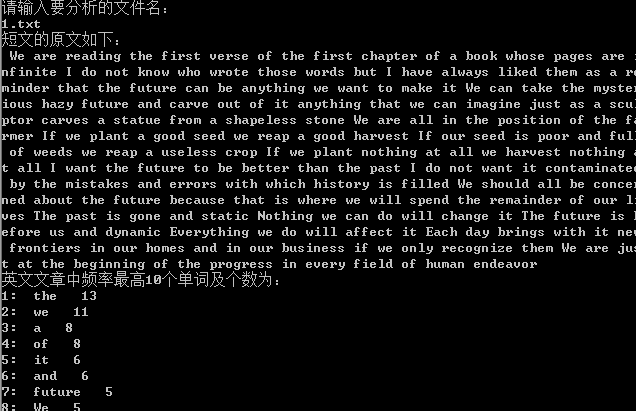
统计英文文章中各单词的频率,打印频率最高的十个单词(C语言实现)的更多相关文章
- C++语言,统计一篇英文文章中的单词数(用正则表达式实现)
下面的例子展示了如何在C++11中,利用regex_search()统计一篇英文文章中的单词数: #include <iostream> #include <regex> #i ...
- Linux作业(三)-shell统计某文章中出现频率最高的N个单词并排序输出出现次数
Linux课上的作业周三交,若有考虑不周到的地方,还请多多不吝赐教. shell处理文本相关的经常使用命令见此博客 # #假设输入两个參数 则第一个为统计单词的个数.第二个为要统计的文章 #假设输入一 ...
- python统计英文文本中的回文单词数
1. 要求: 给定一篇纯英文的文本,统计其中回文单词的比列,并输出其中的回文单词,文本数据如下: This is Everyday Grammar. I am Madam Lucija And I a ...
- C#统计英文文本中的单词数并排序
思路如下:1.使用的Hashtable(高效)集合,记录每个单词出现的次数2.采用ArrayList对Hashtable中的Keys按字母序排列3.排序使用插入排序(稳定) public void S ...
- 练习1-12:编写一个程序,以每行一个单词的形式打印其输入(C程序设计语言 第2版)
#include <stdio.h> #define NOT_BLANK 1 #define BLANK 0 main() { int c; int last_ch = NOT_BLANK ...
- JAVA实验--统计文章中单词的个数并排序
分析: 1)要统计单词的个数,就自己的对文章中单词出现的判断的理解来说是:当出现一个非字母的字符的时候,对前面的一部分字符串归结为单词 2)对于最后要判断字母出现的个数这个问题,我认为应该是要用到ma ...
- N个任务掌握java系列之统计一篇文章中单词出现的次数
问题:统计一篇文章中单词出现的次数 思路: (1)将文章(一个字符串存储)按空格进行拆分(split)后,存储到一个字符串(单词)数组中. (2)定义一个Map,key是字符串类型,保存单词:valu ...
- 1st 英文文章词频统计
英文文章词频统计: 功能:统计一篇英文文章的单词总数及出现频数并输出,之后排序,输出频数前十的单词及其频数. 实现方法:使用C语言,用fopen函数读入txt文件,fscanf函数逐个读入单词,结构体 ...
- 『转』统计一个日志文件里,单词出现频率的shell脚本
原文地址:http://blog.csdn.net/taiyang1987912/article/details/39995175 #查找文本中n个出现频率最高的单词 #!/bin/bash coun ...
随机推荐
- android studio Activity标题栏研究
第一次研究时间:2016/7/30,以下研究主要存在于当前最新版本的android studio上.eclipse请参考 一.头部标题取消 当前版本新建工程在 application中默认主题为 an ...
- Tiny6410之重定位代码到SDRAM
在上一章中,将代码重定位到了SRAM中,但是这样的做法作用不大.正确的做法的是将代码重定位到更大的主存中,即DRAM.Tiny6410的DRAM控制寄存器最多只能支持两个同一类型的芯片.每个芯片最多可 ...
- html5精品教程
链接:http://pan.baidu.com/s/1ntr7yJ3 密码:7qvz链接:http://pan.baidu.com/s/1c0haxZM 密码:paok
- 2014 ACM/ICPC Asia Regional Beijing Site
1001 A Curious Matt 1002 Black And White 1003 Collision 1004 Dire Wolf 1005 Everlasting L 1006 Fluor ...
- pyhon的数据类型
1.数字 整型和浮点型 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647在64位系统上,整数的位数为64位,取值范围为-2** ...
- zabbix 布署实践【2 agent安装】
客户端的安装相对较为简单,主要是更新它的repo源 以CentOS7为例 rpm -ivh http://repo.zabbix.com/zabbix/3.0/rhel/7/x86_64/zabb ...
- HDU 5868 Different Circle Permutation
公式,矩阵快速幂,欧拉函数,乘法逆元. $an{s_n} = \frac{1}{n}\sum\limits_{d|n} {\left[ {phi(\frac{n}{d})×\left( {fib(d ...
- OSI七层模型详解
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 . 完成中继功能的节点通常称为中继系统.在OSI七层模型中,处于 ...
- DB2导入导出 学习笔记
db2pd -osinfodb2mtrk -i -d (for aix)db2 get dbm cfg show detaildb2 get db cfg show detaildb2 get sna ...
- contentType设置类型导致ajax post data 获取不到数据
ajax post data 获取不到数据,注意 content-type的设置 .post/get关于 jQuery data 传递数据.网上各种获取不到数据,乱码之类的. 好吧今天我也遇到了, ...