标准自编码器(TensorFlow实现)
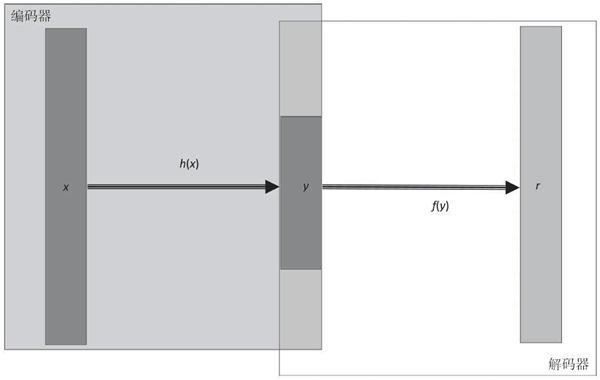
由 Hinton 提出的标准自动编码机(标准自编码器)只有一个隐藏层,隐藏层中神经元的数量少于输入(和输出)层中神经元的数量,这会压缩网络中的信息,因此可以将隐藏层看作是一个压缩层,限定保留的信息。
- 导入所有必要的模块:

- 从 TensorFlow 中获取 MNIST 数据,这里要注意的一点是,标签并没有进行独热编码,因为并没有使用标签来训练网络。自动编码机是通过无监督学习进行训练的:

- 声明 AutoEncoder 类,使用 init 方法初始化自动编码机的权重、偏置和占位符,也可以在 init 方法中构建全部的计算图。还需要定义编码器、解码器,set_session(会话建立)和 fit 方法。此处构建的自动编码机使用简单的均方误差作为损失函数,使用 AdamOptimizer 进行优化:

- 训练时将输入数据转换为 float 型,初始化所有变量并运行会话。在计算时,目前只是测试自动编码机的重构能力:

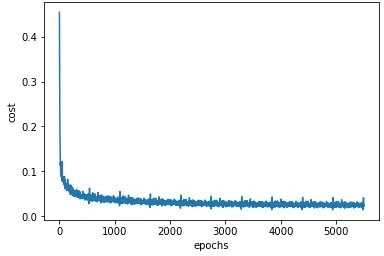
- 绘制误差在训练周期中的变化图,验证网络的均方误差在训练时是否得到优化,对于一个好的训练,误差应该随着训练周期的增加而减少:

- 观察重构的图像,对比原始图像和自动编码机生成的重构图像:



标准自编码器(TensorFlow实现)的更多相关文章
- HEVC(H.265)标准的编码器(x265,DivX265)试用
基于HEVC(H.265)的的应用级别的编码器发展的速度很快.所说的应用级别,就是指速度比较快的,有实际应用价值的编码器.目前可以直接使用的有两个:x265,DivX265. DivX265 DivX ...
- 7 Recursive AutoEncoder结构递归自编码器(tensorflow)不能调用GPU进行计算的问题(非机器配置,而是网络结构的问题)
一.源代码下载 代码最初来源于Github:https://github.com/vijayvee/Recursive-neural-networks-TensorFlow,代码介绍如下:“This ...
- 倍福TwinCAT(贝福Beckhoff)常见问题(FAQ)如何修改标准驱动器编码器分辨率
在某个轴的Enc上双击,可以修改Scaling Factor Numerator 更多教学视频和资料下载,欢迎关注以下信息: 我的优酷空间: http://i.youku.com/acetao ...
- TensorFlow文档翻译-01-TensorFlow入门
版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/junyang/p/7429771.html TensorFlow入门 英文原文地址:https://w ...
- Simotion 绝对值编码器使用外部开关回零
问题来源: 西门子的1FK7二代电机,目前已经没有增量编码器.标准的编码器选项是单圈绝对值,或多圈绝对值. 在某些应用中,如印刷机的版辊.模切轴.飞剪电机等,需要使用外部开关来回零.下文描述了使用外部 ...
- tensorflow数据加载、模型训练及预测
数据集 DNN 依赖于大量的数据.可以收集或生成数据,也可以使用可用的标准数据集.TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用:本教程中用来训练建立模型的一些数据集介绍 ...
- tensorflow批量读取数据
Tensorflow 数据读取有三种方式: Preloaded data: 预加载数据,在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况). Feeding: Pyt ...
- tensorflow实现验证码识别案例
1.知识点 """ 验证码分析: 对图片进行分析: 1.分割识别 2.整体识别 输出:[3,5,7] -->softmax转为概率[0.04,0.16,0.8] - ...
- TensorFlow从0到1之浅谈深度学习(10)
DNN(深度神经网络算法)现在是AI社区的流行词.最近,DNN 在许多数据科学竞赛/Kaggle 竞赛中获得了多次冠军. 自从 1962 年 Rosenblat 提出感知机(Perceptron)以来 ...
随机推荐
- Hangfire在ASP.NET CORE中的简单实现方法
hangfire是执行后台任务的利器,具体请看官网介绍:https://www.hangfire.io/ 新建一个asp.net core mvc 项目 引入nuget包 Hangfire.AspNe ...
- 【工具类】获取请求头中User-Agent工具类
public class AgentUserKit { private static String pattern = "^Mozilla/\\d\\.\\d\\s+\\(+.+?\\)&q ...
- 指定pdf的格式
爬虫实战[3]Python-如何将html转化为pdf(PdfKit) 前言 前面我们对博客园的文章进行了爬取,结果比较令人满意,可以一下子下载某个博主的所有文章了.但是,我们获取的只有文章中的文 ...
- hdu4915 判断括号匹配
题意: 问你括号匹配是否唯一,三种字符'(','?',')',问号可以变成任何字符. 思路: 首先我们要学会判断当前串是否成立?怎么判断?我的方法是跑两遍,开三个变变量 s1 ...
- Access数据库及注入方法
目录 Access数据库 Access数据库中的函数 盲注Access数据库 Sqlmap注入Access数据库 Access数据库 Microsoft Office Access是由微软发布的关系数 ...
- 洛谷P1553 数字反转(升级版)
题目简介 题目描述 给定一个数,请将该数各个位上数字反转得到一个新数. 这次与NOIp2011普及组第一题不同的是:这个数可以是小数,分数,百分数,整数.整数反转是将所有数位对 ...
- PHP Proxy 负载均衡技术
<?php $whitelistPatterns = array( ); $forceCORS = false; $anonymize = true; $startURL = "&qu ...
- Windows Pe 第三章 PE头文件-EX-相关编程-2(RVA_FOA转换)
RVA-FOA之间转换 1.首先PE头加载到内存之后是和文件头内容一样的,就算是偏移不同,一个是磁盘扇区大小(400H)另一个是内存页大小(1000H),但是因为两个都是开头位置,所以相同. 2.看下 ...
- Windows PE变形练手2-开发一套自己的PE嵌入模板
PE嵌入模板 编写一段代码,生成一个已经处理过重定位信息,同时所有的内容都在代码段里,并且没有导入表的PE程序,把这个程序嵌入到其他PE的相关位置,能够独立的运行,接下来是整理了2个模板,一个是Hel ...
- layui select 动态赋值
出现问题 赋值完成后页面不显示,没有效果 发现问题 赋值完成后需要重新渲染select 解决问题 form.render('select');