hive学习笔记之四:分区表
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
本文是《hive学习笔记》系列的第四篇,要学习的是hive的分区表,简单来说hive的分区就是创建层级目录的一种方式,处于同一分区的记录其实就是数据在同一个子目录下,分区一共有两种:静态和动态,接下来逐一尝试;
静态分区(单字段分区)
先尝试用单个字段分区,t9表有三个字段:名称city、年龄age、城市city,以城市作为分区字段:
- 建表:
create table t9 (name string, age int)
partitioned by (city string)
row format delimited
fields terminated by ',';
- 查看:
hive> desc t9;
OK
name string
age int
city string
# Partition Information
# col_name data_type comment
city string
Time taken: 0.159 seconds, Fetched: 8 row(s)
- 创建名为009.txt的文本文件,内容如下,可见每行只有name和age两个字段,用来分区的city字段不在这里设置,而是在执行导入命令的时候设置,稍后就会见到:
tom,11
jerry,12
- 导入数据的命令如下,可见导入命令中制定了city字段,也就是说一次导入的所有数据,city字段值都是同一个:
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t9
partition(city='shenzhen');
- 再执行一次导入操作,命令如下,city的值从前面的shenzhen改为guangzhou:
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t9
partition(city='guangzhou');
- 查询数据,可见一共四条数据,city共有两个值:
hive> select * from t9;
OK
t9.name t9.age t9.city
tom 11 guangzhou
jerry 12 guangzhou
tom 11 shenzhen
jerry 12 shenzhen
Time taken: 0.104 seconds, Fetched: 4 row(s)
- 前面曾提到分区实际上是不同的子目录,来看一下是不是如此,如下图,红框是t9的文件目录,下面有两个子目录city=guangzhou和city=shenzhen:
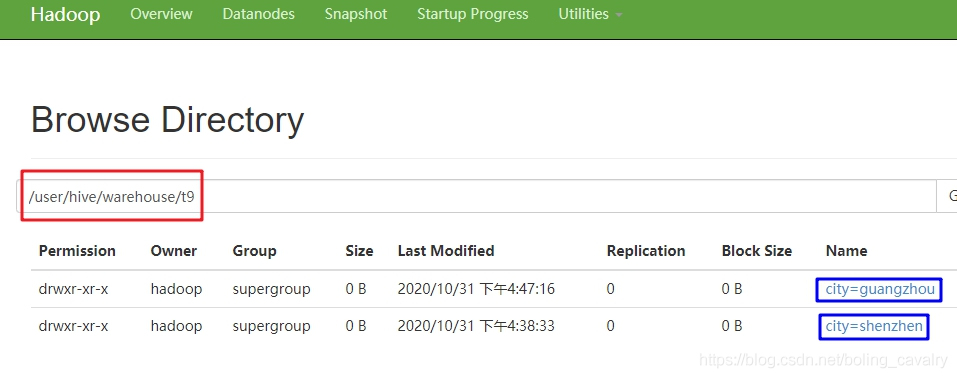
- 查看子目录里面文件的内容,可见每条记录只有name和age两个字段:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/t9/city=guangzhou
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 16 2020-10-31 16:47 /user/hive/warehouse/t9/city=guangzhou/009.txt
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t9/city=guangzhou/009.txt
tom,11
jerry,12
[hadoop@node0 bin]$
以上就是以单个字段做静态分区的实践,接下来尝试多字段分区;
静态分区(多字段分区)
- 新建名为t10的表,有两个分区字段:province和city,建表语句:
create table t10 (name string, age int)
partitioned by (province string, city string)
row format delimited
fields terminated by ',';
- 上述建表语句中,分区字段province写在了city前面,这就意味着第一级子目录是province值,每个province子目录,再按照city值建立二级子目录,图示如下:
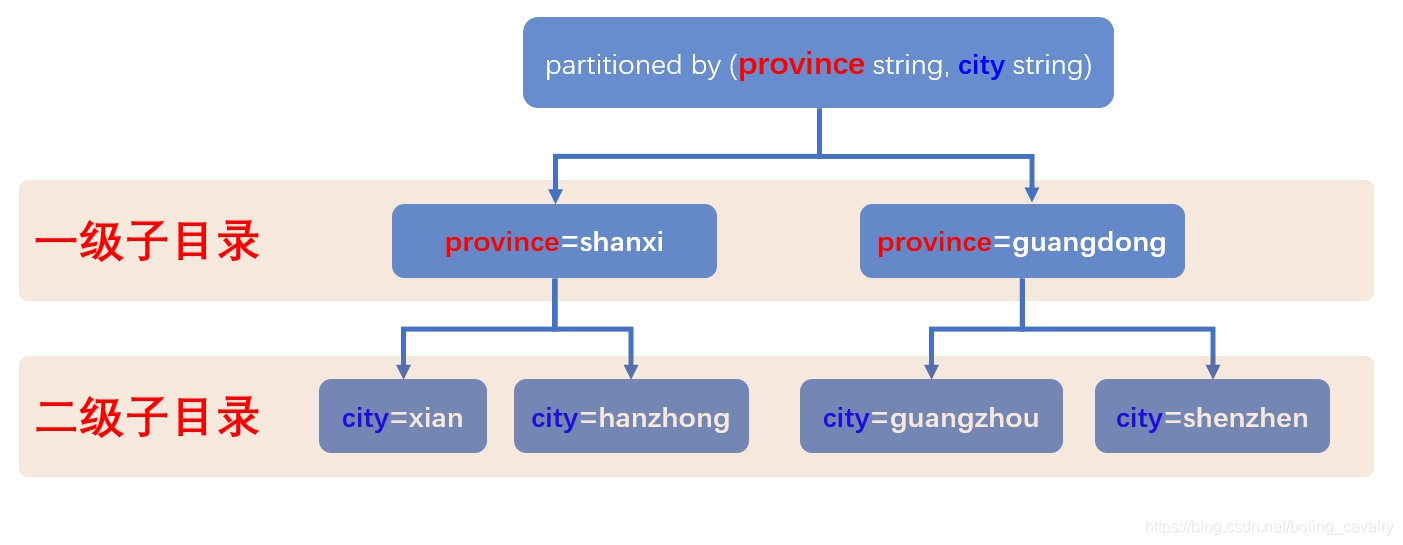
3. 第一次导入,province='shanxi', city='xian':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='shanxi', city='xian');
- 第二次导入,province='shanxi', city='xian':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='shanxi', city='hanzhong');
- 第三次导入,province='guangdong', city='guangzhou':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='guangdong', city='guangzhou');
- 第四次导入,province='guangdong', city='shenzhen':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='guangdong', city='shenzhen');
- 全部数据如下:
hive> select * from t10;
OK
t10.name t10.age t10.province t10.city
tom 11 guangdong guangzhou
jerry 12 guangdong guangzhou
tom 11 guangdong shenzhen
jerry 12 guangdong shenzhen
tom 11 shanxi hanzhong
jerry 12 shanxi hanzhong
tom 11 shanxi xian
jerry 12 shanxi xian
Time taken: 0.129 seconds, Fetched: 8 row(s)
- 查看hdfs文件夹,如下图,一级目录是province字段的值:
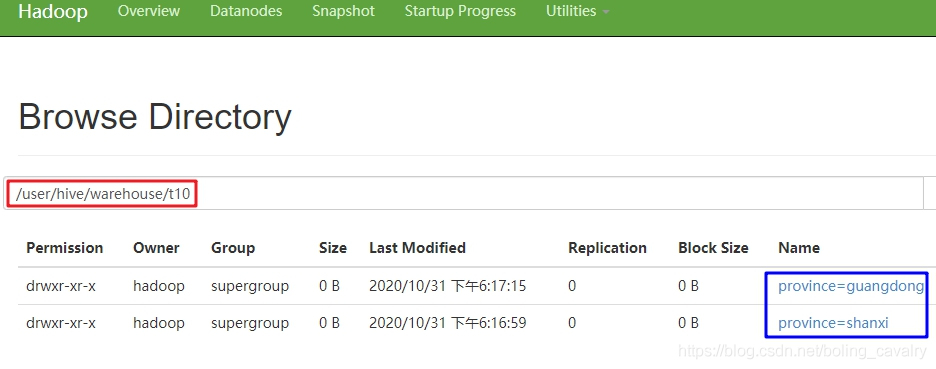
- 打开一个一级目录,如下图,可见二级目录是city的值:
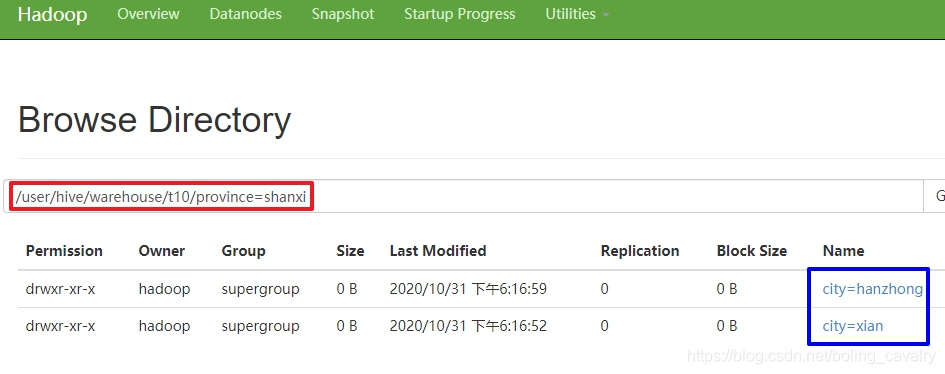
10. 查看数据:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t10/province=shanxi/city=hanzhong/009.txt
tom,11
jerry,12
- 以上就是静态分区的基本操作,可见静态分区有个不便之处:新增数据的时候要针对每一个分区单独使用load命令去操作,这时候使用动态分区来解决这个麻烦;
动态分区
- 动态分区的特点就是不用指定分区目录,由hive自己选择;
- 执行以下命令开启动态分区功能:
set hive.exec.dynamic.partition=true
- 名为hive.exec.dynamic.partition.mode的属性,默认值是strict,意思是不允许分区列全部是动态的,这里改为nostrict以取消此禁制,允许全部分区都是动态分区:
set hive.exec.dynamic.partition.mode=nostrict;
- 建一个外部表,名为t11,只有四个字段:
create external table t11 (name string, age int, province string, city string)
row format delimited
fields terminated by ','
location '/data/external_t11';
- 创建名为011.txt的文件,内容如下:
tom,11,guangdong,guangzhou
jerry,12,guangdong,shenzhen
tony,13,shanxi,xian
john,14,shanxi,hanzhong
- 将011.txt中的四条记录载入表t11:
load data
local inpath '/home/hadoop/temp/202010/25/011.txt'
into table t11;
- 接下来要,先创建动态分区表t12,再把t11表的数据添加到t12中;
- t12的建表语句如下,按照province+city分区:
create table t12 (name string, age int)
partitioned by (province string, city string)
row format delimited
fields terminated by ',';
- 执行以下操作,即可将t11的所有数据写入动态分区表t12,注意,要用overwrite:
insert overwrite table t12
partition(province, city)
select name, age, province, city from t11;
- 通过hdfs查看文件夹,可见一级和二级子目录都符合预期:
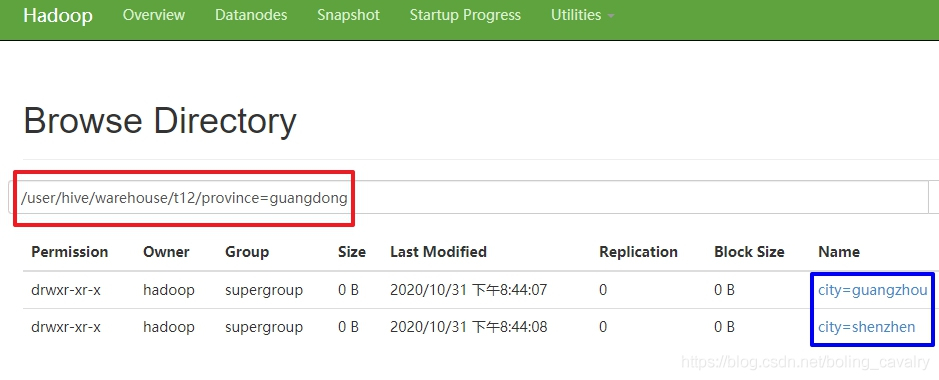
11. 最后检查二级子目录下的数据文件,可以看到该分区下的记录:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t12/province=guangdong/city=guangzhou/000000_0
tom,11
至此,分区表的学习就完成了,希望能给您一些参考;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
hive学习笔记之四:分区表的更多相关文章
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Oracle学习笔记之四sp1,Oracle 11g的常用函数
从Oracle学习笔记之四,SQL语言入门中摘出来的,独立成一章节 3.1 字符类函数 ASCII(c)和CHR(i) 分别用于返回一个字符的ASCII码和返回给定ASCII值所对应的字符. C ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
- hive学习笔记之十一:UDTF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- beta设计和计划
项目 内容 课程:北航-2020-春-软件工程 博客园班级博客 要求 Beta设计和计划 我们在这个课程的目标是 提升团队管理及合作能力,开发一项满意的工程项目 这个作业在哪个具体方面帮助我们实现目标 ...
- 干货!可以使用低代码平台代替Excel吗?
低代码开发平台可以代替Excel?不用惊讶,答案是肯定的,而且,低代码开发平台可以完全代替Excel.例如Zoho Creator低代码平台,可以围绕数据存储.管理和创建工作流程.期间不需要IT人员介 ...
- 【大白话 mysql】mysql 事务与日志原理
在后端面试中,mysql是比不可少的一环,其中对事务和日志的考察更是"重灾区", 大部分同学可能都知道mysql通过redolog.binlog和undolog保证了sql的事务性 ...
- 普里姆(Prim)算法
概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图(即"带权图")里搜索最小生成树.即此算法搜索到的边(Edge)子集所构成的树中,不但包括了连通图里的所有顶点(V ...
- 02、SpringBoot2入门
1.系统要求 Java 8 & 兼容java14 . Maven 3.3+ idea 2019.1.2 1.1.maven设置 <mirrors> <mirror> & ...
- [Linux] 删除find到的目录
参考 https://www.centos.bz/2017/09/linux%E7%B3%BB%E7%BB%9F%E4%B8%8Bfind%E5%91%BD%E4%BB%A4%E9%80%92%E5% ...
- 工作流引擎详解!工作流开源框架ACtiviti的详细配置以及安装和使用
创建ProcessEngine Activiti流程引擎的配置文件是名为activiti.cfg.xml的XML文件.注意与使用Spring方式创建流程引擎是不一样的 使用org.activiti.e ...
- 『动善时』JMeter基础 — 35、JMeter接口关联【JSON提取器】详解
目录 1.JSON提取器介绍 2.JSON提取器界面详解 3.JSON提取器的使用 (1)测试计划内包含的元件 (2)HTTP Cookie管理器内容 (3)用户登陆请求界面内容 (4)JSON提取器 ...
- 使用goland调试远程代码
前言 很多时候我们都在window上使用goland,并直接使用goland调试go代码. 但是很多时候我们的程序运行在Linux服务器上,虽然可以通过dlv命令行进行手动打断点调试,但是太麻烦了. ...
- Socks协议以及代理转发工具分析
前言:最近两场HW都和某师傅学到了挺多东西,算是对内网不出网以及流量代理做个分析(SOCKS协议,reGeorg原理分析,frp的代理,CS上的代理 SOCKS SOCKS(Socks:Protoco ...