CVPR2021 | Transformer用于End-to-End视频实例分割
论文:End-to-End Video Instance Segmentation with Transformers
获取:在CV技术指南后台回复关键字“0005”获取该论文。
代码:https://git.io/VisTR
点个关注,专注于计算机视觉技术文章。
前言:
视频实例分割(VIS)是一项需要同时对视频中感兴趣的对象进行分类、分割和跟踪的任务。本文提出了一种新的基于 Transformers 的视频实例分割框架 VisTR,它将 VIS 任务视为直接的端到端并行序列解码/预测问题。
给定一个由多个图像帧组成的视频片段作为输入,VisTR 直接输出视频中每个实例的掩码序列。它的核心是一种新的、有效的实例序列匹配和切分策略,在序列层面对实例进行整体监控和切分。VisTR从相似性学习的角度对实例进行划分和跟踪,大大简化了整个过程,与现有方法有很大不同。
VisTR 在现有的 VIS 模型中速度最快,效果最好的是在 YouTubeVIS 数据集上使用单一模型的方法。这是研究人员首次展示了一种基于 Transformer 的更简单、更快的视频实例分割框架,实现了具有竞争力的准确性。
出发点
SOTA方法通常会开发复杂的pipeline来解决此任务。 Top-down的方法遵循tracking-by-detection范式,严重依赖图像级实例分割模型和复杂的人工设计规则来关联实例。 Bottom-up的方法通过对学习的像素嵌入进行聚类来分离对象实例。由于严重依赖密集预测质量,这些方法通常需要多个步骤来迭代地生成掩码,这使得它们很慢。因此,非常需要一个简单的、端到端可训练的 VIS 框架。
在这里,我们更深入地了解视频实例分割任务。 视频帧包含比单个图像更丰富的信息,例如运动模式和实例的时间一致性,为实例分割和分类提供有用的线索。 同时,更好地学习实例特征可以帮助跟踪实例。 本质上,实例分割和实例跟踪都与相似性学习有关:实例分割是学习像素级的相似性,实例跟踪是学习实例之间的相似性。 因此,在单个框架中解决这两个子任务并相互受益是很自然的。 在这里,我们的目标是开发这样一个端到端的 VIS 框架。该框架需要简单,在没有花里胡哨的情况下实现强大的性能。
主要贡献
我们提出了一种基于 Transformers 的新视频实例分割框架,称为 VisTR,它将 VIS 任务视为直接的端到端并行序列解码/预测问题。该框架与现有方法有很大不同,大大简化了整个流程。
VisTR从相似度学习的新角度解决了VIS。实例分割是学习像素级的相似性,实例跟踪是学习实例之间的相似性。因此,在相同的实例分割框架中无缝自然地实现了实例跟踪。
VisTR 成功的关键是实例序列匹配和分割的新策略,它是为我们的框架量身定制的。这种精心设计的策略使我们能够在序列级别作为一个整体来监督和分割实例。
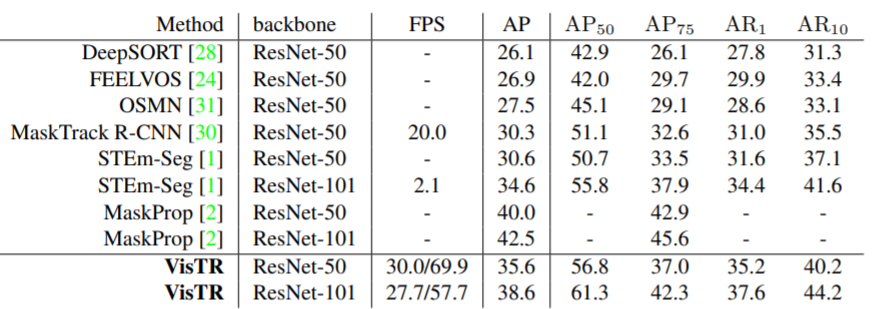
VisTR 在 YouTube-VIS 数据集上取得了强劲的成绩,在 57.7 FPS 的速度下实现了 38.6% 的 mask mAP,这是使用单一模型的方法中最好和最快的。
Methods
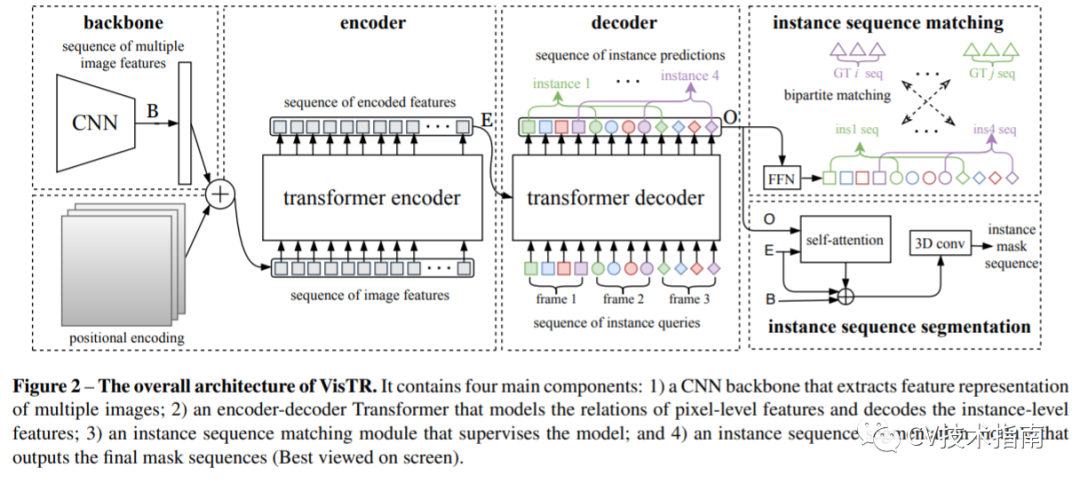

整个 VisTR 架构如图 2 所示。它包含四个主要组件:一个用于提取多个帧的紧凑特征表示的 CNN 主干,一个用于对像素级和实例级特征的相似性进行建模的编码器-解码器 Transformer,一个实例 用于监督模型的序列匹配模块,以及一个实例序列分割模块。
Transformer Encoder
Transformer 编码器用于对片段中所有像素级特征之间的相似性进行建模。 首先,对上述特征图应用 1×1 卷积,将维度从 C 减少到 d (d < C),从而产生新的特征图f1。
为了形成可以输入到 Transformer 编码器中的剪辑级特征序列,我们将 f1 的空间和时间维度展平为一维,从而得到大小为 d × (T·H·W) 的 2D 特征图。请注意,时间顺序始终与初始输入的顺序一致。每个编码器层都有一个标准架构,由一个多头自注意力模块和一个全连接前馈网络 (FFN) 组成。
Transformer Decoder
Transformer 解码器旨在解码可以表示每帧实例的顶部像素特征,称为实例级特征。受 DETR的启发,我们还引入了固定数量的输入嵌入来从像素特征中查询实例特征,称为实例查询。
假设模型每帧解码 n 个实例,那么对于 T 帧,实例查询数为 N = n · T。实例查询是模型学习的,与像素特征具有相同的维度。以编码器 E 的输出和 N 个实例查询 Q 作为输入,Transformer 解码器输出 N 个实例特征,在图 2 中用 O 表示。
整体预测遵循输入帧顺序,不同图像的实例预测顺序为相同的。因此,可以通过将相应索引的项直接链接来实现对不同帧中实例的跟踪。
Instance Sequence Matching
解码器输出的固定数量的预测序列是乱序的,每帧包含n个实例序列。本文与DETR相同,使用匈牙利算法进行匹配。
虽然是实例分割,但是在目标检测中需要用到bounding box,方便组合优化计算。通过FFN计算归一化的bounding box中心、宽度和高度,即全连接。
通过softmax计算bounding box的label。最终得到n×T个边界框。使用上面得到标签概率分布和边界框来匹配实例序列和gournd truth。
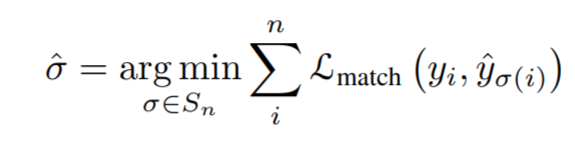
最后计算Hungarian算法的loss,考虑标签的概率分布和bounding box的位置。损失基本遵循DETR的设计,使用L1损失和IOU损失。以下公式是训练的损失。它由标签损失、边界框和实例序列组成。
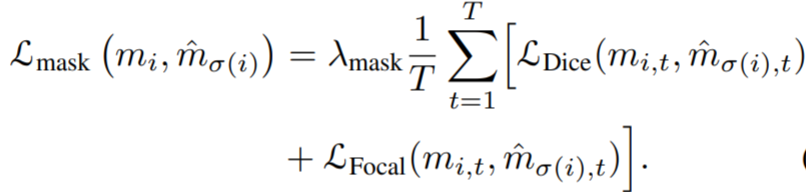
Conclusion
下图展示了 VisTR 在 YouTube VIS 验证数据集上的可视化。每行包含从同一视频中采样的图像。VisTR 可以很好地跟踪和分割具有挑战性的实例,例如:(a) 重叠实例,(b) 实例之间的相对位置变化, 由相同类型的相似实例引起的混淆,以及 (d) 不同姿势的实例。

本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取公众号原创技术总结的汇总pdf

其它文章
经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
在做算法工程师的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进?
CVPR2021 | Transformer用于End-to-End视频实例分割的更多相关文章
- HTML5实战与剖析之媒体元素(6、视频实例)
HTML5中的视频标签和及其模仿视频播放器的效果在一些手机端应用比較多.由于手机端基本上废除了flash的独断.让HTML5当家做主人,所以对视频支持的比較好. 所以今天专门为大家奉上HTML5视频标 ...
- CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等
CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等 CVPR 2020中选论文放榜后,最新开源项目合集也来了. 本届CPVR共接收6656篇论文,中选1470篇,&q ...
- Tensorflow实现Mask R-CNN实例分割通用框架,检测,分割和特征点定位一次搞定(多图)
Mask R-CNN实例分割通用框架,检测,分割和特征点定位一次搞定(多图) 导语:Mask R-CNN是Faster R-CNN的扩展形式,能够有效地检测图像中的目标,同时还能为每个实例生成一个 ...
- 论文速递 | 实例分割算法BlendMask,实时又state-of-the-art
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型效果达到state-of-the-art,但结构十分精简,推理速度 ...
- Deep Snake : 基于轮廓调整的SOTA实例分割方法,速度32.3fps | CVPR 2020
论文提出基于轮廓的实例分割方法Deep snake,轮廓调整是个很不错的方向,引入循环卷积,不仅提升了性能还减少了计算量,保持了实时性,但是Deep snake的大体结构不够优雅,应该还有一些工作可以 ...
- YOLACT : 首个实时one-stage实例分割模型,29.8mAP/33.5fps | ICCV 2019
论文巧妙地基于one-stage目标检测算法提出实时实例分割算法YOLACT,整体的架构设计十分轻量,在速度和效果上面达到很好的trade-off. 来源:[晓飞的算法工程笔记] 公众号 论文: ...
- CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)
CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)1. 目标检测:FCOS(CVPR 2019)目标检测算法FCOS(FCOS: ...
- CVPR2020论文解析:实例分割算法
CVPR2020论文解析:实例分割算法 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation 论文链接:https://arxiv ...
- 实时实例分割的Deep Snake:CVPR2020论文点评
实时实例分割的Deep Snake:CVPR2020论文点评 Deep Snake for Real-Time Instance Segmentation 论文链接:https://arxiv.org ...
随机推荐
- C#调百度通用翻译API翻译HALCON的示例描述
目录 准备工作 参数简介 输入参数 输出参数 使用HttpClient 翻译工具类 应用:翻译HALCON的示例描述 准备工作 HALCON示例程序的描述部分一直是英文的,看起来很不方便.我决定汉化一 ...
- 写DockerFile的一些技巧
Docker镜像由只读层组成,每个层都代表一个Dockerfile指令.这些层是堆叠的,每一层都是前一层变化的增量.示例Dockerfile: FROM ubuntu:15.04 COPY . / ...
- Gogs+Jenkins+Docker 自动化部署.NetCore
环境说明 腾讯云轻量服务器, 配置 1c 2g 6mb ,系统是 ubuntu 20.14,Docker 和 Jenkins 都在这台服务器上面, 群晖218+一台,Gogs 在这台服务器上. Doc ...
- 大白话spring依赖注入
在前边的文章中分享了spring如何实现属性的注入,有注解和配置文件两种方式,通过这两种方式可以实现spring中属性的注入,具体配置可查看<spring入门(一)[依赖注入]>,那么sp ...
- Gerrit+replication 同步Gitlab
配置环境:gerrit 192.168.1.100gitlab 192.168.1.1011.创建秘钥 [root@gerrit ~]# ssh-keygen -m PEM -t rsa 2.添加ho ...
- .Net Core with 微服务 - Consul 配置中心
上一次我们介绍了Elastic APM组件.这一次我们继续介绍微服务相关组件配置中心的使用方法.本来打算介绍下携程开源的重型配置中心框架 apollo 但是体系实在是太过于庞大,还是让我爱不起来.因为 ...
- 利用ONT测序检测真核生物全基因组甲基化状态
摘要 甲基化在真核生物基因组序列中广泛存在,其中5mC最为普遍,在真核生物基因组中也有发现6mA.捕获基因组中的甲基化状态的常用技术是全基因组甲基化测序(WGBS)和简化甲基化测序(RRBS),而随着 ...
- Docker安装MySQL8.0
环境 CentOS 7.5 Docker 1.13.1 MySQL 8.0.16 安装 拉取镜像 默认拉取最新版本的镜像 $ docker pull mysql 如果要指定版本,使用下面的命令 $ d ...
- head tail 用法
tail 显示最后几行,-n后面的数字无符号,表示行数 tail -n 1000:显示最后1000行 tail -n +1000:从1000行开始显示到最后 tail -n -1000:从负1000行 ...
- 16 shell select in 循环
select in 是 Shell 独有的一种循环,适用于与终端(Terminal)进行交互,在其他编程语言中是没有的. 用法 说明 脚本 select var in val_listdo st ...