Hadoop学习笔记(四):Yarn和MapReduce
1. 先关闭掉所有的防火墙(master和所有slave)
2. 配置yarn-site.xml文件(配置所有机器,此时没有启动hadoop服务)
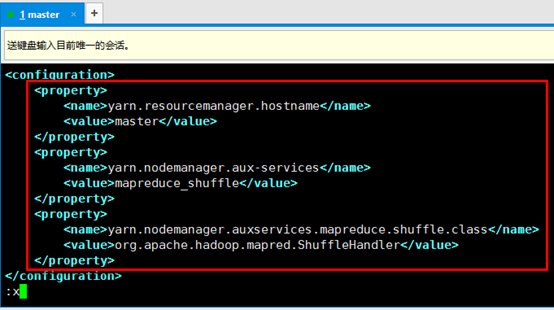
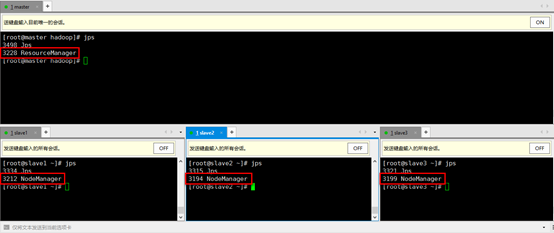
3. 启Yarn,输入要命令start-yarn.sh,用jps检测,看到如下情况表示启动成功
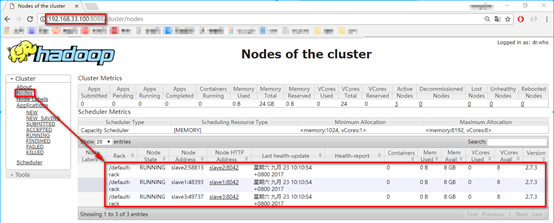
4. 在宿主机浏览器上进行查看,输入地址master:8088,可以看到Yarn的相关情况:
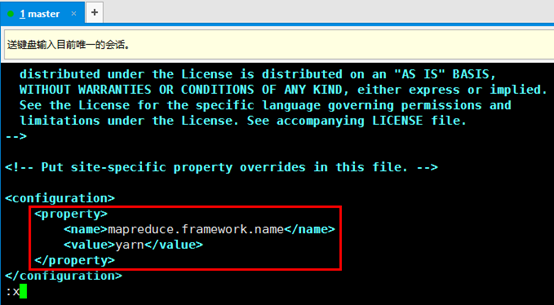
5. 下面我们在Yarn上跑一个计算,由于我们需要计算的文档存放的hdfs上,因此我们首先需要启动hadoop服务。然后需要指定MapReduce跑在Yarn上,配置mapred-site.xml(听老师讲的时候,配置的是这个文件,可是我的机器上没有这个文件,只有mapred-queues.xml.template,于是我copy了它一份,把名字改成了mapred-queues.xml)
6. 首先在本地创建一个文件,用于计算的时候使用:
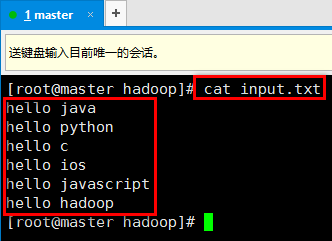
7. 在hadoop根目录下创建一个文件夹input,并将上述创建的文件上传到该目录下:

8. 计算的功能是,计算该文件中有多少个单词,每个单词出现的次数。查找一下该例子程序:
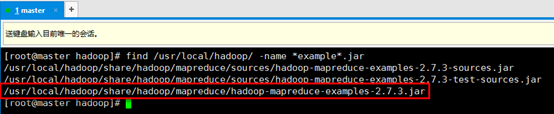
9. 运行该例子程序,输入命令:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/input.txt /output
hadoop jar为运行jar包,后面跟的是jar包的完全路径,wordcount为指定该jar中的方法,/input/input.txt为要操作的文件,也可以指定一个目录,那就hadoop就会统计目录下的所有文件内容,再后边的/output为执行结果的输出目录。
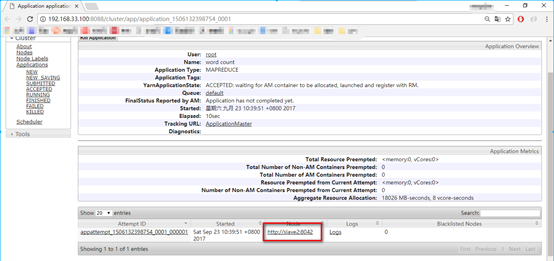
10. 在宿主机浏览器中查看,点击Applicatons,发现有一个任务了

11. 点击该任务的ID,进入查看该任务的详情,发现该任务在slave2上运行,点击该链接进入查看(打不开的话尝试使用slave2的ip加端口8082)
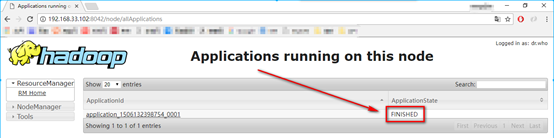
12. 进入slave2后,点击List of,发现该任务已经完成了
13. 查看一下刚才任务的输出目录

14. 查看这个输出文件

Hadoop学习笔记(四):Yarn和MapReduce的更多相关文章
- Hadoop学习笔记四
一.fsimage,edits和datanode的block在本地文件系统中位置的配置 fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:// ...
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- hadoop学习笔记(四)——eclipse+maven+hadoop2.5.2源代码
Eclipse同maven进口hadoop源代码 1) 安装和配置maven环境变量 M2_HOME: D:\profession\hadoop\apache-maven-3.3.3 PATH: % ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- go语言的运算符
什么是运算符:运算符用于在程序运行时执行数学或逻辑运算 go语言的运算符如下: 算术运算符 关系运算符 逻辑运算符 位运算符 赋值运算符 其他运算符 一,算数运算符 运算符 描述 实例 + 相加 A ...
- #pragma常用预处理指令
#pragma pack(1):1字节对齐#pragma once:指定头文件被编译一次#pragma message("message"):编译时输出message文本#prag ...
- Python_day9
多继承: python支持,但不建议使用 dir(): 获取类或者对象的方法和属性 __mro__:获取类的继承顺序 class A(object): def run(self): print('ru ...
- 1034 Head of a Gang 图的遍历,map使用
命名冲突,导致编译失败.这大概就是之前看到的最好不要using namespace std:的原因
- java中接口和继承的区别
实际概念区别:区别1:不同的修饰符修饰(interface),(extends)区别2:在面向对象编程中可以有多继承!但是只支持接口的多继承,不支持'继承'的多继承哦而继承在java中具有单根性,子类 ...
- Day06 (黑客成长日记) 初识函数和返回值的作用
定义函数: 1.初识函数: 我们在学习字符串时,有这样的操作: li = 'tsy be ba bvake ' print(len(li)) 这样可以打印出li的长度,我们利用了python中的len ...
- 基于模型的特征选择详解 (Embedded & Wrapper)
目录 基于模型的特征选择详解 (Embedded & Wrapper) 1. 线性模型和正则化(Embedded方式) 2. 基于树模型的特征选择(Embedded方式) 3. 顶层特征选择算 ...
- hightopo自己用开源的方案重构一遍
经过一年多的学习吧前面路上的坑基本算踩过一遍了 所以下面计划吧hightopo网站上的demo用自己的方式重新写一遍
- python对象的for迭代实现
第一种:__iter__ 实现__iter__的对象,是可迭代对象.__iter__方法可以直接封装一个迭代器,从而实现for循环 class A: def __init__(self): self. ...
- EmguCV使用Stitcher类来拼接图像
using System; using System.Windows; using System.Collections.Generic; using System.ComponentModel; u ...