Python基础之:struct和格式化字符
简介
文件的存储内容有两种方式,一种是二进制,一种是文本的形式。如果是以文本的形式存储在文件中,那么从文件中读取的时候就会遇到一个将文本转换为Python中数据类型的问题。实际上即使是文本的形式存储,存储的数据也是也是有结构的,因为Python底层是用C来编写的,这里我们也称之为C结构。
Lib/struct.py 就是负责进行这种结构转换的模块。
struct中的方法
先看下struct的定义:
__all__ = [
# Functions
'calcsize', 'pack', 'pack_into', 'unpack', 'unpack_from',
'iter_unpack',
# Classes
'Struct',
# Exceptions
'error'
]
其中有6个方法,1个异常。
我们主要来看这6个方法的使用:
| 方法名 | 作用 |
|---|---|
| struct.pack(format, v1, v2, ...) | 返回一个 bytes 对象,其中包含根据格式字符串 format 打包的值 v1, v2, ... 参数个数必须与格式字符串所要求的值完全匹配。 |
| struct.pack_into(format, buffer, offset, v1, v2, ...) | 根据格式字符串 format 打包 v1, v2, ... 并将打包的字节串从 offset 开始的位置写入可写缓冲区 buffer 。 请注意 offset 是必需的参数。 |
| struct.unpack(format, buffer) | 根据格式字符串 format 从缓冲区 buffer 解包(假定是由 pack(format, ...) 打包)。 返回的结果为一个元组,即使其只包含一个条目。 缓冲区的字节大小必须匹配格式所要求的大小。 |
| struct.unpack_from(format, /, buffer, offset=0) | 从位置 offset 开始对 buffer 根据格式字符串 format 进行解包。 结果为一个元组,即使其中只包含一个条目。 |
| struct.iter_unpack(format, buffer) | 根据格式字符串 format 以迭代方式从缓冲区 buffer 解包。 此函数返回一个迭代器,它将从缓冲区读取相同大小的块直至其内容全部耗尽。 |
| struct.calcsize(format) | 返回与格式字符串 format 相对应的结构的大小(亦即 pack(format, ...) 所产生的字节串对象的大小)。 |
这些方法主要就是打包和解包的操作,其中一个非常重要的参数就是format,也被成为格式字符串,它指定了每个字符串被打包的格式。
格式字符串
格式字符串是用来在打包和解包数据时指定数据格式的机制。 它们使用指定被打包/解包数据类型的 格式字符 进行构建。 此外,还有一些特殊字符用来控制 字节顺序,大小和对齐方式。
字节顺序,大小和对齐方式
默认情况下,C类型以机器的本机格式和字节顺序表示,并在必要时通过填充字节进行正确对齐(根据C编译器使用的规则)。
我们也可以手动指定格式字符串的字节顺序,大小和对齐方式:
| 字符 | 字节顺序 | 大小 | 对齐方式 |
|---|---|---|---|
@ |
按原字节 | 按原字节 | 按原字节 |
= |
按原字节 | 标准 | 无 |
< |
小端 | 标准 | 无 |
> |
大端 | 标准 | 无 |
! |
网络(=大端) | 标准 | 无 |
大端和小端是两种数据存储方式。
第一种Big Endian将高位的字节存储在起始地址

第二种Little Endian将地位的字节存储在起始地址
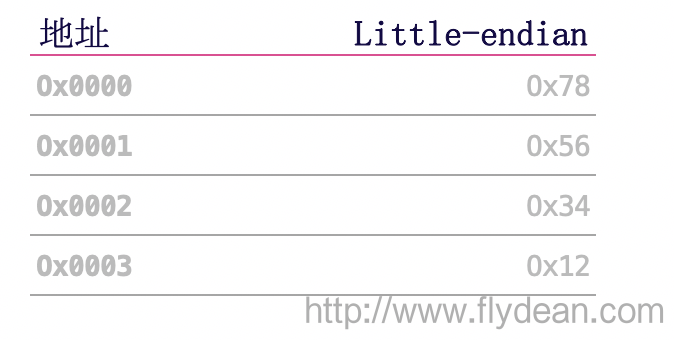
其实Big Endian更加符合人类的读写习惯,而Little Endian更加符合机器的读写习惯。
目前主流的两大CPU阵营中,PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。
如果不同的CPU架构直接进行通信,就由可能因为读取顺序的不同而产生问题。
填充只会在连续结构成员之间自动添加。 填充不会添加到已编码结构的开头和末尾。
当使用非原字节大小和对齐方式即 '<', '>', '=', and '!' 时不会添加任何填充。
格式字符
我们来看下字符都有哪些格式:
| 格式 | C 类型 | Python 类型 | 标准大小(字节) |
|---|---|---|---|
x |
填充字节 | 无 | |
c |
char |
长度为 1 的字节串 | 1 |
b |
signed char |
整数 | 1 |
B |
unsigned char |
整数 | 1 |
? |
_Bool |
bool | 1 |
h |
short |
整数 | 2 |
H |
unsigned short |
整数 | 2 |
i |
int |
整数 | 4 |
I |
unsigned int |
整数 | 4 |
l |
long |
整数 | 4 |
L |
unsigned long |
整数 | 4 |
q |
long long |
整数 | 8 |
Q |
unsigned long long |
整数 | 8 |
n |
ssize_t |
整数 | |
N |
size_t |
整数 | |
e |
(6) | 浮点数 | 2 |
f |
float |
浮点数 | 4 |
d |
double |
浮点数 | 8 |
s |
char[] |
字节串 | |
p |
char[] |
字节串 | |
P |
void * |
整数 |
格式数字
举个例子,比如我们要打包一个int对象,我们可以这样写:
In [101]: from struct import *
In [102]: pack('i',10)
Out[102]: b'\n\x00\x00\x00'
In [103]: unpack('i',b'\n\x00\x00\x00')
Out[103]: (10,)
In [105]: calcsize('i')
Out[105]: 4
上面的例子中,我们打包了一个int对象10,然后又对其解包。并且计算了 i 这个格式的长度为4字节。
大家可以看到输出结果是 b'\n\x00\x00\x00' ,这里不去深究这个输出到底是什么意思,开头的b表示的是byte,后面是byte的编码。
格式字符之前可以带有整数重复计数。 例如,格式字符串 '4h' 的含义与 'hhhh' 完全相同。
看下如何打包4个short类型:
In [106]: pack('4h',2,3,4,5)
Out[106]: b'\x02\x00\x03\x00\x04\x00\x05\x00'
In [107]: unpack('4h',b'\x02\x00\x03\x00\x04\x00\x05\x00')
Out[107]: (2, 3, 4, 5)
格式之间的空白字符会被忽略,但如果是struct.calcsize 方法的话格式字符中不可有空白字符。
当使用某一种整数格式 ('b', 'B', 'h', 'H', 'i', 'I', 'l', 'L', 'q', 'Q') 打包值 x 时,如果 x 在该格式的有效范围之外则将引发 struct.error。
格式字符
除了数字之外,最常用的就是字符和字符串了。
我们先看下怎么使用格式字符,因为字符的长度是1个字节,我们需要这样做:
In [109]: pack('4c',b'a',b'b',b'c',b'd')
Out[109]: b'abcd'
In [110]: unpack('4c',b'abcd')
Out[110]: (b'a', b'b', b'c', b'd')
In [111]: calcsize('4c')
Out[111]: 4
字符前面的b,表示这是一个字符,否则将会被当做字符串。
格式字符串
再看下字符串的格式:
In [114]: pack('4s',b'abcd')
Out[114]: b'abcd'
In [115]: unpack('4s',b'abcd')
Out[115]: (b'abcd',)
In [116]: calcsize('4s')
Out[116]: 4
In [117]: calcsize('s')
Out[117]: 1
可以看到对于字符串来说calcsize返回的是字节的长度。
填充的影响
格式字符的顺序可能对大小产生影响,因为满足对齐要求所需的填充是不同的:
>>> pack('ci', b'*', 0x12131415)
b'*\x00\x00\x00\x12\x13\x14\x15'
>>> pack('ic', 0x12131415, b'*')
b'\x12\x13\x14\x15*'
>>> calcsize('ci')
8
>>> calcsize('ic')
5
下面的例子我们将会展示如何手动影响填充效果:
In [120]: pack('llh',1, 2, 3)
Out[120]: b'\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00'
上面的例子中,我们打包1,2,3这三个数字,但是格式不一样,分别是long,long,short。
因为long是4个字节,short是2个字节,所以本质上是不对齐的。
如果想要对齐,我们可以在后面再加上 0l 表示0个long,从而进行手动填充:
In [118]: pack('llh0l', 1, 2, 3)
Out[118]: b'\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00'
In [122]: unpack('llh0l',b'\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00')
Out[122]: (1, 2, 3)
复杂应用
最后看一个复杂点的应用,这个应用中直接从unpack出来的数据读取到元组中:
>>> record = b'raymond \x32\x12\x08\x01\x08'
>>> name, serialnum, school, gradelevel = unpack('<10sHHb', record)
>>> from collections import namedtuple
>>> Student = namedtuple('Student', 'name serialnum school gradelevel')
>>> Student._make(unpack('<10sHHb', record))
Student(name=b'raymond ', serialnum=4658, school=264, gradelevel=8)
本文已收录于 http://www.flydean.com/13-python-struct-format-char/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
Python基础之:struct和格式化字符的更多相关文章
- python基础语法、数据结构、字符编码、文件处理 练习题
考试范围 '''1.python入门:编程语言相关概念2.python基础语法:变量.运算符.流程控制3.数据结构:数字.字符串.列表.元组.字典.集合4.字符编码5.文件处理''' 考试内容 1.简 ...
- python基础之 while 逻辑运算符 格式化输出等
1.while循环 while 条件: 循环体 while 条件: 循环体 else: 循环体 重点: 当条件为真的时候,就进入循环体,从上到下依次执行,执行完最后一条语句时,while并不是直接退出 ...
- Python基础【day03】:字符转编码操作(五)
本节内容 1.编码介绍 2.字符编码介绍 3.总结 说到python的编码,一句话总结,说多了都是泪啊,这个在以后的python的开发中绝对是一件令人头疼的事情.所以有必要要讲讲清楚 一.编码介绍 1 ...
- 学习PYTHON之路, DAY 5 - PYTHON 基础 5 (装饰器,字符格式化,递归,迭代器,生成器)
---恢复内容开始--- 一 装饰器 1 单层装饰器 def outer(func): def inner(): print('long') func() print('after') return ...
- python基础(7):字符编码
今天我们进入字符编码的学习.字符编码是一个多理论少结论的知识点,我会总结很多的知识点.我们只需要通读当作了解即可,最后我会总结需要我们理解掌握的重点. 一.学习字符编码的计算机基础储备 1.计算机软件 ...
- Python基础【day02】:字符编码(一)
本节内容 1.字符编码与转码 1.关于中文2.注释3.转码 2.表达式for 循环 3.数据类型之数字 1.数字2.布尔值3.字符串4.列表5.元祖6.字典 一.字符编码与转码 python解释器在加 ...
- python基础--程序交互、格式化输出、流程控制、break、continue
在此申明一下,博客参照了https://www.cnblogs.com/jin-xin/,自己做了部分的改动 (1) 程序交互 #!/usr/bin/env python # -*- coding: ...
- python基础之循环语句,格式化输出以及编码
1.while循环语句 1.1 常见的几种结构 1. while+判断条件 循环体 2. while+判断条件 循环体 else 语句 tips:while循环如果满足条件的话,会一直循环循环体 ...
- python基础知识梳理----2格式化输出,替换符
一:格式化输出 1: 格式: 例子: name=input('请输入name') print('名字是%s'%name) %s就是代表字符串串占位符,除此之外,还有%d, 是数字占位符, 如果把上⾯面 ...
随机推荐
- qt char与code的相互转换
QString str = "A"; QChar c = str.at(0); // int v_latin = c.toLatin1(); // 不能转中文 int v_lati ...
- 精密进近OAS面的绘制与评估
一.定义:精密进近OAS面(Obstacle Assessment Surface 障碍物评价面)是在精密进近程序中,用来对障碍物进行评估,找出影响运行标准的控制障碍物的一种计算方法. 二.构成 OA ...
- (转)linux下的系统调用函数到内核函数的追踪
转载网址:http://blog.csdn.net/maochengtao/article/details/23598433 使用的 glibc : glibc-2.17使用的 linux kerne ...
- java自学第4期——:Scanner类、匿名对象介绍、Random类、ArrayList集合、标准类格式、String类、static静态、Arrays工具类、Math类(1)
一.Scanner类 1.api简介: 应用程序编程接口 2.Scanner类: 作用:获取键盘输入的数据 位置: java.util.Scanner. 使用:使用成员方法nextInt() 和 ne ...
- iOS拍照定制之AVCaptureVideoDataOutput
问题 领导看了前面做的拍照,问了句"哪来的声音", "系统的,自带的,你看系统的拍照也有声音" "有办法能去掉吗?挺糟心的" "我 ...
- CVer想知道的都在这里了,一起分析下《中国计算机视觉人才调研报告》吧!
最近闲来无事,老潘以一名普通算法工程师的角度,结合自身以及周围人的情况,理性也感性地分析一下极市平台前些天发布的2020年度中国计算机视觉人才调研报告. 以下的"计算机视觉人才"简 ...
- Django Admin 图片路径设置显示为图片(imageField显示方法设置)
一 使用环境 开发系统: windows IDE: pycharm 数据库: msyql,navicat 编程语言: python3.7 (Windows x86-64 executable in ...
- MySQL如何搭建主库从库(Docker)
目录 MySQL主从搭建 一.主从配置原理 二.操作步骤 1.创建主库和从库容器 2.启动主从库容器 3.远程连接并操作主从库 4.测试主从同步 MySQL主从搭建 一.主从配置原理 mysql主从配 ...
- Redis数据结构和对象三
1.Redis 对象系统 Redis用到的所有主要数据结构,简单动态字符串(SDS).双端链表.字典.压缩列表.整数集合.跳跃表. Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些 ...
- (三)MySQL锁机制 + 事务
转: (三)MySQL锁机制 + 事务 表锁(偏读) 偏向MyISAM存储引擎.开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发最低. 查看当前数据库中表的上锁情况,0表示未上锁. sh ...