Spark-寒假-实验3
1.安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装 Spark(Local 模式)。

2.HDFS 常用操作
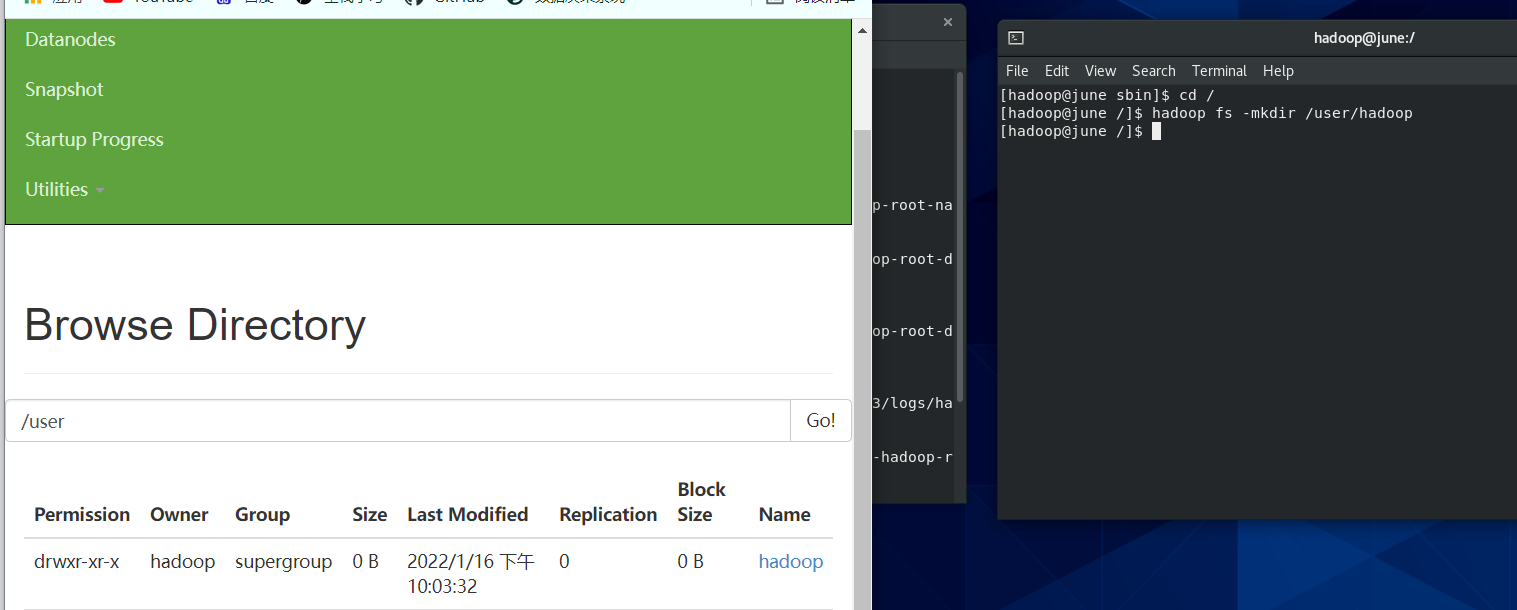
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop” 目录下;

(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文 件系统中的“/home/hadoop/下载”目录下;

(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;

(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;

(6) 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop” 目录下的 input 子目录及其子目录下的所有内容。

3. Spark 读取文件系统的数据
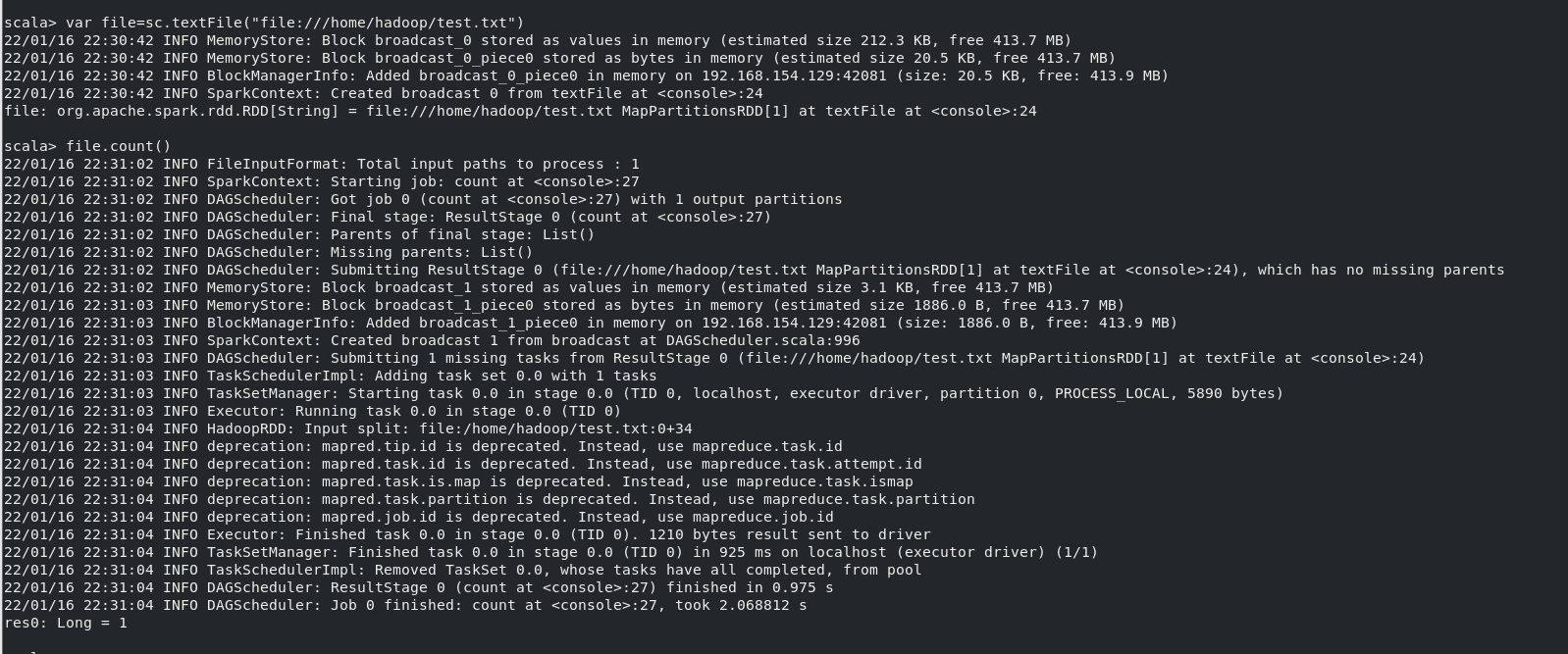
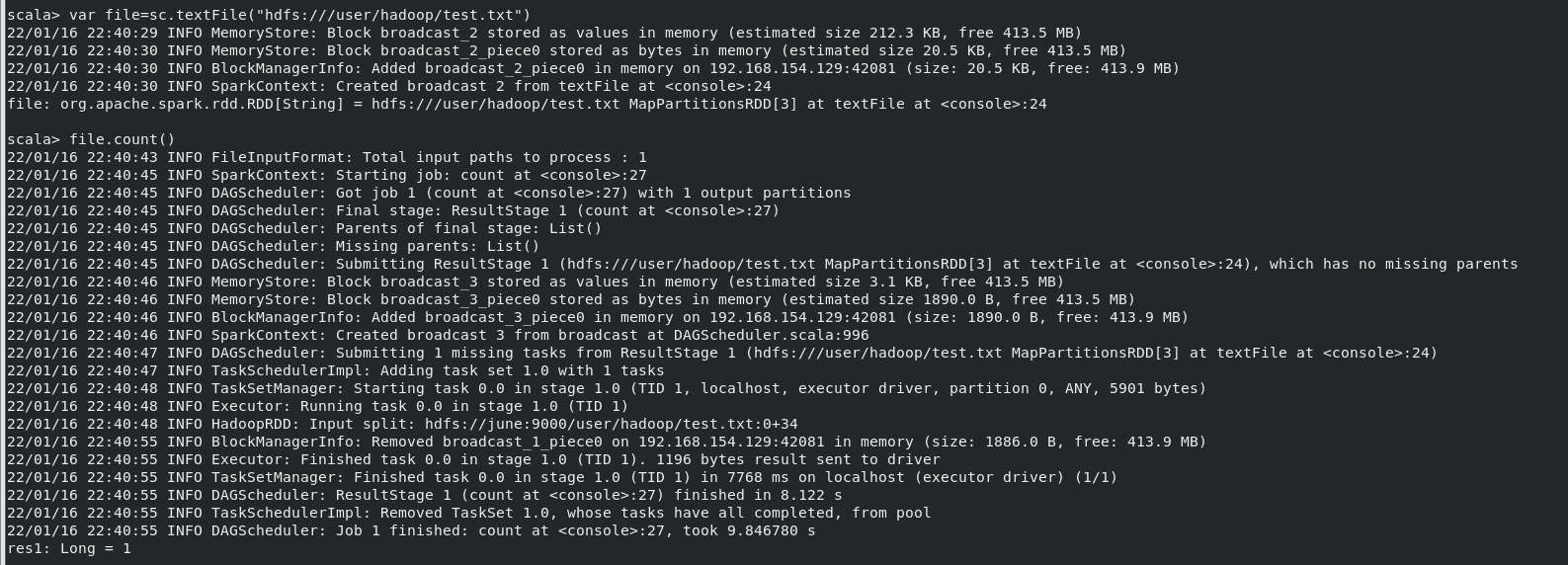
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文 件的行数;
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包, 并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
1)centos下安装sbt
下载压缩包
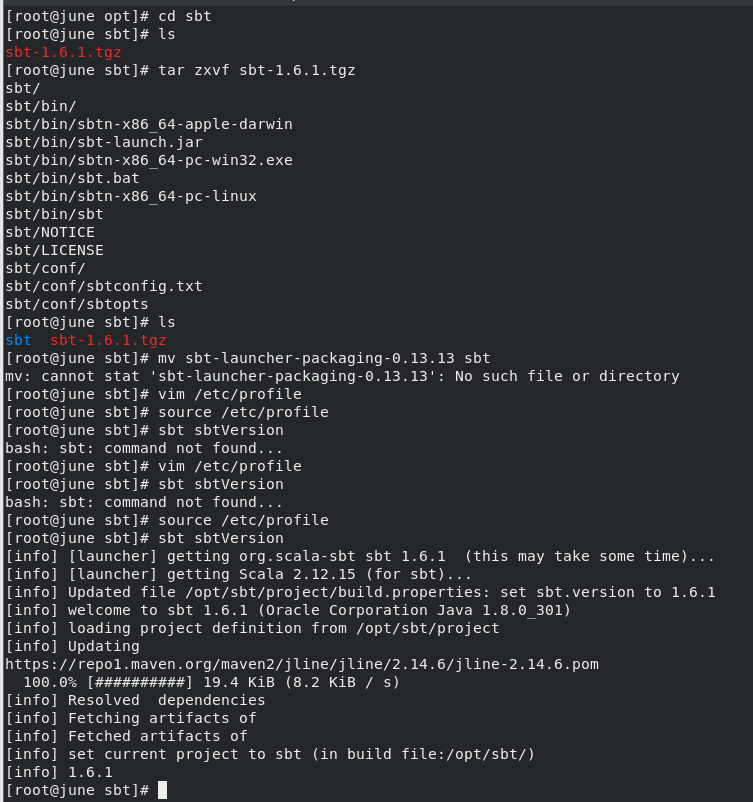
配置环境变量(根据需要复制路径,修改自己所下压缩包的版本号):
export JAVA_HOME=/opt/java/jdk1.8.0_301
export HADOOP_HOME=/opt/Hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export SPARK_HOME=/opt/spark/spark-2.1.0-bin-hadoop2.6
export SCALA_HOME=/opt/scala/scala-2.11.8
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export SBT_HOME=/opt/sbt/sbt
export PATH=.:${JAVA_HOME}/bin:${HIVE_HOME}/bin:${HADOOP_HOME}/bin:/opt/mongodb/bin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:${SBT_HOME}/bin:$PATH
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HIVE_HOME=/opt/hive/apache-hive-2.3.9-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
2)创建项目(在自己的目录下创建wordcount文件夹,下图为进入wordcount文件夹后的有关操作)

test.scala(localhost记得改为自己虚拟机的静态ip,hdfs相关路径以及文件名亦需要修改为自己的)
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val logFile = "hdfs://localhost:9000/user/hadoop/Data01.txt"
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2)
val num = logData.count()
printf("The num of this file is %d", num)
}
}
simple.sbt(scala的版本号即scalaVersion,请根据自己的scala版本进行修改)
name := "WordCount Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.2"
3)打包项目(命令自己打,几个字母)

4)运行jar包(jar包一般在/wordcount/target/scala-2.11/下)

运行: 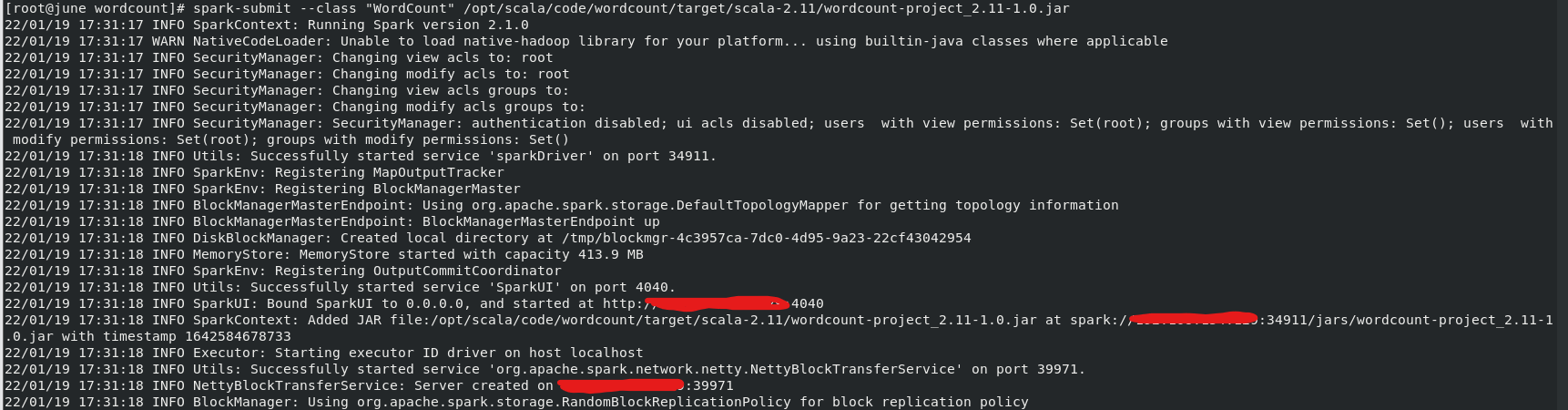
运行结果(在运行日志的打印信息中):

Spark-寒假-实验3的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 2019寒假训练营第三次作业part2 - 实验题
热身题 服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小. 所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系.需要在的电脑上装上虚拟机和linux系统 安装虚拟机(可参 ...
- 1.Spark Streaming另类实验与 Spark Streaming本质解析
1 Spark源码定制选择从Spark Streaming入手 我们从第一课就选择Spark子框架中的SparkStreaming. 那么,我们为什么要选择从SparkStreaming入手开始我们 ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
随机推荐
- CF1108A Two distinct points 题解
Content 有 \(q\) 次询问,每次询问给定四个数 \(l_1,r_1,l_2,r_2\).对于每次询问,找到两个数 \(a,b\),使得 \(l_1\leqslant a\leqslant ...
- windows生成ssh上传git代码
打开 执行 ssh-keygen -t rsa -C "email@email.com" #换成你的git登录账号 中间肯会有提示确认的 然后在 C:\Users(用户)\你电脑用 ...
- Springboot在工具类(Util)中使用@Autowired注入Service
1. 使用@Component注解标记工具类MailUtil: 2. 使用@Autowired注入我们需要的bean: 3. 在工具类中编写init()函数,并使用@PostConstruct注解标记 ...
- Windows系统安装ActiveMQ
1.下载安装包:https://activemq.apache.org/components/classic/download/ 选择自己的版本进行下载 2.安装JDK 3.把下载的ActiveMQ压 ...
- 惊!世界上竟然有O(N)时间复杂度的排序算法!计数排序!
啥?你以为排序算法的时间复杂度最快也只能O(N*log(N))了? O(N)时间复杂度的排序算法听说过没有?计数排序!!它是世界上最快最简单的算法!!! 计数排序算法操作起来只有三步,看完秒懂! 根据 ...
- 【LeetCode】687. Longest Univalue Path 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 DFS 日期 题目地址:https://leetco ...
- 【LeetCode】154. Find Minimum in Rotated Sorted Array II 解题报告(Python)
[LeetCode]154. Find Minimum in Rotated Sorted Array II 解题报告(Python) 标签: LeetCode 题目地址:https://leetco ...
- 3027 - Corporative Network
3027 - Corporative Network 思路:并查集: cost记录当前点到根节点的距离,每次合并时路径压缩将cost更新. 1 #include<stdio.h> 2 #i ...
- Lucky Substrings
而在26以内且属于fibonacci数列的数为1,2,3,5,8,13,21时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 A string s is LUCKY if ...
- Docker 与 K8S学习笔记(七)—— 容器的网络
本节我们来看看Docker网络,我们这里主要讨论单机docker上的网络.当docker安装后,会自动在服务器中创建三种网络:none.host和bridge,接下来我们分别了解下这三种网络: $ s ...