Unsupervised Domain Adaptation by Backpropagation
Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015.
概
监督学习非常依赖标签数据, 但是获得大量的标签数据在现实中是代价昂贵的一件事情, 这也是为何半监督和无监督重要的原因.
本文提出一种利用GRL来进行domain adaptation的方法, 感觉本文的创新点还是更加偏重于结构一点.
主要内容
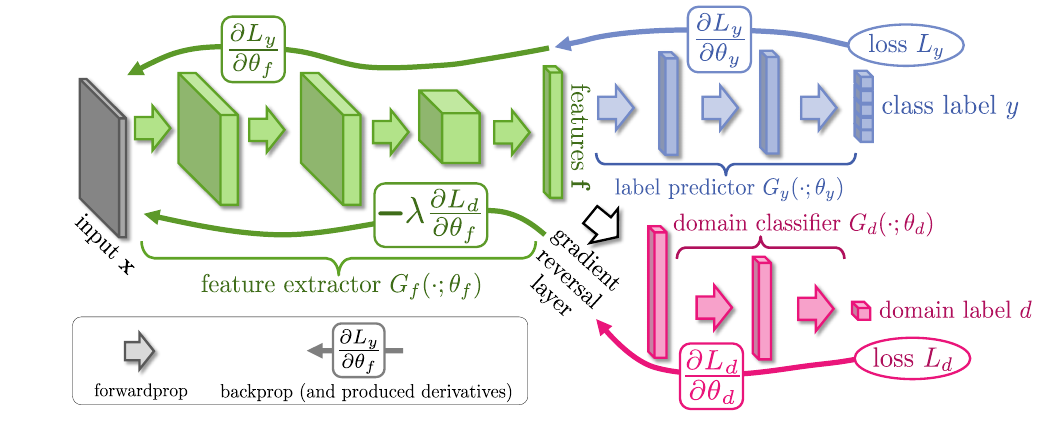
接下来的叙述的方式可能和原文的有一点点的出入.
首先整个网络的框架包括一个用于提取特征的\(G_f\), 可见其是共享的, 提取的到的特征会分别进入上下两个\(G_c, G_d\).
其中, \(G_c\) 是普通的分类器, 当然这要求最开始的输入我们是有对应的标签的, \(G_f + G_c\)也就是我们最后所需要的整个网络.
而\(G_d\)的最后是一个二分类器, 用于区别输入的样本是来自有标签的数据集还是目标数据集.
我们来看一下损失
\]
首先关于\(G_f, G_c\)最小化\(\mathcal{L}_y\), 关于\(G_d\)则是最小化\(\mathcal{L}_d\), 同时关于\(G_f\)最大化\(\mathcal{L}_d\).
直观上讲就是, 我们要求\(G_f\)提取的特征使得分类器能够区分出输入的类别, 而下半部分则是一种对抗的思想, \(G_f\)提取的特征希望\(G_d\)不能够区别出输入来自有标签的域还是目标域, 对应的\(G_d\)是努力去区别开来.
为了实现这一点, 本文利用了一种GRL的技术, 即梯度从\(G_d\)回传到\(G_f\)的时候会变换梯度的方向.
代码
import torch
from torch.autograd import Function
class RevGrad(Function):
@staticmethod
def forward(ctx, inputs):
return inputs
@staticmethod
def backward(ctx, grad_outputs):
return grad_outputs.neg()
Unsupervised Domain Adaptation by Backpropagation的更多相关文章
- 论文笔记:Unsupervised Domain Adaptation by Backpropagation
14年9月份挂出来的文章,基本思想就是用对抗训练的方法来学习domain invariant的特征表示.方法也很只管,在网络的某一层特征之后接一个判别网络,负责预测特征所属的domain,而后特征提取 ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- Unsupervised Domain Adaptation Via Domain Adversarial Training For Speaker Recognition
年域适应挑战(DAC)数据集的实验表明,所提出的方法不仅有效解决了数据集不匹配问题,而且还优于上述无监督域自适应方法.
- Domain Adaptation (3)论文翻译
Abstract The recent success of deep neural networks relies on massive amounts of labeled data. For a ...
- Domain Adaptation (1)选题讲解
1 所选论文 论文题目: <Unsupervised Domain Adaptation with Residual Transfer Networks> 论文信息: NIPS2016, ...
- 关于模式识别中的domain generalization 和 domain adaptation
今晚听了李文博士的报告"Domain Generalization and Adaptation using Low-Rank Examplar Classifiers",讲的很精 ...
- 论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf code链接:https://github.com/YangZhang4065/AdaptationSeg 摘 ...
- 【论文笔记】Domain Adaptation via Transfer Component Analysis
论文题目:<Domain Adaptation via Transfer Component Analysis> 论文作者:Sinno Jialin Pan, Ivor W. Tsang, ...
- 域适应(Domain adaptation)
定义 在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种 特殊 的迁移学习 叫做域适应 (Domain Adaptation). Domain adaptation有哪些实现手段呢? ...
随机推荐
- day04 sersync实时同步和ssh服务
day04 sersync实时同步和ssh服务 sersync实时同步 1.什么是实时同步 实时同步是一种只要当前目录发生变化则会触发一个事件,事件触发后会将变化的目录同步至远程服务器. 2.为什么使 ...
- 18. MYSQL 字符编码配置
MYSQL 5.7版本的my.ini 在C盘隐藏文件夹下 C:\ProgramData\MySQL\MySQL Server 5.7 [client] default-character-set=ut ...
- windows磁盘扩容
要邻近的磁盘,才可以扩展.所以必须要先删除恢复分区. 删除恢复分区,参考如下: https://jingyan.baidu.com/article/574c5219598d5e6c8c9dc15e.h ...
- Flink(五) 【消费kafka】
目录 0.目的 1.本地测试 2.线上测试 提交作业 0.目的 测试flink消费kafka的几种消费策略 kafkaSource.setStartFromEarliest() //从起始位置 kaf ...
- Gradle安装与配置
一.Gradle安装 1.Gradle安装 (1)先安装JDK/JRE (2)Gradle下载官网 Gradle官网 (3)解压安装包到想安装到的目录.如D:\java\gradle-5.2.1 (4 ...
- SpringBoot让测试类飞起来的方法
单元测试是项目开发中必不可少的一环,在 SpringBoot 的项目中,我们用 @SpringBootTest 注解来标注一个测试类,在测试类中注入这个接口的实现类之后对每个方法进行单独测试. 比如下 ...
- mysql 执行报错:Error querying database. Cause: java.sql.SQLSyntaxErrorException:which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
1.这个错误发生在mysql 5.7 版本及以上版本会出现的问题: mysql 5.7版本默认的sql配置是:sql_mode="ONLY_FULL_GROUP_BY",这个配置严 ...
- liunx 安装ActiveMQ 及 spring boot 初步整合 activemq
源码地址: https://gitee.com/kevin9401/microservice.git 一.安装 ActiveMQ: 1. 下载 ActiveMQ wget https://arch ...
- 【力扣】188. 买卖股票的最佳时机 IV
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格. 设计一个算法来计算你所能获取的最大利润.你最多可以完成 k 笔交易. 注意:你不能同时参 ...
- ASP.NET Core中使用漏桶算法限流
漏桶算法是限流的四大主流算法之一,其应用场景各种资料中介绍的不多,一般都是说应用在网络流量控制中.这里举两个例子: 1.目前家庭上网都会限制一个固定的带宽,比如100M.200M等,一栋楼有很多的用户 ...