SQL查询语句的进阶使用
MySQL的进阶使用
sql语句一些功能的使用
- 导入现有大量数据文件步骤
1) 把*.sql文件拷贝到Linux某一位置(例如Desktop)
2) Linux命令行进入该位置 cd ~/Desktop
3) 登录mysql
4) 使用数据库 mysql> use 数据库名;
5) 创建表 mysql>
create table 表名(
添加字段
-- 字段属性要和要导入的文件内数据结构相同
);
6) 执行命令 mysql> source 表名.sql
AS 关键字的使用
- 字段起名
select id as 序号, name as 名字, gender as 性别 from students;
- 表起名
select s.id,s.name,s.gender from students as s;
将查询的数据直接插入表中
insert into xxx (字段名) select 语句
将select语句的结果集插入到一个表中
distinct关键字
消除重复的行。
select distinct gender from students;
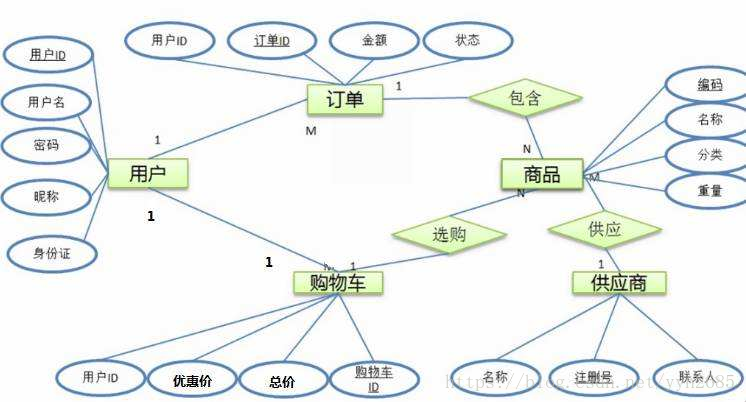
关于三范式和E-R模型
三范式
- 范式指的就是设计数据库的通用规范, 共有8种范式,一般需要遵守3范式即可 1NF强调字段是最小单元,不可再分
- 2NF强调在1NF基础上必须要有主键和非主键字段必须完全依赖于主键,也就是说 不能部分依赖
- 3MF强调在2NF基础上 非主键字段必须直接依赖于主键,也就是说不能传递依赖(间接依赖)。
E-R模型 即E-R图
E-R图由 实体、属性、实体之间的联系构成,主要用来描述 数据库中表结构。
- 实体型(Entity):一般对应的是数据中的表名,在E-R图中用矩形表示,矩形框内写明实体名;比如 电商购物系统中用户、购物车、订单等都是实体。
- 属性(Attribute):一般对应的 表中的字段名称,在E-R图中用椭圆形表示,并用无向边将其与相应的实体连接起来;比如用户的ID、用户名、密码、昵称、身份证号码 都是属性。
- 联系(Relationship): 实体彼此之间相互连接的方式称为联系,也称为关系。联系可分为以下 3 种类型:
- 一对一
- 一对多
- 多对多
举例一学生表
mysql> select * from students;
+----+-----------+------+--------+--------+--------+-----------+
| id | name | age | height | gender | cls_id | is_delete |
+----+-----------+------+--------+--------+--------+-----------+
| 1 | 小明 | 18 | 180.00 | 女 | 1 | |
| 2 | 小月月 | 18 | 180.00 | 女 | 2 | |
| 3 | 彭于晏 | 29 | 185.00 | 男 | 1 | |
| 4 | 刘德华 | 59 | 175.00 | 男 | 2 | |
| 5 | 黄蓉 | 38 | 160.00 | 女 | 1 | |
| 6 | 凤姐 | 28 | 150.00 | 保密 | 2 | |
| 7 | 王祖贤 | 18 | 172.00 | 女 | 1 | |
| 8 | 周杰伦 | 36 | NULL | 男 | 1 | |
| 9 | 程坤 | 27 | 181.00 | 男 | 2 | |
| 10 | 刘亦菲 | 25 | 166.00 | 女 | 2 | |
| 11 | 金星 | 33 | 162.00 | 中性 | 3 | |
| 12 | 静香 | 12 | 180.00 | 女 | 4 | |
| 13 | 郭靖 | 12 | 170.00 | 男 | 4 | |
| 14 | 周杰 | 34 | 176.00 | 女 | 5 | |
+----+-----------+------+--------+--------+--------+-----------+
14 rows in set (0.00 sec)
一、Where 条件
比较运算符
等于: =
大于: >
大于等于: >=
小于: <
小于等于: <=
不等于: != 或 <>
逻辑运算符
and
查询students表中,年龄在18到28之间的所有学生信息
错误实例: select * from students where 18<age<28;
正确: mysql> select * from students where age >= 18 and age <= 28;
or
not
and比or先运算,如果同时出现并希望先算or,需要结合()使用
模糊查询
like
```
%表示任意多个任意字符
select * from students where name like '静香%';
```_表示一个任意字符
```
select * from students where name like '静_';
```范围查询
查询编号是1或3或8的学生
select * from students where id in(1,3,8);
查询编号为3至8的学生
select * from students where id between 3 and 8;
between A and B在匹配数据的时候匹配的范围空间是 [A,B]
空判断
判断为空
is null
判非空
is not null
二、排序
排序查询语法:
select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]
语法说明:
1. 将行数据按照列1进行排序,如果某些行 列1 的值相同时,则按照 列2 排序,以此类推
2. asc从小到大排列,即升序
3. desc从大到小排序,即降序
4. 默认按照列值从小到大排列(即asc关键字)
例1:查询未删除男生信息,按学号降序
select * from students where gender=1 and is_delete=0 order by id desc;
例2:查询未删除学生信息,按名称升序
select * from students where is_delete=0 order by name;
例3:显示所有的学生信息,先按照年龄从大-->小排序,当年龄相同时 按照身高从高-->矮排序
select * from students order by age desc,height desc;
三、分页
分页查询语法
select * from 表名 limit start=0,count
说明
1. 从start开始,获取count条数据
2. start默认值为0
3. 也就是当用户需要获取数据的前n条的时候可以直接写上 xxx limit n;
例:查询前3行男生信息
select * from students where gender=1 limit 0,3;
获取第n页数据SQL语句的推导公式
select * from students where is_delete=0 limit (n-1)*m,m
# 注意:在sql语句中limit后不可以直接加公式
四、聚合函数
count( * ) 表示计算总行数,括号中写星与列名,结果是相同的
例:查询学生总数
select count(*) from students;
max(列) 表示求此列的最大值
例:查询女生的编号最大值
select max(id) from students where gender=2;
min(列) 表示求此列的最小值
例:查询未删除的学生最小编号
select min(id) from students where is_delete=0;
sum(列) 表示求此列的和
例:查询男生的总年龄
select sum(age) from students where gender=1;
-- 平均年龄
select sum(age)/count(*) from students where gender=1;
avg(列) 表示求此列的平均值
例:查询未删除女生的编号平均值
select avg(id) from students where is_delete=0 and gender=2;
五、分组
select * from students;
+----+-----------+------+--------+--------+--------+-----------+
| id | name | age | height | gender | cls_id | is_delete |
+----+-----------+------+--------+--------+--------+-----------+
| 1 | 小明 | 18 | 180.00 | 女 | 1 | |
| 2 | 小月月 | 18 | 180.00 | 女 | 2 | |
| 3 | 彭于晏 | 29 | 185.00 | 男 | 1 | |
| 4 | 刘德华 | 59 | 175.00 | 男 | 2 | |
| 5 | 黄蓉 | 38 | 160.00 | 女 | 1 | |
| 6 | 凤姐 | 28 | 150.00 | 保密 | 2 | |
| 7 | 王祖贤 | 18 | 172.00 | 女 | 1 | |
| 8 | 周杰伦 | 36 | NULL | 男 | 1 | |
| 9 | 程坤 | 27 | 181.00 | 男 | 2 | |
| 10 | 刘亦菲 | 25 | 166.00 | 女 | 2 | |
| 11 | 金星 | 33 | 162.00 | 中性 | 3 | |
| 12 | 静香 | 12 | 180.00 | 女 | 4 | |
| 13 | 周杰 | 34 | 176.00 | 女 | 5 | |
| 14 | 郭靖 | 12 | 170.00 | 男 | 4 | |
+----+-----------+------+--------+--------+--------+-----------+
1. group by分组
使用特点:
group by的含义:将查询结果按照1个或多个字段进行分组,字段值相同的为一组
group by可用于单个字段分组,也可用于多个字段分组
select gender from students group by gender;
+--------+
| gender |
+--------+
| 男 |
| 女 |
| 中性 |
| 保密 |
+--------+
2. group_concat(字段名)
使用特点
根据分组结果,使用group_concat()来放置每一个分组中某字段的集合
select gender from students group by gender;
+--------+
| gender |
+--------+
| 男 |
| 女 |
| 中性 |
| 保密 |
+--------+ select gender,group_concat(name) from students group by gender;
+--------+-----------------------------------------------------------+
| gender | group_concat(name) |
+--------+-----------------------------------------------------------+
| 男 | 彭于晏,刘德华,周杰伦,程坤,郭靖 |
| 女 | 小明,小月月,黄蓉,王祖贤,刘亦菲,静香,周杰 |
| 中性 | 金星 |
| 保密 | 凤姐 |
+--------+-----------------------------------------------------------+ select gender,group_concat(id) from students group by gender;
+--------+------------------+
| gender | group_concat(id) |
+--------+------------------+
| 男 | 3,4,8,9,14 |
| 女 | 1,2,5,7,10,12,13 |
| 中性 | 11 |
| 保密 | 6 |
+--------+------------------+
3. group by + 聚合函数
使用特点
聚合函数在和group by结合使用的时候 统计的对象是每一个分组。
select gender,group_concat(age) from students group by gender;
+--------+----------------------+
| gender | group_concat(age) |
+--------+----------------------+
| 男 | 29,59,36,27,12 |
| 女 | 18,18,38,18,25,12,34 |
| 中性 | 33 |
| 保密 | 28 |
+--------+----------------------+ 分别统计性别为男/女的人年龄平均值
select gender,avg(age) from students group by gender;
+--------+----------+
| gender | avg(age) |
+--------+----------+
| 男 | 32.6000 |
| 女 | 23.2857 |
| 中性 | 33.0000 |
| 保密 | 28.0000 |
+--------+----------+ 分别统计性别为男/女的人的个数
select gender,count(*) from students group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| 男 | 5 |
| 女 | 7 |
| 中性 | 1 |
| 保密 | 1 |
+--------+----------+
4. group by + having
having作用和where类似,但having只能用于group by 而where是用来过滤表数据
select gender,count(*) from students group by gender having count(*)>2;
+--------+----------+
| gender | count(*) |
+--------+----------+
| 男 | 5 |
| 女 | 7 |
+--------+----------+
5. group by + with rollup
with rollup的作用是:在最后新增一行,来记录当前表中该字段对应的操作结果,一般是汇总结果。
select gender,count(*) from students group by gender with rollup;
+--------+----------+
| gender | count(*) |
+--------+----------+
| 男 | 5
| 女 | 7 |
| 中性 | 1 |
| 保密 | 1 |
| NULL | 14 |
+--------+----------+ select gender,group_concat(age) from students group by gender with rollup;
+--------+-------------------------------------------+
| gender | group_concat(age) |
+--------+-------------------------------------------+
| 男 | 29,59,36,27,12 |
| 女 | 18,18,38,18,25,12,34 |
| 中性 | 33 |
| 保密 | 28 |
| NULL | 29,59,36,27,12,18,18,38,18,25,12,34,33,28 |
+--------+-------------------------------------------+
六、连接
连接的概念
mysql支持三种类型的连接查询,分别为:
1). 内连接查询:查询的结果为两个表匹配到的数据
2). 右(外)连接查询:查询的结果为两个表匹配到的数据和右表特有的数据,对于左表中不存在的数据使用null填充
3). 左(外)连接查询:查询的结果为两个表匹配到的数据和左表特有的数据,对于右表中不存在的数据使用null填充
注意: 能够使用连接的前提是 多表之间有字段上的关联
连接查询语法
# 对于外连接 outer关键字可以省略
select * from 表1 inner或left或right join 表2 on 表1.列 运算符 表2.列
例1:使用内连接查询班级表与学生表 select * from students inner join classes on students.cls_id = classes.id;
例2:使用左连接查询班级表与学生表 # 此处使用了as为表起别名,目的是编写简单
select * from students as s left join classes as c on s.cls_id = c.id;
例3:使用右连接查询班级表与学生表 select * from students as s right join classes as c on s.cls_id = c.id;
例4:查询学生姓名及班级名称 select s.name,c.name from students as s inner join classes as c on s.cls_id = c.id;
七、自连接
- 当需要将多张"表"的相关数据汇总一个结果集中, 并且多张"表"的数据来自于同一张表
- 自连接就是一种特殊的连接方式
- 需要对表起多个不同的别名才能进行自连接查询
- 注意: 自连接可以使用交叉连接,内连接,外连接多种方式连接
八、子查询
子查询的概念
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句,外部那个select语句则称为主查询.
主查询和子查询的关系
- 子查询是嵌入到主查询中
- 子查询是辅助主查询的,要么充当条件,要么充当数据源
- 子查询是可以独立存在的语句,是一条完整的 select 语句
查询的分类
标量子查询:
- 子查询返回的结果是一个数据(一行一列)
- 子查询返回的值是max,min,avg等聚合函数得到的值作为一个数据
- 因为标量子查询只返回一个值,也可以使用其他运算符和标量子查询进行比较,如">, >=, <, <="等
# 例:查询班级学生的平均身高
select * from students where age > (select avg(age) from students);
# 其中第二个select语句就是一个标量子查询
列子查询: 返回的结果是一列(一列多行)
格式:主查询 where 条件 in (列子查询)
例: 查询还有学生在班的所有班级名字
1. 找出学生表中所有的班级 id
2. 找出班级表中对应的名字
select name from classes where id in (select cls_id from students);
行子查询: 返回的结果是一行(一行多列)
格式: 主查询 where (字段1,2,...) = (行子查询)
例: 查找班级年龄最大,身高最高的学生
行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
select * from students where (height,age) = (select max(height),max(age) from students);
九、完整的sql语句
SELECT select_expr [,select_expr,...] [
FROM tb_name
[JOIN 表名]
[ON 连接条件]
[WHERE 条件判断]
[GROUP BY {col_name | postion} [ASC | DESC], ...]
[HAVING WHERE 条件判断]
[ORDER BY {col_name|expr|postion} [ASC | DESC], ...]
[ LIMIT {[offset,]rowcount | row_count OFFSET offset}]
]
十、外键
- 外键说明
- foreign key约束指定某一个列或一组列作为外部键,其中包含外部键的表称为子表,包含外键所引用的键的表称为父表
- 外键的使用格式
- 给现有表添加外键
- alter table goods add foreign key (brand_id) references goods_brands(id);
-- 若出现1452错误
-- 错误原因:已经添加了一个不存在的cate_id值12,因此需要先删除
- 创建表时添加外键
create table goods(
表结构的内容,
foreign key(父表 #goods 结构中的字段) references 要引用的子表名(子表中的字段),
foreign key(brand_id) references goods_brands(id)
);
注意: goods 中的 cate_id 的类型一定要和 goods_cates 表中的 id 类型一致
- 删除外键约束
-- 需要先获取外键约束名称,该名称系统会自动生成,可以通过查看表创建语句来获取名称
-- 查勘表结构,表结构内 CONSTRAINT 后面就是外键名
alter table goods drop FOREIGN key 外键名;
外键使用时的注意点:
- 使用到外键约束会极大的降低表更新的效率, 所以在追求读写效率优先的场景下一般很少使用外键。
- 外键约束作用 子表中的外键字段在插入和更新 新值的时候 新值必须 在主表中相应字段出现过。
十一、 注意项
1、合理的选择数据类型
选择合理范围内最小的,因为这样可以大大减少磁盘空间及磁盘I/0读写开销,减少内存占用,减少CPU的占用率。
2、 选择相对简单的数据类型
数字类型相对字符串类型要简单的多,尤其是在比较运算时,所以我们应该选择最简单的数据类型。
3、列属性尽量为 NOT NULL
MYSQL对NULL字段优化不佳,增加更多的计算难度,同时在保存与处理NULL类形时,也会做更多的工作,所以从效率上来说,不建议用过多的NULL。
有些值他确实有可能没有值,怎么办呢?解决方法是数值弄用整数0,字符串用""来定义默认值即可。
4、int(10)是什么含义
代表显示宽度,整数列的显示宽度与mysql需要用多少个字符来显示该列数值,与该整数需要的存储空间的大小都没有关系。
比如,不管设定了显示宽度是多少个字符,int都要占用4个字节。
SQL查询语句的进阶使用的更多相关文章
- sql查询语句如何解析成分页查询?
我们公司主要mysql存储数据,因此也封装了比较好用mysql通用方法,然后,我们做大量接口,在处理分页查询接口,没有很好分查询方法.sql查询 语句如何解析成“分页查询”和“总统计”两条语句.可能, ...
- 15个初学者必看的基础SQL查询语句
本文由码农网 – 小峰原创翻译,转载请看清文末的转载要求,欢迎参与我们的付费投稿计划! 本文将分享15个初学者必看的基础SQL查询语句,都很基础,但是你不一定都会,所以好好看看吧. 1.创建表和数据插 ...
- SQL查询语句去除重复行
1.存在两条完全相同的纪录 这是最简单的一种情况,用关键字distinct就可以去掉 select distinct * from table(表名) where (条件) 2.存在部分字段相同的纪录 ...
- WordPress 常用数据库SQL查询语句大全
在使用WordPress的过程中,我们少不了要对数据库进行修改操作,比如,更换域名.修改附件目录.批量修改文章内容等等.这个时候,使用SQL查询语句可以大大简化我们的工作量. 关于如何操作SQL查询语 ...
- (转)经典SQL查询语句大全
(转)经典SQL查询语句大全 一.基础1.说明:创建数据库CREATE DATABASE database-name2.说明:删除数据库drop database dbname3.说明:备份sql s ...
- 转: 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- 经典SQL查询语句大全
一.基础1.说明:创建数据库CREATE DATABASE database-name2.说明:删除数据库drop database dbname3.说明:备份sql server--- 创建 备份数 ...
- oracle中sql查询语句的执行顺序
查询语句的处理过程主要包含3个阶段:编译.执行.提取数据(sql查询语句的处理主要是由用户进程和服务器进程完成的,其他进程辅助配合) 一.编译parse 在进行编译时服务器进程会将sql语句的正文放入 ...
- SQL查询语句分类
SQL查询语句有多种,下面总结下.首先先建三张表用于后面的实验 -- 学生表,记录学生信息 CREATE TABLE student( sno ), sname ), ssex ENUM('男','女 ...
随机推荐
- CMake--常用指令
1 . ADD_DEFINITIONS 向 C/C++ 编译器添加 -D 定义,比如 在CMakeList.txt文件中添加: ADD_DEFINITIONS(-DENABLE_DEBUG -DABC ...
- C++中String类的字符串分割实现
最近笔试,经常遇到需要对字符串进行快速分割的情景,主要是在处理输入的时候,而以前练习算法题或笔试,很多时候不用花啥时间考虑测试用例输入的问题.可是C++标准库里面没有像java的String类中提供的 ...
- 剑指offer(11)
题目: 输入一个链表,输出该链表中倒数第k个结点. 思路: 我们一先想到的应该是循环两次链表,第一次获得它的长度,然后用长度-k,得出目标节点在链表的第几位,再循环一次. 如果要求只用一次循环的话,我 ...
- spring boot中常用的配置文件的重写
@Configuration public class viewConfigSolver extends WebMvcConfigurerAdapter { /* spring boot 已经自动配置 ...
- 区分Python中的id()和is以及Python中字符串的intern机制
参考:1. https://blog.csdn.net/lnotime/article/details/81194633 2.https://segmentfault.com/q/1010000015 ...
- python学习笔记(9)--函数
函数定义: def <函数名>(<参数(0个或多个)>): 函数体 return <返回值> 参数有非可选参数,和可选参数,可选参数放在参数列表的最后,可以为可选参 ...
- 死锁问题分析(个人认为重点讲到了gap间隙锁,解决了我一些不明报死锁的问题)
线上某服务时不时报出如下异常(大约一天二十多次):“Deadlock found when trying to get lock;”. Oh, My God! 是死锁问题.尽管报错不多,对性能目前看来 ...
- python数学第四天【古典概型】
- vs code安装
vs code是一款文本编辑器,开源,是前端界的vs,而Dreamweaver适合入门. user版本的一些系统分区文件夹无法创建,可能存在语言显示问题.一般用户建议使用system版. 下载链接:h ...
- spring boot和swagger 整合
本文来源:https://blog.csdn.net/saytime/article/details/74937664 一.依赖 <dependency> <groupId>i ...