fasthttp:比net/http快十倍的Go框架(server 篇)
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/574
我们在上一篇文章中讲解了 Go HTTP 标准库的实现原理,这一次我找到了一个号称比net/http快十倍的Go框架 fasthttp,这次我们再来看看它有哪些优秀的设计值得我们去挖掘。
一个典型的 HTTP 服务应该如图所示:
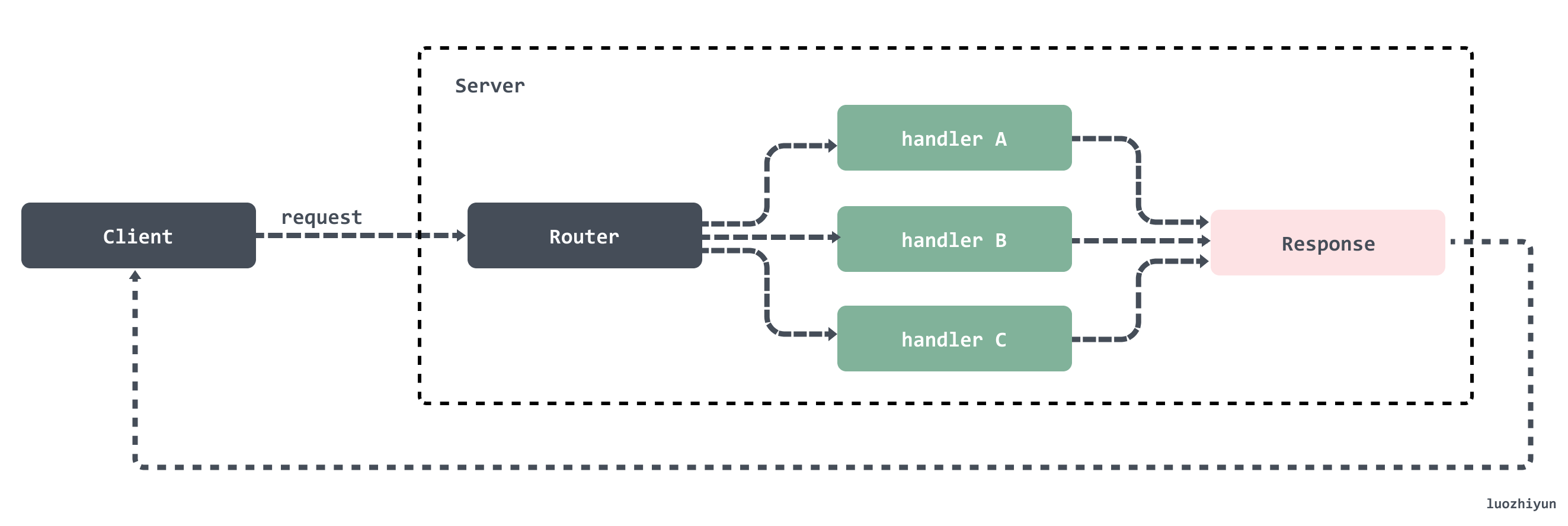
基于HTTP构建的服务标准模型包括两个端,客户端(Client)和服务端(Server)。HTTP 请求从客户端发出,服务端接受到请求后进行处理然后将响应返回给客户端。所以http服务器的工作就在于如何接受来自客户端的请求,并向客户端返回响应。
这篇我们来讲讲 Server 端的实现。
实现原理
net/http 与 fasthttp 实现对比
我们在讲 net/http 的时候讲过,它的处理流程大概是这样的:
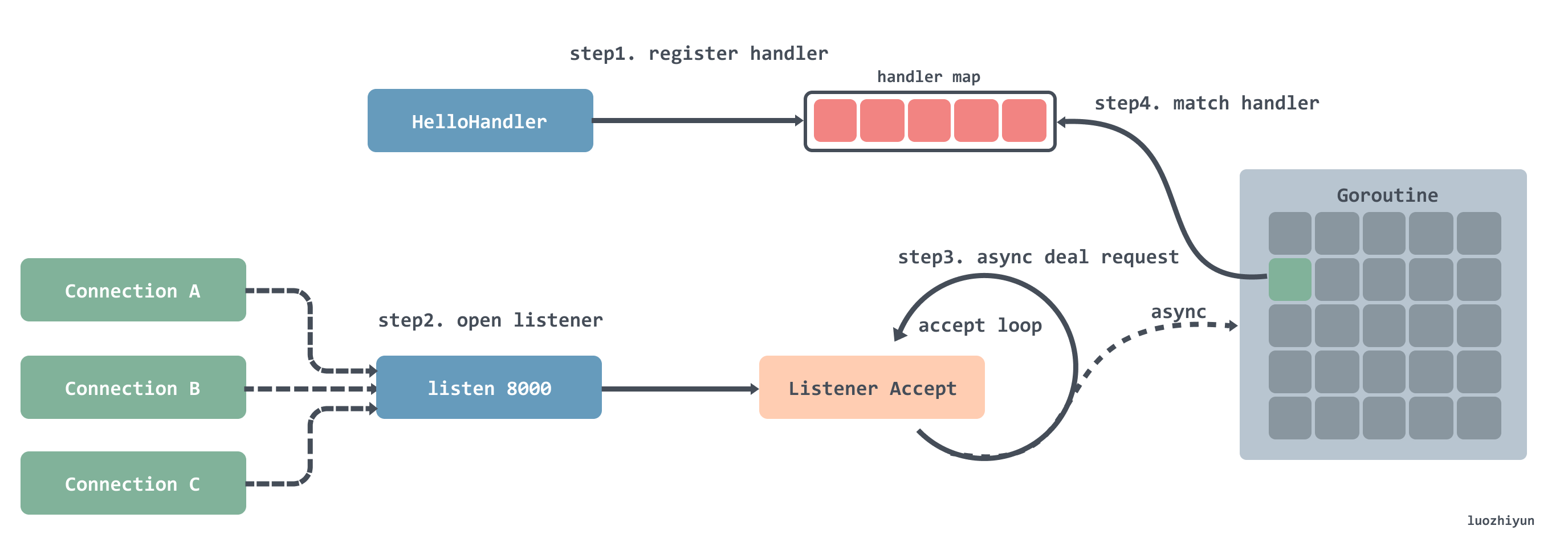
- 注册处理器到一个 hash 表中,可以通过键值路由匹配;
- 注册完之后就是开启循环监听,每监听到一个连接就会创建一个 Goroutine;
- 在创建好的 Goroutine 里面会循环的等待接收请求数据,然后根据请求的地址去处理器路由表中匹配对应的处理器,然后将请求交给处理器处理;
这样做在连接数比较少的时候是没什么问题的,但是在连接数非常多的时候,每个连接都会创建一个 Goroutine 就会给系统带来一定的压力。这也就造成了 net/http在处理高并发时的瓶颈。
下面我们再看看 fasthttp 是如何做的:
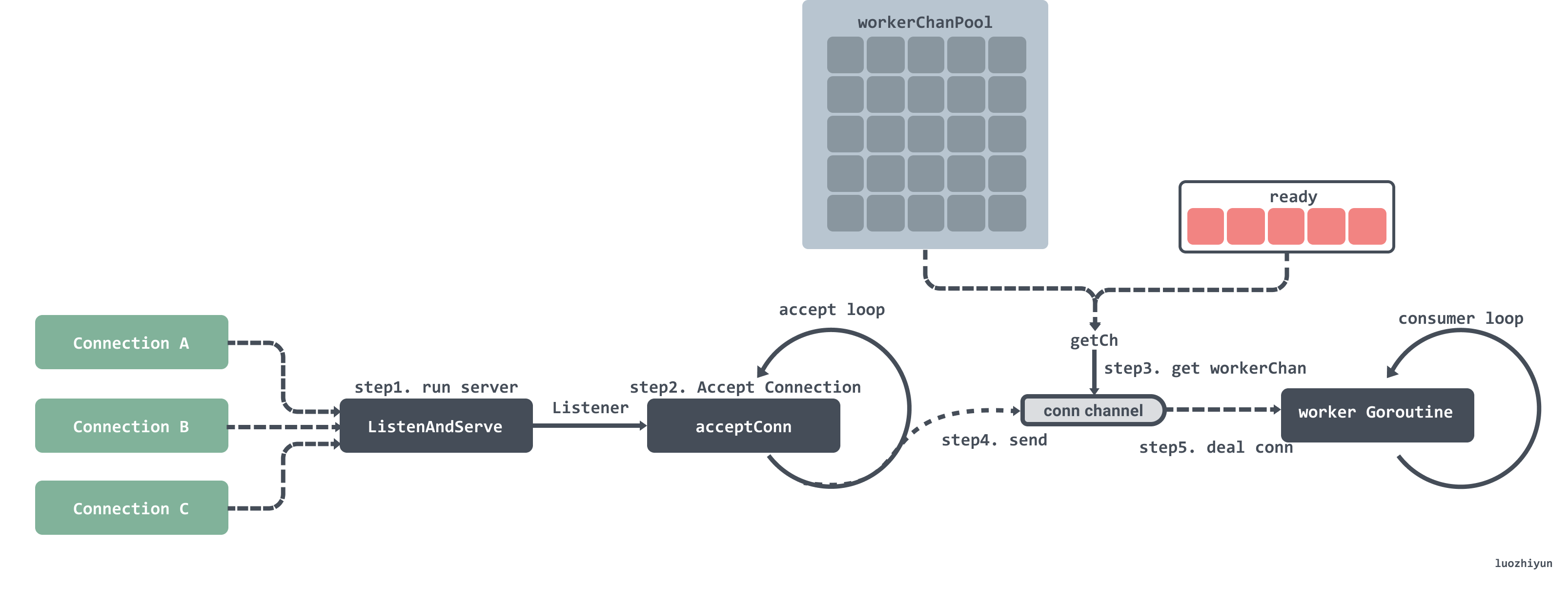
- 启动监听;
- 循环监听端口获取连接;
- 获取到连接之后首先会去 ready 队列里获取 workerChan,获取不到就会去对象池获取;
- 将监听的连接传入到 workerChan 的 channel 中;
- workerChan 有一个 Goroutine 一直循环获取 channel 中的数据,获取到之后就会对请求进行处理然后返回。
上面有提到 workerChan 其实就是一个连接处理对象,这个对象里面有一个 channel 用来传递连接;每个 workerChan 在后台都会有一个 Goroutine 循环获取 channel 中的连接,然后进行处理。如果没有设置最大同时连接处理数的话,默认是 256 * 1024个。这样可以在并发很高的时候还可以同时保证对外提供服务。
除此之外,在实现上还通过 sync.Pool 来大量的复用对象,减少内存分配,如:
workerChanPool 、ctxPool 、readerPool、writerPool 等等多大30多个 sync.Pool 。
除了复用对象,fasthttp 还会切片,通过 s = s[:0]和 s = append(s[:0], b…)来减少切片的再次创建。
fasthttp 由于需要和 string 打交道的地方很多,所以还从很多地方尽量的避免[]byte到string转换时带来的内存分配和拷贝带来的消耗 。
小结
综上我们大致介绍了一下 fasthttp 提升性能的点:
- 控制异步 Goroutine 的同时处理数量,最大默认是
256 * 1024个; - 使用 sync.Pool 来大量的复用对象和切片,减少内存分配;
- 尽量的避免
[]byte到string转换时带来的内存分配和拷贝带来的消耗 ;
源码解析
我们以一个简单的例子作为开始:
func main() {
if err := fasthttp.ListenAndServe(":8088", requestHandler); err != nil {
log.Fatalf("Error in ListenAndServe: %s", err)
}
}
func requestHandler(ctx *fasthttp.RequestCtx) {
fmt.Fprintf(ctx, "Hello, world!\n\n")
}
我们调用 ListenAndServe 函数会启动服务监听,等待任务进行处理。ListenAndServe 函数实际上会调用到 Server 的 ListenAndServe 方法,这里我们看一下 Server 结构体的字段:

上图简单的列举了一些 Server 结构体的常见字段,包括:请求处理器、服务名、请求读取超时时间、请求写入超时时间、每个连接最大请求数等。除此之外还有很多其他参数,可以在各个维度上控制服务端的一些参数。
Server 的 ListenAndServe 方法会获取 TCP 监听,然后调用 Serve 方法执行服务端的逻辑处理。
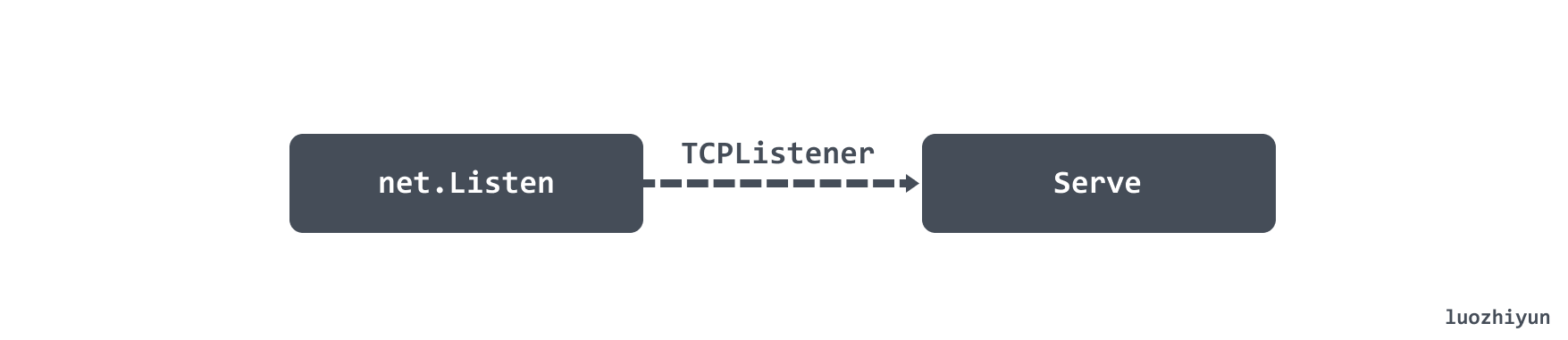
Server 方法主要做了以下几件事:
- 初始化并启动 worker Pool;
- 接收请求 Connection;
- 将 Connection 交给 worker Pool 处理;
func (s *Server) Serve(ln net.Listener) error {
...
s.mu.Unlock()
// 初始化 worker Pool
wp := &workerPool{
WorkerFunc: s.serveConn,
MaxWorkersCount: maxWorkersCount,
LogAllErrors: s.LogAllErrors,
Logger: s.logger(),
connState: s.setState,
}
// 启动 worker Pool
wp.Start()
// 循环处理 connection
for {
// 获取 connection
if c, err = acceptConn(s, ln, &lastPerIPErrorTime); err != nil {
wp.Stop()
if err == io.EOF {
return nil
}
return err
}
s.setState(c, StateNew)
atomic.AddInt32(&s.open, 1)
// 处理 connection
if !wp.Serve(c) {
// 进入if 说明已到并发极限
...
}
c = nil
}
}
worker Pool
worker Pool 是用来处理所有请求 Connection 的,这里稍微看看 workerPool 结构体的字段:

- WorkerFunc: 用来匹配请求对应的 handler 并执行;
- MaxWorkersCount:最大同时处理的请求数;
- ready:空闲的 workerChan;
- workerChanPool:workerChan 的对象池,是一个 sync.Pool 类型的;
- workersCount:目前正在处理的请求数;
下面我们看一下 workerPool 的 Start 方法:
func (wp *workerPool) Start() {
if wp.stopCh != nil {
panic("BUG: workerPool already started")
}
wp.stopCh = make(chan struct{})
stopCh := wp.stopCh
// 设置 worker Pool 的创建函数
wp.workerChanPool.New = func() interface{} {
return &workerChan{
ch: make(chan net.Conn, workerChanCap),
}
}
go func() {
var scratch []*workerChan
for {
// 没隔一段时间会清理空闲超时的 workerChan
wp.clean(&scratch)
select {
case <-stopCh:
return
default:
// 默认是 10 s
time.Sleep(wp.getMaxIdleWorkerDuration())
}
}
}()
}
Start 方法里面主要是:
- 设置 workerChanPool 的创建函数;
- 启动一个 Goroutine 定时清理 workerPool 中的 ready 中保存的空闲 workerChan,默认每 10s 启动一次。
获取连接
func acceptConn(s *Server, ln net.Listener, lastPerIPErrorTime *time.Time) (net.Conn, error) {
for {
c, err := ln.Accept()
if err != nil {
if c != nil {
panic("BUG: net.Listener returned non-nil conn and non-nil error")
}
...
return nil, io.EOF
}
if c == nil {
panic("BUG: net.Listener returned (nil, nil)")
}
// 校验每个ip对应的连接数
if s.MaxConnsPerIP > 0 {
pic := wrapPerIPConn(s, c)
if pic == nil {
if time.Since(*lastPerIPErrorTime) > time.Minute {
s.logger().Printf("The number of connections from %s exceeds MaxConnsPerIP=%d",
getConnIP4(c), s.MaxConnsPerIP)
*lastPerIPErrorTime = time.Now()
}
continue
}
c = pic
}
return c, nil
}
}
获取连接其实没什么好说的,和 net/http 库一样调用的 TCPListener 的 accept 方法获取 TCP Connection。
处理连接
处理连接部分首先会获取 workerChan ,workerChan 结构体里面包含了两个字段:lastUseTime、channel:
type workerChan struct {
lastUseTime time.Time
ch chan net.Conn
}
lastUseTime 标识最后一次被使用的时间;
ch 是用来传递 Connection 用的。
获取到 Connection 之后会传入到 workerChan 的 channel 中,每个对应的 workerChan 都有一个异步 Goroutine 在处理 channel 里面的 Connection。
获取 workerChan
func (wp *workerPool) Serve(c net.Conn) bool {
// 获取 workerChan
ch := wp.getCh()
if ch == nil {
return false
}
// 将 Connection 放入到 channel 中
ch.ch <- c
return true
}
Serve 方法主要是通过 getCh 方法获取 workerChan ,然后将当前的 Connection 传入到 workerChan 的 channel 中。
func (wp *workerPool) getCh() *workerChan {
var ch *workerChan
createWorker := false
wp.lock.Lock()
// 尝试从空闲队列里获取 workerChan
ready := wp.ready
n := len(ready) - 1
if n < 0 {
if wp.workersCount < wp.MaxWorkersCount {
createWorker = true
wp.workersCount++
}
} else {
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
// 获取不到则从对象池中获取
if ch == nil {
if !createWorker {
return nil
}
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
// 为新的 workerChan 开启 goroutine
go func() {
// 处理 channel 中的数据
wp.workerFunc(ch)
// 处理完之后重新放回到对象池中
wp.workerChanPool.Put(vch)
}()
}
return ch
}
getCh 方法首先会去 ready 空闲队列中获取 workerChan,如果获取不到则从对象池中获取,从对象池中获取的新的 workerChan 会启动 Goroutine 用来处理 channel 中的数据。
处理连接
func (wp *workerPool) workerFunc(ch *workerChan) {
var c net.Conn
var err error
// 消费 channel 中的数据
for c = range ch.ch {
if c == nil {
break
}
// 读取请求数据并响应返回
if err = wp.WorkerFunc(c); err != nil && err != errHijacked {
...
}
c = nil
// 将当前的 workerChan 放入的 ready 队列中
if !wp.release(ch) {
break
}
}
wp.lock.Lock()
wp.workersCount--
wp.lock.Unlock()
}
这里会遍历获取 workerChan 的 channel 中的 Connection 然后执行 WorkerFunc 函数处理请求,处理完毕之后会将当前的 workerChan 重新放入到 ready 队列中复用。
需要注意的是,这个循环会在获取 Connection 为 nil 的时候跳出循环,这个 nil 是 workerPool 在异步调用 clean 方法检查该 workerChan 空闲时间超长了就会往 channel 中传入一个 nil。
这里设置的 WorkerFunc 函数是 Server 的 serveConn 方法,里面会获取到请求的参数,然后根据请求调用到对应的 handler 进行请求处理,然后返回 response,由于 serveConn 方法比较长这里就不解析了,感兴趣的同学自己看看。
总结
我们这里分析了 fasthttp 的实现原理,通过原理我们可以知道 fasthttp 和 net/http 在实现上面有什么差异,从而大致得出 fasthttp 快的原因,然后再从它的实现细节知道它在实现上是如何做到减少内存分配从而提高性能的。

fasthttp:比net/http快十倍的Go框架(server 篇)的更多相关文章
- 一个比Spring Boot快44倍的Java框架!
最近栈长看到一个框架,官方号称可以比 Spring Boot 快 44 倍,居然这么牛逼,有这么神奇吗?今天带大家来认识一下. 这个框架名叫:light-4j. 官网简介:A fast, lightw ...
- TDengine能比Hadoop快10倍?
之前对国产的时序大数据存储引擎 TDengine 感兴趣,因为号称比Hadoop快十倍,一直很好奇怎么实现的,所以最近抽空看了下白皮书和设计文档. 如果用一句话总结,就是 TDengine 是为特定的 ...
- 十倍效能提升——Web 基础研发体系的建立
1 导读 web 基础研发体系指的是, web 研发中一线工程师所直接操作的技术.工具,以及所属组织架构的总和.在过去提升企业研发效能的讨论中,围绕的主题基本都是——”通过云计算.云存储等方式将底层核 ...
- [No0000D0] 让你效率“猛增十倍”,沉浸工作法到底是什么?
一位编剧在三天内完成两万字的剧本,而在此之前,他曾拖延了足足半年.一名大四学生用一天半写了8000多字,一鼓作气拿下毕业论文. 有人说:“用了这个方法,我的效率猛增十倍.只用短短两小时,就摧枯拉朽地完 ...
- 通过非聚集索引让select count(*) from 的查询速度提高几十倍、甚至千倍
通过非聚集索引,可以显著提升count(*)查询的性能. 有的人可能会说,这个count(*)能用上索引吗,这个count(*)应该是通过表扫描来一个一个的统计,索引有用吗? 不错,一般的查询,如果用 ...
- grep之字符串搜索算法Boyer-Moore由浅入深(比KMP快3-5倍)
这篇长文历时近两天终于完成了,前两天帮网站翻译一篇文章“为什么GNU grep如此之快?”,里面提及到grep速度快的一个重要原因是使用了Boyer-Moore算法作为字符串搜索算法,兴趣之下就想了解 ...
- Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性 Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+ ...
- delphi-json组件,速度非常快,要比superobject快好几倍
delphi-json组件,速度非常快,要比superobject快好几倍https://github.com/ahausladen/JsonDataObjectshttp://bbs.2ccc.co ...
- IPython,让Python显得友好十倍的外套——windows XP/Win7安装详解
前言 学习python,官方版本其实足够了.但是如果追求更好的开发体验,耐得住不厌其烦地折腾.那么我可以负责任的告诉你:IPython是我认为的唯一显著好于原版python的工具. 整理了 ...
随机推荐
- SLAM的通用框架:GSLAM
SLAM的通用框架:GSLAM GSLAM: A General SLAM Framework and Benchmark 论文链接: http://openaccess.thecvf.com/con ...
- 向量算子优化Vector Operation Optimization
向量算子优化Vector Operation Optimization 查看MATLAB命令View MATLAB Command 示例显示Simulink编码器 ,将生成向量的块输出,设置为标量,优 ...
- 「题解」agc031_e Snuke the Phantom Thief
本文将同步发布于: 洛谷博客: csdn: 博客园: 简书. 题目 题目链接:洛谷 AT4695.AtCoder agc031_e. 题意简述 在二维平面上,有 \(n\) 颗珠宝,第 \(i\) 颗 ...
- 实验3、Flask数据库操作-如何使用Flask与数据库
1. 实验内容 数据库的使用对于可交互的Web应用程序是极其重要的,本节我们主要学习如何与各种主要数据库进行连接和使用,以及ORM的使用 2. 实验要点 掌握Flask对于各种主要数据库的连接方法 掌 ...
- 网页站点下载器teleport ultra
软件名称:teleport ultra 介绍:teleport ultra是一款专门的网页站点下载器,使用这款工具可以方便地下载网页数据,包括网站的文字.图片.flash动画等,可以轻松下载所有的网站 ...
- 基于 Spring Security 的前后端分离的权限控制系统
话不多说,入正题.一个简单的权限控制系统需要考虑的问题如下: 权限如何加载 权限匹配规则 登录 1. 引入maven依赖 1 <?xml version="1.0" enc ...
- 扩展ADO.net实现对象化CRUD(.net core/framework)
扩展ADO.net实现对象化CRUD(.net core/framework) 安装nuget包:CRL using CRL; 实现数据操作 获取数据访问连接IDbConnection dbConne ...
- Custom Controller CollectionQT样式自定义 003 :Bubblemessage 气泡消息窗
效果Demo 思路大致上是加定时器,触发完成出现 - 停留 - 消失的效果. 源码:https://github.com/linzD00/CustomControllerLibrary
- 单片机引脚扩展芯片74HC595手工分解实验
我们先来看下效果 74HC595是常用的串转并芯片,支持芯片级联实现少量IO口控制多个IO口输出功能 14脚:DS,串行数据输入引脚 13脚:OE, 输出使能控制脚,它是低电才使能输出,所以接GND ...
- 15 自动发布Java项目(Tomcat)
#!/bin/bash export PAHT=/usr/local/maven/bin:/usr/local/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/ ...