如何保证Redis的高并发
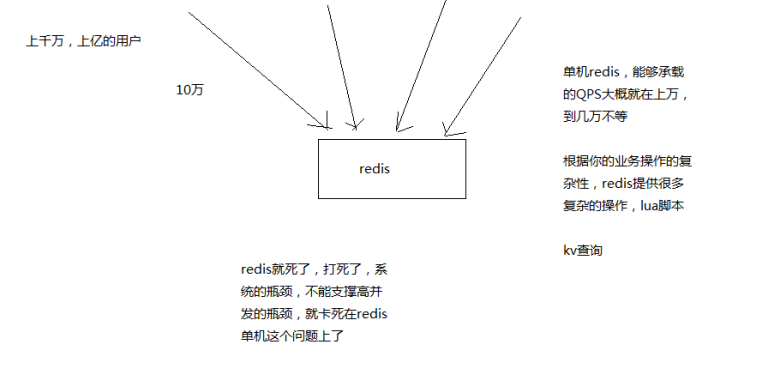
单机的redis几乎不太可能说QPS超过10万+,一般在几万。
除非一些特殊情况,比如你的机器性能特别好,配置特别高,物理机,维护做的特别好,而且你的整体的操作不是太复杂。

Redis通过主从架构,实现读写分离,主节点负责写,并将数据同步给其他从节点,从节点负责读,从而实现高并发。
Redis高并发的同时,还需要容纳大量的数据:一主多从,每个实例都容纳了完整的数据,比如redis主就10G的内存量,其实你就最对只能容纳10g的数据量。如果你的缓存要容纳的数据量很大,达到了几十g,甚至几百g,或者是几t,那你就需要redis集群,而且用redis集群之后,可以提供可能每秒几十万的读写并发。
replication的核心机制
redis采用异步方式复制数据到slave节点,不过redis 2.8开始,slave node会周期性地确认自己每次复制的数据量
一个master node是可以配置多个slave node的
slave node也可以连接其他的slave node
slave node做复制的时候,是不会block master node的正常工作的
slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了
slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
master持久化对于主从架构的安全保障的意义
如果采用了主从架构,那么建议必须开启master node的持久化!
不建议用slave node作为master node的数据热备,因为那样的话,如果你关掉master的持久化,可能在master宕机重启的时候数据是空的,然后可能一经过复制,salve node数据也丢了
第二个,master的各种备份方案,要不要做,万一说本地的所有文件丢失了; 从备份中挑选一份rdb去恢复master; 这样才能确保master启动的时候,是有数据的
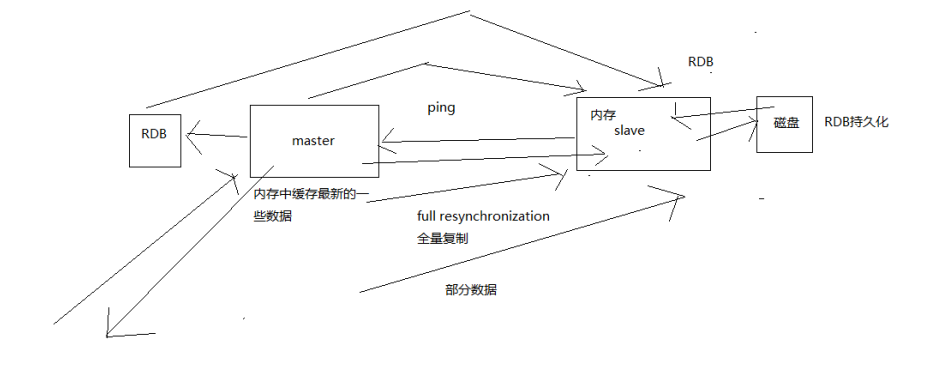
master同步数据给slave的过程
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这是slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据; 否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。
RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
主从复制的断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。
如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制
但是如果没有找到对应的offset,那么就会执行一次resynchronization
无磁盘化复制
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
repl-diskless-sync
repl-diskless-sync-delay,等待一定时长再开始复制,因为要等更多slave重新连接过来
过期key处理
slave不会过期key,只会等待master过期key。
如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。
复制的完整流程
slave node启动,仅仅保存master node的信息,包括master node的host和ip(redis.conf里面的slaveof配置的),但是复制流程没开始
slave node内部有个定时任务,每秒检查是否有新的master node要连接和复制,如果发现,就跟master node建立socket网络连接
slave node发送ping命令给master node
口令认证,如果master设置了requirepass,那么salve node必须发送masterauth的口令过去进行认证
master node第一次执行全量复制,将所有数据发给slave node
master node后续持续将写命令,异步复制给slave node
数据同步相关的核心机制
指的就是第一次slave连接msater的时候,执行的全量复制,那个过程里面你的一些细节的机制
(1)master和slave都会维护一个offset
master会在自身不断累加offset,slave也会在自身不断累加offset
slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset
这个倒不是说特定就用在全量复制的,主要是master和slave都要知道各自的数据的offset,才能知道互相之间的数据不一致的情况
(2)backlog
master node有一个backlog,默认是1MB大小
master node给slave node复制数据时,也会将数据在backlog中同步写一份
backlog主要是用来做全量复制中断候的增量复制的
(3)master run id
info server,可以看到master run id
如果根据host+ip定位master node,是不靠谱的,如果master node重启或者数据出现了变化,那么slave node应该根据不同的run id区分,run id不同就做全量复制
如果需要不更改run id重启redis,可以使用redis-cli debug reload命令
(4)psync
从节点使用psync从master node进行复制,psync runid offset
master node会根据自身的情况返回响应信息,可能是FULLRESYNC runid offset触发全量复制,可能是CONTINUE触发增量复制
全量复制
master执行bgsave,在本地生成一份rdb快照文件
master node将rdb快照文件发送给salve node,如果rdb复制时间超过60秒(repl-timeout),那么slave node就会认为复制失败,可以适当调节大这个参数
对于千兆网卡的机器,一般每秒传输100MB,6G文件,很可能超过60s
master node在生成rdb时,会将所有新的写命令缓存在内存中,在salve node保存了rdb之后,再将新的写命令复制给salve node
client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败
slave node接收到rdb之后,清空自己的旧数据,然后重新加载rdb到自己的内存中,同时基于旧的数据版本对外提供服务
如果slave node开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF
增量复制
如果全量复制过程中,master-slave网络连接断掉,那么salve重新连接master时,会触发增量复制
master直接从自己的backlog中获取部分丢失的数据,发送给slave node,默认backlog就是1MB
msater就是根据slave发送的psync中的offset来从backlog中获取数据的
heartbeat
主从节点互相都会发送heartbeat信息
master默认每隔10秒发送一次heartbeat,salve node每隔1秒发送一个heartbeat
异步复制
master每次接收到写命令之后,现在内部写入数据,然后异步发送给slave node
转自:中华石杉Java工程师面试突击
如何保证Redis的高并发的更多相关文章
- 5.如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么?
作者:中华石杉 面试题 如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么? 面试官心理分析 其实问这个问题,主要是考考你,redis ...
- 面试系列15 如何保证Redis的高并发和高可用
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- 如何保证Redis的高并发和高可用?
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 redis高并发:主从 ...
- Redis的高并发、持久化、高可用架构设计
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- Redis实现高并发分布式序列号
使用Redis实现高并发分布式序列号生成服务 序列号的构成 为建立良好的数据治理方案,作数据掌握.分析.统计.商业智能等用途,业务数据的编码制定通常都会遵循一定的规则,一般来讲,都会有自己的编码规则和 ...
- 关于Redis处理高并发
Redis的高并发和快速原因 1.Redis是基于内存的,内存的读写速度非常快: 2.Redis是单线程的,省去了很多上下文切换线程的时间: 3.Redis使用多路复用技术,可以处理并发的连接.非阻塞 ...
- redis处理高并发
参考: https://www.cnblogs.com/wanlei/p/10464517.html 关于Redis处理高并发 Redis的高并发和快速原因 1.Redis是基于内存的,内存的读写速度 ...
- Nginx与Redis解决高并发问题
原文链接:http://bbs.phpchina.com/forum.php?mod=viewthread&tid=229629 第一版产品采用的是Jquery,Nginx,PHP(CI框架) ...
- nginx+lua+redis构建高并发应用(转)
nginx+lua+redis构建高并发应用 ngx_lua将lua嵌入到nginx,让nginx执行lua脚本,高并发,非阻塞的处理各种请求. url请求nginx服务器,然后lua查询redis, ...
随机推荐
- nc替代技术方案
powershell $client = New-Object System.Net.Sockets.TCPClient('127.0.0.1',4444);$stream = $client.Get ...
- 利用Linux系统生成随机密码的10种方法【转】
Linux操作系统的一大优点是对于同样一件事情,你可以使用高达数百种方法来实现它.例如,你可以通过数十种方法来生成随机密码.本文将介绍生成随机密码的十种方法. 1. 使用SHA算法来加密日期,并输出结 ...
- Kafka监控KafkaOffsetMonitor【转】
1.概述 前面给大家介绍了Kafka的背景以及一些应用场景,并附带上演示了Kafka的简单示例.然后,在开发的过程当中,我们会发现一些问题,那就是消息的监控情况.虽然,在启动Kafka的相关服务后,我 ...
- C#操作剪贴板实现复制粘贴
//粘贴 private void tsbPaste_Click(object sender, EventArgs e) { IDataObject iData = Clipboard.GetData ...
- Mac下更改JDK环境变量配置
1.打开终端 2.如果你是第一次配置环境变量,可以使用“touch .bash_profile” 创建一个.bash_profile的隐藏配置文件(如果你是为编辑已存在的配置文件,则使用"o ...
- PYTHON深拷贝与浅拷贝
浅拷贝就是对引用的拷贝,深拷贝就是对对象的资源的拷贝 浅拷贝 浅拷贝仅仅复制了容器中元素的地址 赋值的原则 1.赋值是将一个对象的地址赋值给一个变量,让变量指向该地址( 旧瓶装旧酒 ). 2.修改不可 ...
- 【原创】大叔经验分享(41)hdfs开启kerberos之后报错Encryption type AES256 CTS mode with HMAC SHA1-96 is not supported/enabled
hdfs开启kerberos之后,namenode报错,连不上journalnode 2019-03-15 18:54:46,504 WARN org.apache.hadoop.security.U ...
- vue.js插槽
具体讲解的url https://github.com/cunzaizhuyi/vue-slot-demo //例子 用jsfiddle.net去运行就好 <!DOCTYPE html> ...
- es2015箭头函数的this
摘自https://www.cnblogs.com/chenxygx/p/6509564.html,谢谢博主的分享!
- zxing源码编译与运行
编译的jar文件下载地址:http://files.cnblogs.com/rainboy2010/zxing.zip zxing是一个开源的解析条形码/二维码的类库,广泛应用于Android 各大A ...