K8S日志接入sls配置
背景
原有日志方案查询日志很不方便且效率低,而且也不支持基于日志的高级操作。如:聚合,图形展示,关键字检测等。
方案
接入阿里云的sls日志服务。
实施
1、通过环境变量进行日志接入
配置如下:
| 字段 | 说明 | 示例 | 注意事项 |
|---|---|---|---|
| aliyun_logs_{key} | - 必选项。{key}只能包含小写字母、数字和-。 - 若不存在aliyun_logs_{key}_logstore,则默认创建并采集到名为{key}的logstore。 - 当值为stdout表示采集容器的标准输出;其他值为容器内的日志路径。 |
- name: aliyun_logs_catalina stdout - name: aliyun_logs_access-log /var/log/nginx/access.log |
- 默认采集方式为极简模式,如需解析日志内容,建议使用日志服务控制台并参见通过DaemonSet-控制台方式采集Kubernetes文件、通过DaemonSet-控制台方式采集Kubernetes标准输出或通过DaemonSet-CRD方式采集日志进行配置。 - {key}需保持在K8s集群内唯一。 |
| aliyun_logs_{key}_tags | 可选。值为{tag-key}={tag-value}类型,用于对日志进行标识。 | - name: aliyun_logs_catalina_tags app=catalina |
- |
| aliyun_logs_{key}_project | 可选。值为指定的日志服务Project。当不存在该环境变量时为您安装时所选的Project。 | - name: aliyun_logs_catalina_project my-k8s-project |
Project需与您的Logtail工作所在Region一致。 |
| aliyun_logs_{key}_logstore | 可选。值为指定的日志服务Logstore。当不存在该环境变量时Logstore和{key}一致。 | - name: aliyun_logs_catalina_tags my-logstore |
- |
| aliyun_logs_{key}_shard | 可选。值为创建Logstore时的shard数,有效值为1~10。当不存在该环境变量时值为2。 | - name: aliyun_logs_catalina_shard 4 |
- |
| aliyun_logs_{key}_ttl | 可选。值为指定的日志保存时间,有效值为1~3650。 - 当取值为3650时,指定日志的保存时间为永久保存。 - 当不存在该环境变量时,默认指定日志的保存时间为90天。 |
- name: aliyun_logs_catalina_ttl 3650 |
- |
| aliyun_logs_{key}_machinegroup | 可选。值为应用的机器组。当不存在该环境变量时与安装Logtail的默认机器组一致。 | - name: aliyun_logs_catalina_machinegroup my-machine-group |
- |
优点:配置简单,不容易出现问题。
缺点:无法使用logtail的高级功能,如regex,geoip,split等操作。
2、通过CRD进行配置
配置如下(以daemon为例):
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: daemon-log
spec:
logstore: applog
project: pre-app-log
logtailConfig:
# log file's input type is 'file'
inputType: file
# logtail config name, should be same with [metadata.name]
configName: daemon-log
inputDetail:
logType: common_reg_log
advanced:
blacklist:
dir_blacklist: ["/data/logs/dump", "/data/logs/*/xxljob", "/data/logs/*/apm"]
filepath_blacklist: []
logPath: /data/logs/daemon
filePattern: "*.log"
dockerIncludeEnv:
PROJECTID: "d0"
dockerExcludeEnv: {}
dockerFile: true
logBeginRegex: '\d+-\d+-\d+\s\d+:\d+:\d+[,|\.|\s].*'
配置过程中遇到两个问题:
1、配置通用收集配置的时候:云上K8S收集应用日志的时候出现了tag开头的字段获取到的pod_name,container_name等都是一个ds的信息,不是原有pod的信息。
示例图如下:

原因:
由于挂载的是宿主机路径,在配置logtail配置文件的时候应用pod的/data/logs是docker的overlayfs的路径,只配置到这一层的话,logtail只在docker的overlayfs文件系统中搜索/data/logs/**/*.log,这样无法找到我们的/data/logs/的文件夹下日志。
当挂载了一个子目录(用hostpath),配置的是父目录采集(在 docker默认目录overlayfs),在docker里面会认为你要采集的是 overlayfs。
所以此时我们无法进行正常的日志采集,所有的日志都是来自于logcleanpre挂载的/data/logs内部。
解决办法:
i、修改我们的挂载方式:宿主机上的/var/lib/docker/logs/挂载到/data/logs,logcleanpre也需要改造。
ii、每个应用pod配置一个logtail的CRD配置。(目前通过这种方式处理)
2、增加logBeginRegex或者regex,会导致页面刷新有告警。但是在控制台操作的时候正则验证和解析都是正常的而且日志也是按照正则正确的收集进来的。
示例图如下:
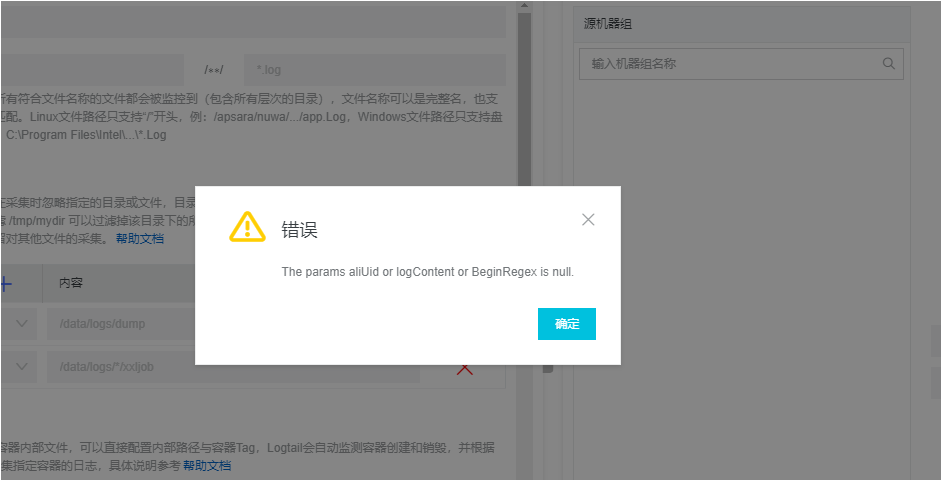
问题已被阿里云收录,但是暂未解决(2020.10.23)。
优点:配置灵活,基本能满足对日志处理的全部操作。
缺点:配置文档不完整,容易踩坑。
K8S日志接入sls配置的更多相关文章
- 消费阿里云日志服务SLS
此文档只关心消费接入,不关心日志接入,只关心消费如何接入,可直接跳转到[sdk消费接入] SLS简介 日志服务: 日志服务(Log Service,简称 LOG)是针对日志类数据的一站式服务,在阿里巴 ...
- 一文看懂 K8s 日志系统设计和实践
上一篇中我们介绍了为什么需要一个日志系统.为什么云原生下的日志系统如此重要以及云原生下日志系统的建设难点,相信DevOps.SRE.运维等同学看了是深有体会的.本篇文章单刀直入,会直接跟大家分享一下如 ...
- 【阿里云产品公测】简单日志服务SLS使用评测 + 教程
[阿里云产品公测]简单日志服务SLS使用评测 + 教程 评测介绍 被测产品: 简单日志服务SLS 评测环境: 阿里云基础ECS x2(1核, 512M, 1M) 操作系统: CentOS 6.5 x6 ...
- k8s日志收集方案
k8s日志收集方案 三种收集方案的优缺点: 下面我们就实践第二种日志收集方案: 一.安装ELK 下面直接采用yum的方式安装ELK(源码包安装参考:https://www.cnblogs.com/De ...
- ELK日志系统之通用应用程序日志接入方案
前边有两篇ELK的文章分别介绍了MySQL慢日志收集和Nginx访问日志收集,那么各种不同类型应用程序的日志该如何方便的进行收集呢?且看本文我们是如何高效处理这个问题的 日志规范 规范的日志存放路径和 ...
- k8s 日志收集之 EFK
如今越来越多的应用部署在容器之中,如何收集日志也是一个很重要的问题.服务出问题了,排查问题需要给开发看日志.服务一般会在多个不同的 pod 中,一个一个的登进去看也的确不方便.业务数据统计也需要日志. ...
- 4.2 K8S超级完整安装配置
前言: 采坑 k8s有3种安装方式,如下所示: minikube:这是一个k8s集群模拟器,只有一个节点的集群,只为了测试使用,master和node都在一台机器上 直接使用带有容器功能的云平台安装: ...
- ansble通过脚本定时清理k8s日志
环境:环境k8s1.17,ansble通过脚本定时清理k8s日志 [root@tidb-21 delete-k8s-logs]# lsansib-delete.sh delete-logs.sh [r ...
- 如何在 ETL 项目中统一管理上百个 SSIS 包的日志和包配置框架
一直准备写这么一篇有关 SSIS 日志系统的文章,但是发现很难一次写的很完整.因为这篇文章的内容可扩展的性太强,每多扩展一部分就意味着需要更多代码,示例和理论支撑.因此,我选择我觉得比较通用的 LOG ...
随机推荐
- js--你需要知道的字符串使用方法(含es6及之后)
前言 字符串作为 JavScript 的基本数据类型,在开发以及面试过程中作为程序员对基础掌握情况的重要考点,本文来总结一下字符串的相关属性以及用法.包含了ES6中的一些新语法特性. 正文 1.字符串 ...
- mongodb数据的导出导入
1.[导出]mongoexport -h (主机名) -d (库) -c (集合名) -o (路径) -u (账号) -p (密码)示例:mongoexport -h localhost -d jav ...
- 严重:Exception sending context initialized event to listener instance of class [myJava.MyServletContextListener] java.lang.NullPointerException
以上错误是我在自定义Servlet监听器时遇到的,首先大致介绍一下我要实现的功能(本人刚开始学,如有错误,请多多指正): 为了统计网站访问量,防止服务器重启后,原访问次数被清零,因此自定义监听器类,实 ...
- 63. Unique Paths II 动态规划
description: https://leetcode.com/problems/unique-paths/ 机器人从一堆方格的左上角走到右下角,只能往右或者往下走 ,问有几种走法,这个加了难度, ...
- FreeRTOS基本概念
1.在FreeRTOS中,使用的数据类型虽然都是标准C里面的数据类型,但是针对不同的处理器,对标准C的数据类型又进行了重新定义. 2.链表由节点组成,节点与节点之间首尾相连,节点包含用于指向后一个节点 ...
- FastTunnel-内网穿透原理揭秘
之前写了一篇关于GVP开源项目FastTunnel的一篇介绍 <FastTunnel-开源内网穿透框架>,只简单介绍了使用方法,不少伙伴对其原理表示好奇,今天画抽空了一下其内部实现原理流程 ...
- 通过原生js实现数据的双向绑定
通过js实现数据的双向绑定 : Object.defineProperty了解 语法: Object.defineProperty(obj, prop, descriptor) obj 要定义属性的对 ...
- F5负载均衡_monitors(健康检查)
故障现象: 后端有5台服务器,每个服务器上跑着8个应用.使用F5做应用负载调度.这40个应用里面,3-10个应用在高峰期的时候weblogic的DOS窗口显示与数据库断开连接(端口通.业务断),但是F ...
- python chrome
from selenium.webdriver.chrome.options import Options from selenium import webdriver wd = webdriver. ...
- bootstrap栅格布局-v客学院知识分享
今天主要跟大家讲解下bootstrap的栅格布局,以及使用过程中应该注意的问题 首先我们要使用bootstrp的栅格布局就必须使用HTML正确的基本结构 如下图: 必须给要使用栅格布局的盒子定义cla ...