CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建
前期准备
1.配置hostname(可选,了解)
在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(pretty)。“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。而另一方面,“灵活”主机名则允许使用自由形式(包括特殊/空白字符)的主机名,以展示给终端用户(如Linuxidc)。
在CentOS7以前,配置主机的静态hostname是在/etc/sysconfig/network中配置HOSTNAME字段值来配置,而CentOS7之后若要配置静态的hostname是需要在/etc/hostname中进行。
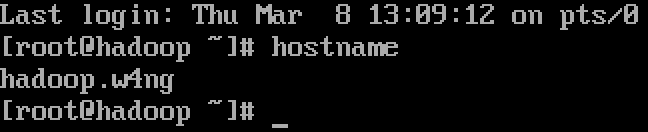
进入Linux系统,命令行下输入hostname可以看到当前的hostname,而通常默认的hostname是local.localadmin。
本次试验环境在CentOS7下,所以我们编辑/etc/hostname文件,试验hostname为:hadoop.w4ng,填入其中,重启Linux,可以看到已经生效。
2.配置静态IP
同样,在CentOS7以后,其网卡配置已经有原先的/etc/sysconfig/network/network-scripts下面的ifcfg-eth0等改名为乐ifcfg-enpXsY(en表示ethnet,p表示pci设备,s表示soket)

本人这里有两个ifcfg文件是因为配置了两块网卡分别做NAT以及与虚拟机Host-Only两个功能,实现双网卡上网
打开ifcfg-enp0s8,配置如下:
DEVICE=enp0s8 #设备名
HWADDR=08:00:27:10:6B:6B #硬件地址
TYPE=Ethernet #类型
BOOTPROTO=static #静态IP(必备)
IPADDR=192.168.56.88 #IP地址
NETMASK=255.255.255.0 #子网掩码
ONBOOT=yes #设备开机自动启动该网卡
3.配置hosts
打开/etc/hosts
配置为如下的:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.88 hadoop.w4ng
配置hosts的理由是后期hadoop配置中相关的主机填写我们都是使用域名的形式,而IP地址与域名的转换在这里进行查询(还有DNS,但是这里不讨论)。
4.关闭防火墙
CentOS7与6的防火墙不一样。在7中使用firewall来管理防火墙,而6是使用iptables来进行管理的。当然,我们可以卸载7的firewall安装6的iptables来管理。本人就切换回了6的防火墙管理方式。
[root@localhost ~]#servcie iptables stop # 临时关闭防火墙
[root@localhost ~]#chkconfig iptables off # 永久关闭防火墙
5.JDK与Hadoop的安装
下载JDK8
下载Hadoop3-binary
下载完毕将文件传到主机中。
在/usr/local/下创建java文件夹,并将JDK解压至该文件夹下。
在根目录下创建/bigdata文件夹,并将Hadoop解压至其中。
解压命令 tar -zxv -f [原压缩文件.tar.gz] -C [目标文件夹目录] # 实际命令没有中括号,其次,命令参数重-z对应gz压缩文件,若为bz2则使用-j
在JDK解压完成后,在~/.bash_profile中配置环境变量 点这里看/etc/bashrc、/.bashrc、/.bash_profile关系
export JAVA_HOME=/usr/local/java/jdkx.x.x_xxx
export PATH=$PATH:$JAVA_HOME/bin
配置完成,保存退出并 source ~/.bash_profile
hadoop无需配置环境变量
6.配置hadoop
在hadoop的home下,进入etc文件夹,有五个主要的文件需要进行配置:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
基本配置如下
1.配置 hadoop-env.sh
export JAVA_HOME
#找到该处,填写上上面配置的JAVA_HOME,因为hadoop是基于Java的,需要Java的环境
2.配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostnameXXX:9000</value>
</property>
<!-- 配置hadoop文件系统目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigData/tmp</value>
</property>
</configuration>
3.配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.配置 yarn-site.xml
<configuration>
<property>
<name>yarn.resourecemanager.hostname</name>
<value>hostnameXXX</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
然后配置相关服务启动过程中需要的配置变量:
进入${HADOOP_HOME}/sbin中,在start-dfs.sh与stop-dfs.sh中添加字段:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh与stop-yarn.sh中添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置完成以后,进行hadoop的文件系统格式化,执行
${HADOOP_HOME}/bin/hdfs namenode -format
最后是启动服务:
执行${HADOOP_HOME}/sbin/start-all.sh # 他会去调用start-dfs.sh与start-yarn.sh
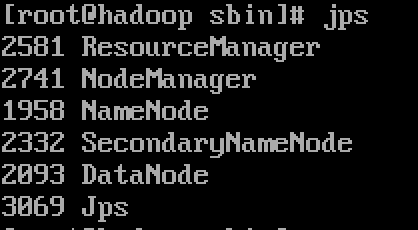
根据配置中我们都是配置的root用户,显然需要我们以root身份进行,且过程中需要root密码。当然,通过ssh免密可以方便很多。启动完成以后,命令行中使用jps命令打印Java进程,会看到下图五个进程(忽略Jps进程):
当然,Hadoop在服务启动以后以提供web端:
visit hdfs manage page
xxx.xxx.xxx.xxx:50070
visit yarn manage page
xxx.xxx.xxx.xxx:8088
CentOS7下Hadoop伪分布式环境搭建的更多相关文章
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- 007 linux环境下的伪分布式环境搭建
本文的配置环境是VMware10+centos2.5. 在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验. 如果感觉有问题,欢迎咨询评论. 零:下 ...
- Hadoop伪分布式环境搭建+Ubuntu:16.04+hadoop-2.6.0
Hello,大家好 !下面就让我带大家一起来搭建hadoop伪分布式的环境吧!不足的地方请大家多交流.谢谢大家的支持 准备环境: 1, ubuntu系统,(我在16.04测试通过.其他版本请自行测试, ...
- linux环境下的伪分布式环境搭建
本文的配置环境是VMware10+centos2.5. 在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验. 如果感觉有问题,欢迎咨询评论. 一:伪 ...
- hadoop伪分布式环境搭建
环境:Centos6.9+jdk+hadoop1.下载hadoop的tar包,这里以hadoop2.6.5版本为例,下载地址https://archive.apache.org/dist/hadoop ...
- hadoop伪分布式环境搭建之linux系统安装教程
本篇文章是接上一篇<超详细hadoop虚拟机安装教程(附图文步骤)>,上一篇有人问怎么没写hadoop安装.在文章开头就已经说明了,hadoop安装会在后面写到,因为整个系列的文章涉及到每 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
随机推荐
- Linux基础——用户和用户组
Linux基础--用户和用户组 一.用户和用户组 用户在/etc/passwd中 用户组在/etc/group/中注意:在创建用户时,系统默认生成一个用户组(组名和用户名一致) 1.用户 1.1查看用 ...
- OKR工作法读后感
<OKR工作法>把管理思想融入到一则创业故事中,故事细节经过了精心的设计,融入了管理智慧和踩坑填坑经验,每个细节都以小见大,耐人寻味.一千个读者,就有一千个哈姆雷特. 所以这次我不去点评大 ...
- java 查询当天0点0分0秒
由于业务需求,要计算客户今日收益,本周本月,本年等收益, 1.查询当天0点0分0秒 2.查询本月一号0点0分0秒 ...... Calendar calendar = Calendar.getInst ...
- Mybatis原理和代码剖析
参考资料(官方) Mybatis官方文档: https://mybatis.org/mybatis-3/ Mybatis-Parent : https://github.com/mybatis/par ...
- vue js 手写 正则判断 手机号码 和 密码
const phoneOrEmails = /^1[3|4|5|6|7|8|9][0-9]\d{8}$/ if(this.ruleForms.phoneOrEmail == ...
- springMVC学习总结(三) --springMVC重定向
根据springMVC学习总结(一) --springMVC搭建搭建项目 在com.myl.controller包下创建一个java类WebController. 在jsp子文件夹下创建一个视图文件i ...
- C# 爬虫框架实现 流程_各个类开发
目录链接:C# 爬虫框架实现 概述 对比通用爬虫结构,我将自己写的爬虫分为五个类实现: Spider主类:负责设置爬虫的各项属性 Scheduler类:负责提供URL到下载类,接收URL并做去重 Do ...
- 痞子衡嵌入式:MCUXpresso IDE下将应用程序RW段分散链接的几种方法
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MCUXpresso IDE下将应用程序RW段分散链接的几种方法. 早期的 MCU 芯片,一般都会嵌入内部 Flash 和 RAM,并且 ...
- C#新版本风格(NetCore)项目文件
在VisualStudio中创建NetCore以上版本的项目,使用的都是新版本风格的项目文件. 和旧版本.NetFramework版本的项目文件区别: 双击项目可直接打开csproj文件进行编辑配置 ...
- shp平滑处理
在做图像数据处理时,经常会有栅格数据转矢量数据的操作,转换后的矢量文件会存在锯齿状边缘,不太美观,因此常常需要对矢量(shp)文件做平滑处理. 1 利用arcgis实现shp的平滑和简化 ArcToo ...