PubMed数据下载
目标站点分析
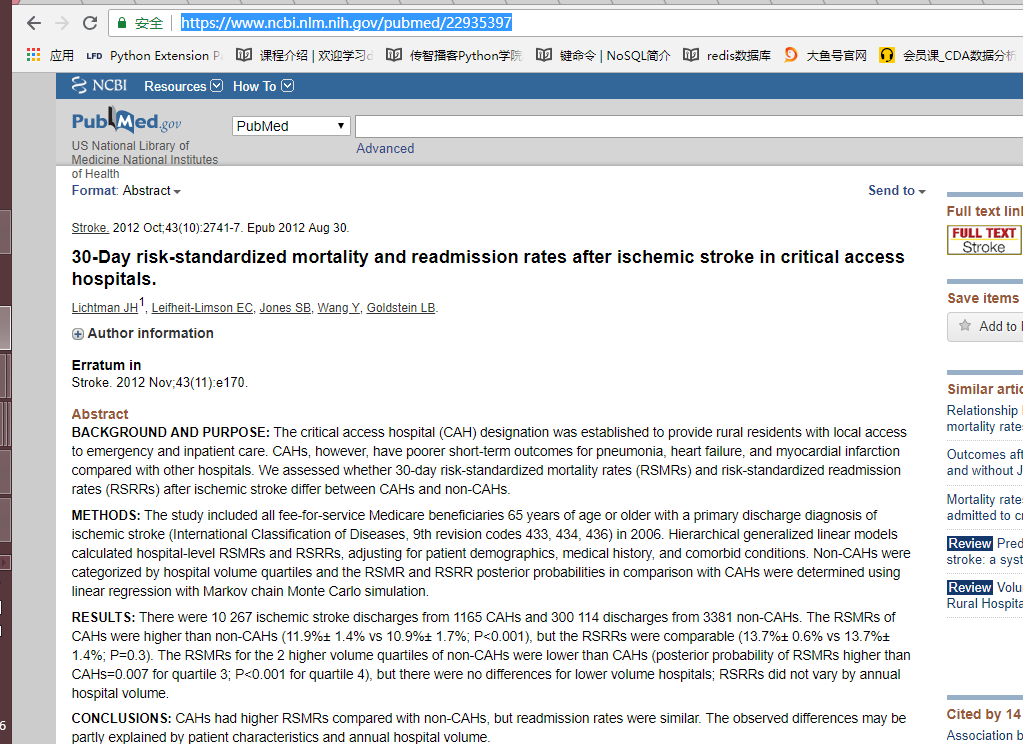
目标:抓取页面中的机构名称,日期,标题,作者, 作者信息, 摘要
程序实现
# -*- coding: utf-8 -*- """
@Datetime: 2019/3/6
@Author: Zhang Yafei
"""
import os
import re
import time
from concurrent.futures import ThreadPoolExecutor
import traceback import pandas as pd
import requests
from pyquery import PyQuery as pq headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} BASE_DIR = 'html' if not os.path.exists(BASE_DIR):
os.mkdir(BASE_DIR) class PubMed(object):
def __init__(self, url):
self.url = url
# self.url = 'https://www.ncbi.nlm.nih.gov/pubmed/{}'.format(id)
self.retry = 0 def download(self):
try:
response = requests.get(self.url, headers=headers, timeout=20)
if response.status_code == 200:
self.parse(response.content)
except Exception as e:
traceback.print_exc()
print('error:' + self.url)
while True:
self.retry += 1
if self.retry < 5:
try:
response = requests.get(self.url, headers=headers, timeout=15)
if response.status_code == 200:
self.parse(response.content)
return
except Exception as e:
print(e)
time.sleep(10)
else:
print(self.url + '下载失败')
return def parse(self, response):
doc = pq(response, parser='html')
periodical_item = doc('.cit')
periodical = periodical_item.children().text()
try:
periodical_datetime = re.search('</a>(.*?);', periodical_item.__str__()).group(1)
except AttributeError:
periodical_datetime = re.search('</a>(.*?).', periodical_item.__str__()).group(1)
title = doc('.rprt_all h1').text()
authors_items = doc('.auths a').items()
authors = ','.join(list(map(lambda x: x.text(), authors_items)))
author_info = doc('.ui-ncbi-toggler-slave dd').text()
abstract = doc('.abstr').text()
data_dict = {'url': [self.url], 'periodical': [periodical], 'periodical_datetime': [periodical_datetime],
'title': [title], 'authors': [authors], 'author_info': [author_info], 'abstract': [abstract]}
self.write_csv(filename='pubmed_result.csv', data=data_dict)
print(self.url + '下载完成') @staticmethod
def write_csv(filename, data=None, columns=None, header=False):
""" 写入 """
if header:
df = pd.DataFrame(columns=columns)
df.to_csv(filename, index=False, mode='w')
else:
df = pd.DataFrame(data=data)
df.to_csv(filename, index=False, header=False, mode='a+') def filter_url_list(urls_list):
df = pd.read_csv('pubmed_result.csv')
has_urls = df.url.tolist()
url_list = set(urls_list) - set(has_urls)
print('共:{} 完成:{} 还剩:{}'.format(len(urls_list), len(has_urls), len(url_list)))
return list(url_list) def read_data():
df = pd.read_excel('data.xlsx', header=None)
return df[0].tolist() def main(url):
""" 主函数 """
pubmed = PubMed(url=url)
pubmed.download() if __name__ == '__main__':
url_list = read_data()
if not os.path.exists('pubmed_result.csv'):
columns = ['url', 'periodical', 'periodical_datetime', 'title', 'authors', 'author_info', 'abstract']
PubMed.write_csv(filename='pubmed_result.csv', columns=columns, header=True)
else:
url_list = filter_url_list(url_list) pool = ThreadPoolExecutor()
pool.map(main, url_list)
pool.shutdown() # 写入excel
df = pd.read_csv('pubmed_result.csv')
writer = pd.ExcelWriter('pubmed_result.xlsx')
df.to_excel(writer, 'table', index=False)
writer.save()
PubMed数据下载的更多相关文章
- tensorflow学习笔记三:实例数据下载与读取
一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们 ...
- ios的网络数据下载和json解析
ios的网络数据下载和json解析 简介 在本文中,笔者将要给大家介绍如何使用nsurlconnection 从网上下载数据,以及解析json数据格式,以及如何显示数据和图片的异步下载显示. 涉及的知 ...
- 腾讯QQ群数据下载方法(7000万个qq群资料全泄漏)
仔细读完一定能找到自己需要的东西 据新华网报道,国内知名安全漏洞监测平台乌云20日公布报告称,腾讯QQ群关系数据被泄露,网上可以轻易就能找到数据下载链接,根据这些数据,通过QQ号可以查询到备注姓名.年 ...
- ios 网络数据下载和JSON解析
ios 网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍ios中如何利用NSURLConnection从网络上下载数据,如何解析下载下来的JSON数据格式,以及如何显示数据和图片的异步下载 ...
- iOS之网络数据下载和JSON解析
iOS之网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍IOS中如何利用NSURLconnection从网络上下载数据以及如何解析下载下来的JSON数据格式,以及如何显示数据和托图片的异步 ...
- Asp.Net MVC 实现将Easy-UI展示数据下载为Excel 文件
在一个项目中,需要做一个将Easy-UI界面展示数据下载为Excel文件的功能,经过一段时间努力,完成了一个小Demo.界面如下: 但按下导出Excel后,Excel文件将会下载到本地,在office ...
- OSM数据下载地址
1.OSM数据下载地址 官网下载: http://planet.openstreetmap.org/ GeoFabrik:http://www.geofabrik.de/ Metro Extracts ...
- 医学图像数据(三)——TCIA部分数据下载方式
前为止,本人还没有找到不需要账号的就可以部分下载的方式,因此这里讲的是需要注册账号下载部分数据的方法. 注意:下载部分数据需要注册账号 注册账号网址:https://public.cancerimag ...
- DEM数据及其他数据下载
GLCF大家都知道吧?http://glcf.umiacs.umd.edu/data/ +++++++++++++++去年12月份听遥感所一老师说TM08初将上网8万景,可是最近一直都没看到相关的网页 ...
随机推荐
- Nginx map模块
L77 Syntax: map string $variable { ... } Default: — Context: http map 指令 curl -H 'aaaa:4444444' -H ' ...
- Javascript和Jquery语法对比总结
目的 相信大家都知道jq是js的一个类库,是为了方便我们开发前端,但是笔者在刚开始学习js和jq时经常将两者的语法记混和混用,所以整理下两者实现相同功能之前的语法区别. 声明变量 javascript ...
- 进程创建fork()
简单进程创建例子: #include <stdio.h> #include <sys/types.h> #include <sys/wait.h> #include ...
- Codeforces Round #443 Div. 1
A:考虑每一位的改变情况,分为强制变为1.强制变为0.不变.反转四种,得到这个之后and一发or一发xor一发就行了. #include<iostream> #include<cst ...
- P1308 统计单词数
P1308 题目描述 一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数. 现在,请你编程实现这一功能,具体要求是:给定一个单词,请 ...
- Python中xlutils解析
1.导入模块 import xlrd import xlutils.copy 2.打开模块表 book = xlrd.open_workbook('test.xls', formatting_info ...
- Edge Deletion CodeForces - 1076D(水最短路)
题意: 设从1到每个点的最短距离为d,求删除几条边后仍然使1到每个点的距离为d,使得剩下的边最多为k 解析: 先求来一遍spfa,然后bfs遍历每条路,如果d[v] == d[u] + Node[i] ...
- mysql 备份数据语句
rem ******MySQL backup start********@echo offforfiles /p "D:\website\备份\数据库日常备份" /m backup ...
- Logger.error方法之打印错误异常的详细堆栈信息
一.问题场景 使用Logger.error方法时只能打印出异常类型,无法打印出详细的堆栈信息,使得定位问题变得困难和不方便. 二.先放出结论 Logger类下有多个不同的error方法,根据传入参数的 ...
- 自学Aruba之添加黑名单Blacklists方法
点击返回:自学Aruba之路点击返回:自学Aruba集锦 07 自学Aruba之添加黑名单Blacklists方法 方法一:页面添加方式,临时添加黑名单(禁止入网60min)方法二:命令行添加方式,临 ...