Ubuntu 12.04上安装Hadoop并运行
Ubuntu 12.04上安装Hadoop并运行
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
在官网上下载好四个文件
在Ubuntu的/home/wrr/下创建一个文件夹java,将这四个文件拷到Ubuntu的/home/wrr/java/下,将eclipse、hadoop-2.7.6与jdk进行解压,将.iar文件复制到eclipse/plugins,将/jdk1.8.0_191/下的jre文件夹拷到eclipse中,如下图所示

在/home/wrr/下新建文件夹data,里面新建三个文件夹data、name与tmp,创建文件夹的命令:sudo mkdir java

添加环境变量
sudo gedit ~/.bashrc
打开.bashrc,在后面添加环境变量
export JAVA_HOME=/home/wrr/java/jdk1.8.0_191
export JRE_HOME=/home/wrr/java/jdk1.8.0_191/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export HADOOP_HOME=/home/wrr/java/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
再键入
source ~/.bashrc
此时环境变量添加成功,现在输入hadoop version 与 java -version来查看版本。

配置/home/wrr/java/hadoop-2.7.6/etc/hadoop下的集群参数
hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. # Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes. # The java implementation to use.
export JAVA_HOME=/home/wrr/java/jdk1.8.0_191 # The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done # The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE="" # Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS" # On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} # Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER # Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER} ###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS="" ###
# Advanced Users Only!
### # The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wrr/data/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/wrr/data/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/wrr/data/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.httpaddress</name>
<value>localhost:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration> <!-- Site specific YARN configuration properties --> <property>
<name>yarn.resourcemanager.address</name>
<value>localhost:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resourcetracker.address</name>
<value>localhost:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:18141</value>
</property>
<property>
<name>yarn.nodemanager.auxservices</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> </configuration>
启动hadoop。首先导入/home/wrr/java/hadoop-2.7.6/sbin一下目录,再启动namenode,datanode与yarn
wrr@ubuntu:~$ cd /home/wrr/java/hadoop-2.7.6/sbin
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ jps
6559 Jps
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./hadoop-daemon.sh start datanode
starting datanode, logging to /home/wrr/java/hadoop-2.7.6/logs/hadoop-wrr-datanode-ubuntu.out
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/wrr/java/hadoop-2.7.6/logs/yarn-wrr-resourcemanager-ubuntu.out
localhost: ssh: connect to host localhost port 22: Connection refused
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./hadoop-daemon.sh start namenode
starting namenode, logging to /home/wrr/java/hadoop-2.7.6/logs/hadoop-wrr-namenode-ubuntu.out
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ jps
6978 NameNode
6692 ResourceManager
7013 Jps
6587 DataNode
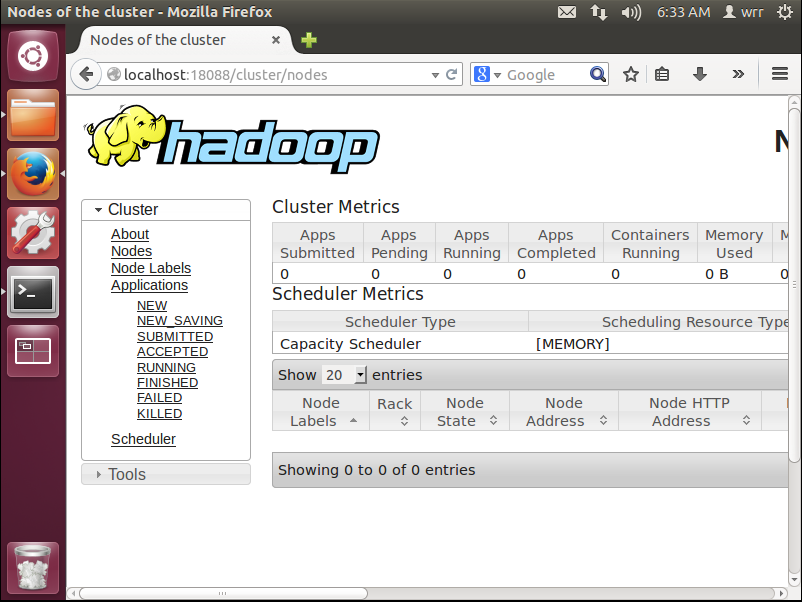
都启动之后,在浏览器上输入http://localhost:18088,即可出现如下界面
停止hadoop
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./hadoop-daemon.sh stop namenode
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./hadoop-daemon.sh stop datanode
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ ./stop-yarn.sh
wrr@ubuntu:~/java/hadoop-2.7.6/sbin$ jps
7259 Jps
如果想看更详细的解读,请看Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04_厦大数据库实验室博客
Ubuntu 12.04上安装Hadoop并运行的更多相关文章
- Ubuntu 12.04上安装HBase并运行
Ubuntu 12.04上安装HBase并运行 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.HBase的安装 在官网上下载HBase-1.1.2 ...
- Ubuntu 12.04上安装MySQL并运行
Ubuntu 12.04上安装MySQL并运行 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 安装MySQL数据库 sudo apt-get upda ...
- Ubuntu 12.04上安装 MongoDB并运行
Ubuntu 12.04上安装 MongoDB并运行 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在Terminal输入 sudo apt-key ...
- Ubuntu 12.04上安装R语言
Ubuntu 12.04上安装R语言 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ R的安装 sudo gedit /etc/apt/sources. ...
- 在 Ubuntu 12.04 上安装 GitLab6.0
安装环境: 操作系统: Ubuntu 12.4 LTS 英文 数据库: mysql5.5.32 web服务器: nginx1.4.1 首先, 添加git和nginx的ppa,并升级 ...
- ubuntu 12.04上安装QQ2013(转载)
转自:http://www.cnblogs.com/wocn/p/linux_ubuntu_QQ_install.html 环境介绍: OS:Ubuntu12.04 64bit QQ:WineQQ20 ...
- 在 Ubuntu 12.04 上安装 GitLab7.x
安装环境: 操作系统: Ubuntu 12.4 LTS 英文 数据库: postgresql webserver: nginx 能够说到7.x的时候,GitLab的文档已经相当完好 ...
- ubuntu 12.04上安装OpenERP 7的一次记录
登陆ssh, 先更新系统: sudo apt-get update && sudo apt-get dist-upgrade 接着再为openerp运行创建一个系统用户,用户名就叫op ...
- 在ubuntu 12.04上安装tomcat 7.40
因为源上的版本问题,所以没有使用源上的自动安装包,老规矩,Tomcat 7.0.40 Core下载地址:http://mirror.bit.edu.cn/apache/tomcat/tomcat-7/ ...
随机推荐
- NLP入门(二)探究TF-IDF的原理
TF-IDF介绍 TF-IDF是NLP中一种常用的统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,通常用于提取文本的特征,即关键词.字词的重要性随着它在文件中出现的 ...
- RNN-LSTM入门
RNN-LSTM入门 Last Edited: Dec 02, 2018 10:20 PM Tags: 机器学习,论文阅读 RNN-Recurrent Neural Network 概念: 序列数据: ...
- 对于SQL的Join,在学习起来可能是比较乱的。我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚。Coding Horror上有一篇文章,通过文氏图 Venn diagrams 解释了SQL的Join。我觉得清楚易懂,转过来。
对于SQL的Join,在学习起来可能是比较乱的.我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚.Codi ...
- 2. 常见的Queue
package com.gf.conn013; import java.util.ArrayList; import java.util.Iterator; import java.util.List ...
- 如何用STAR法则来回答「宝洁八大问」
掌握宝洁八大问,其实就是掌握了半个求职季 每年高峰期,很多同学会问到关于宝洁八大的问题,如何准备.怎么讲故事.如何体现自己的特点等等.针对同学们的提问,分享一篇关于如何回答好宝洁八大问的文章,希望能够 ...
- 构造方法为private与类修饰符为final
构造方法为private的:在这个类外1:不能继承这个类2:不能用new来产生这个类的实例 在这个类内:1:可以继承这个类2:可以用new来产生这个类的实例 类修饰符为final的:在这个类外1:不能 ...
- WORLD 快速线
1,3个“-” 一条直线 2,3个“=” 一条双直线 3,3个“*” 一条虚线 4,3个“~” 一条波浪线 5, 3个“#” 一条隔行线
- JavaScript 中的相等操作符 ( 详解 [] == []、[] == ![]、{} == !{} )
ECMAScript 中的相等操作符由两个等于号 ( == ) 表示,如果两个操作数相等,则返回 true. 相等操作符会先转换操作数(通常称为强制转型),然后比较它们的相等性. 在转换不同的数据类型 ...
- nodeJs express mongodb 建站(linux 版)
一.环境安装 1.安装node wget http://nodejs.org/dist/v0.12.2/node-v0.12.2-linux-x64.tar.gz //下载tar xvf node-v ...
- TS学习随笔(二)->类型推论,联合类型
这篇内容指南: -----类型推论 -----联合类型 类型推论 第一篇中我们看了TS的基本使用和基本数据类型的使用,知道了变量在使用的时候都得加一个类型,那我们可不可以不加呢,这个嘛 ...