Appearance-and-Relation Networks for Video Classification论文笔记 (ARTnet)
ARTnet:
caffe实现:代码
1 Motivation:How to model appearance and relation (motion)
主要工作是在3D卷积的基础上,提升了action recognition的准确率,没有使用光流信息,因为光流的提取速度特别慢,这可能是未来的研究趋势,该方法更不会像IDT那套方法一样计算复杂。
实验以C3D-ResNet18实现的,只以rgb为输入,训练的时候采用了TSN的稀疏采样策略。appearance分支对每帧图片提取特征(可以看作two-stream中RGB流)。relation分支利用multiplicative interactions对多帧提取特征,用于捕获帧与帧之间的关系
ARTNet主要是由SMART blocks 通过堆叠的方法组合起来,就好像ResNet主要是由Residual blocks组合起来一样。它是一种直接输入RGB视频图像的端到端的视频理解模型。
ARTNet在Kinetics上实验的结果表明,仅通过RGB的输入,train from scratch, 能够达到RGB上state-of-the-art的性能
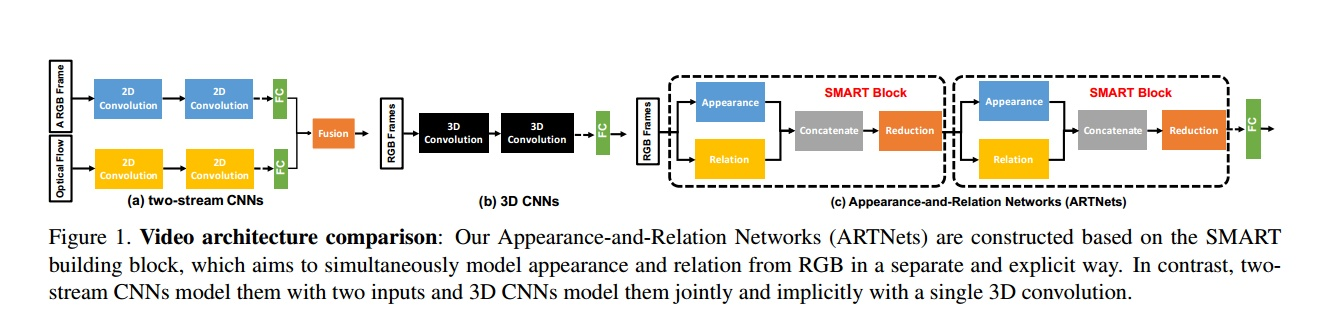
模型深挖rgb中的 appearance 和 relation 信息,smart模块对这个两个信息解耦独立建模后融合,上图可以看出,ARTnet利用了双流和c3d各自的优点。
2.1 Multiplicative interaction的数学原理
假设在连续帧上有两个patches,x和y,我们的目标是学习它们之间的变换关系z。一个常见的解决方案是将两个patches concat起来然后进行特征学习,就像3D conv一样: 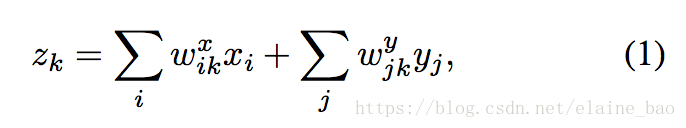
这里学到的zk就是[x,y]和参数w=[wx.k,xy.k]之间的线性组合。然而,这种情况下z的取值是依赖于patches的appearance的而不仅仅是依赖于它们之间的relation。也就是说如果两个patches改变了它们的appearance特征但是没有改变它们之间的时序关系,z的取值也是会发生变化的,因此这个解决方案将appearance和relation的信息结合起来了,这可能导致建模的困难并且增加过拟合的风险。
如双流网络中,假设appearance和relation之间是相互独立的,则可以将两者分开建模。x和y的乘积就能很容易地实现 appearance-independent relation detector,此时zk的形式如下: 
是一个x和y和weight的二次方程, 也就是x和y的外积。这样zk的每个元素都表示x和y之间的一种关系,保证了zk主要受两者relation之间的影响。
Factorization and energy models. (2)式实现起来的一个主要问题是它的参数量相当于像素个数的立方,将其因式分解成3个矩阵能够有效地减少参数量,
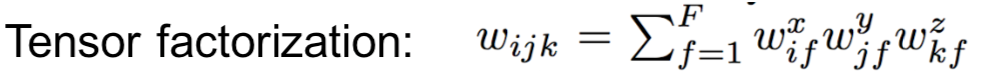
所以(2)式就可以写成:
这个因式分解的公式和energy model很相关,并且可以被表示成energy model的形式。具体地,在energy model中的一个隐含单元zk是通过以下公式计算的:
看出第一项和(3)式一样的,后面2项二次项不会有很大的影响,可以忽略。energy model可以通过3D CNNs实现,并且可以很容易地是一层一层地叠加。
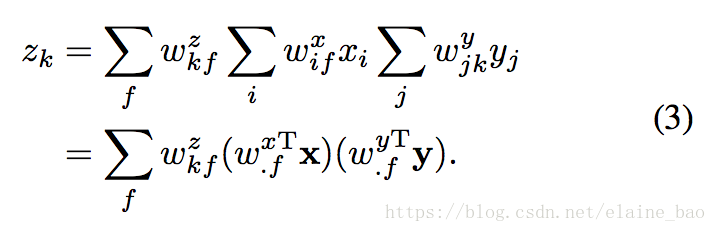
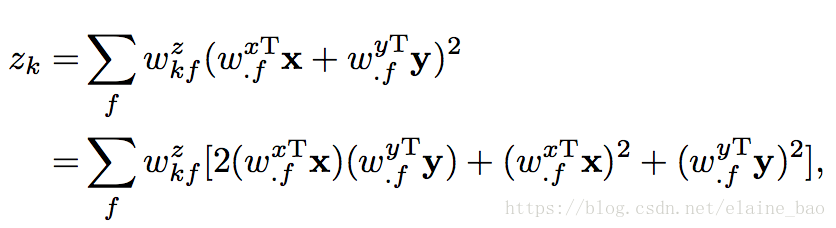
3 网络结构
本文的一大亮点是能量模型,使用了一种近似square-pooling的结构。与原结构不同之处在于三点:第一,从无监督到了有监督;第二,从仅有relation到有appearance和relation;第三,从单层到stacking多层。

appearance分支对位置结构建模,relation分支对时域关系建模
relation分支:C3D加上relation model,其中relation model用到了square-pooling,以及1*1*1的卷积实现的cross-channel-pooling,最后fusion,concat.
cross-channel pooling等于对子空间做sum操作,论文中讲子空间设为2(对应channel的feature map和其相邻的feature map加和),pooling的权重是固定的0.5
其中Z的通道数是U的一半,而U和F通道数相同。reduction layer 的输出channel和appearance的channel一致

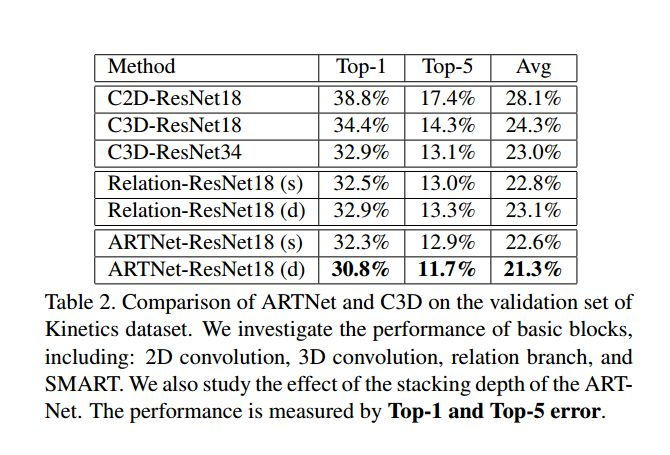
这是三种模型结构,第一种是C3D-ResNet18;第二种是ARTNet-ResNet18(s),就是只在第一层conv换成smart;第三种是ARTNet-ResNet18(d),就是每一层conv都换成smart.
实现细节
训练网络:
bactchsize=256, momentum=0.9, SGD, framed大小128*170,input size112*112*16, 初始学习率为0.1,每当val loss不下降就降10倍。在Kinetics上的总iteration为250000。为减少过拟合,在fc层前加了dropout=0.2。
测试网络:
从整个视频中采样250个clips,具体是随机采取25个128*170*16的clips, 然后10crops(5crops加上水平反转,5crops是中间加上四个角),最后取这250个的平均。
4.实验
文章大部分实验都是在kinetics完成,模型都是从kinetics上train from scratch得到
4.1数据集
(1)Kinectics (2)UCF101 (3)HMDB51
4.2 Kinectics 实验结果
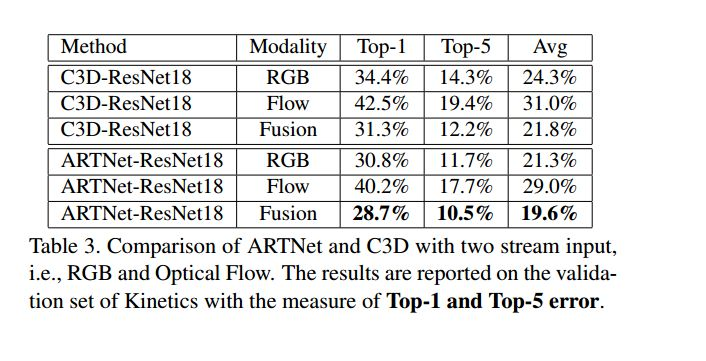
two-stream还是明显有效果的,说明SMART结构提取到的时间空间域的信息和光流还是互补的。值得一提的是ARTNet-ResNet18基于RGB的结果比C3D-ResNet18基于Fusion的结构还要好一些。

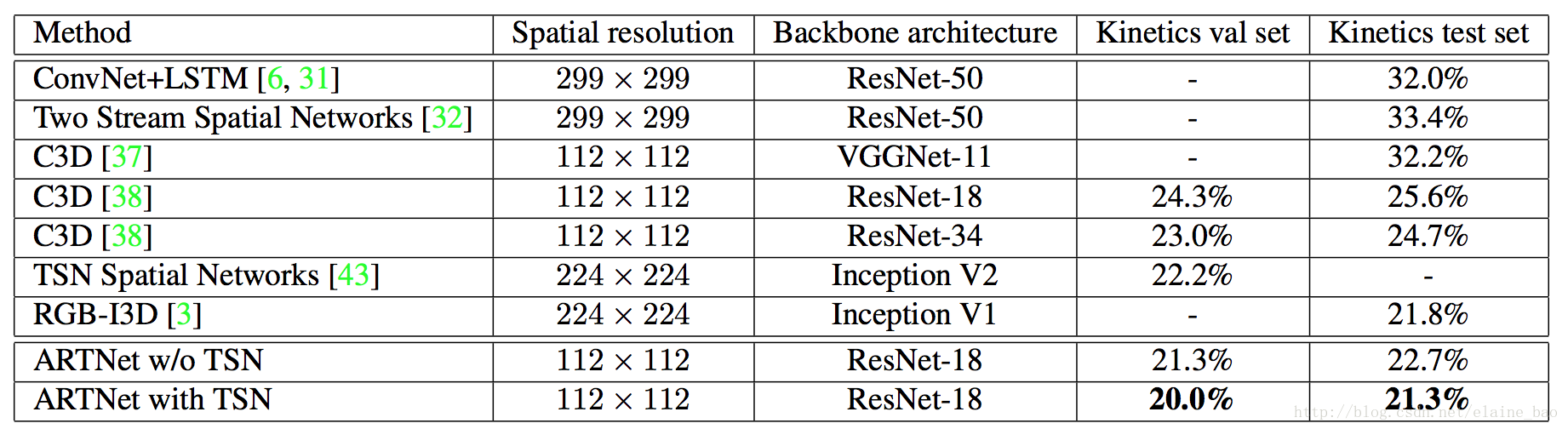
4.3 和其他state-of-the-art模型的对比
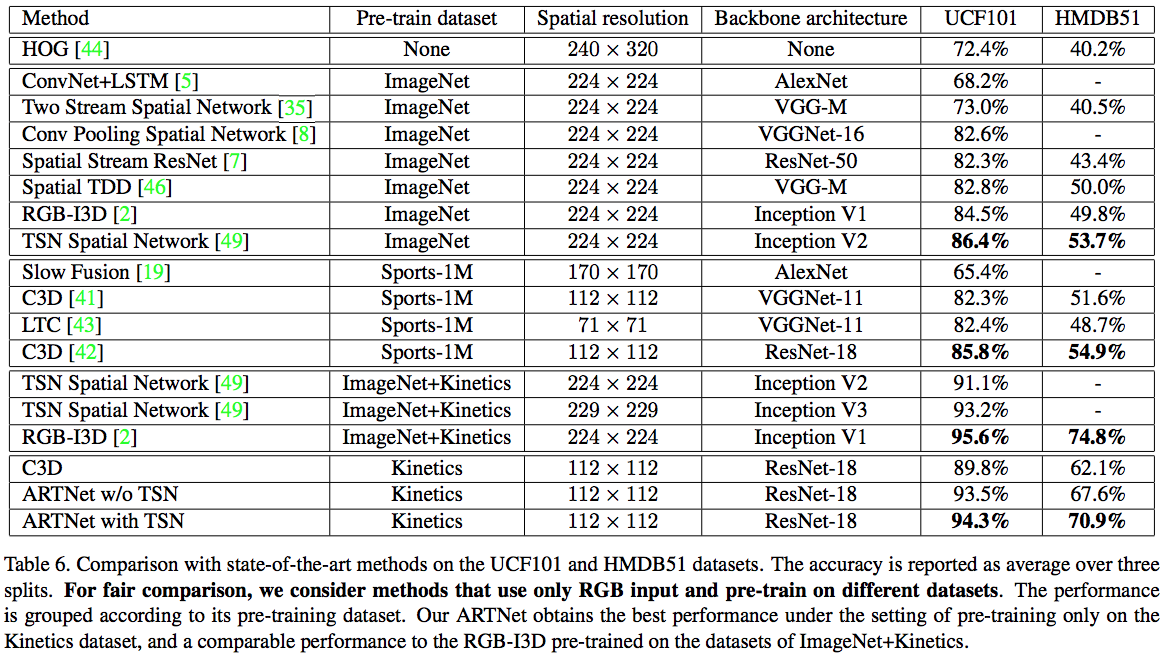
4.4 UCF101 和 HMDB51 上对比,可以看到接近RGB-I3D的结果
4.5 结论和展望
和C3D相比已经有了显著的提升,但是相比于two-stream仍然有差距,为了缩小这种差距,未来尝试更深的网络和更大的分辨率
部分转自:知乎-思考中的哈士奇
公式解读转自 Elaine-Bao
Appearance-and-Relation Networks for Video Classification论文笔记 (ARTnet)的更多相关文章
- Learning to Compare: Relation Network for Few-Shot Learning 论文笔记
主要原理: 和Siamese Neural Networks一样,将分类问题转换成两个输入的相似性问题. 和Siamese Neural Networks不同的是: Relation Network中 ...
- 卷积神经网络用语句子分类---Convolutional Neural Networks for Sentence Classification 学习笔记
读了一篇文章,用到卷积神经网络的方法来进行文本分类,故写下一点自己的学习笔记: 本文在事先进行单词向量的学习的基础上,利用卷积神经网络(CNN)进行句子分类,然后通过微调学习任务特定的向量,提高性能. ...
- 论文解读(DropEdge)《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》
论文信息 论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification论文作者:Yu Rong, We ...
- 论文翻译——Character-level Convolutional Networks for Text Classification
论文地址 Abstract Open-text semantic parsers are designed to interpret any statement in natural language ...
- CVPR2020论文解析:视频分类Video Classification
CVPR2020论文解析:视频分类Video Classification Rethinking Zero-shot Video Classification: End-to-end Training ...
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 20 ...
- Notes on Large-scale Video Classification with Convolutional Neural Networks
Use bigger datasets for CNN in hope of better performance. A new data set for sports video classific ...
- Paper Reading: Relation Networks for Object Detection
Relation Networks for Object Detection笔记 写在前面:关于这篇论文的背景知识,请参考我前面的两篇随笔(<关于目标检测>和<关于注意力机制> ...
- Spatial-Temporal Relation Networks for Multi-Object Tracking
Spatial-Temporal Relation Networks for Multi-Object Tracking 2019-05-21 11:07:49 Paper: https://arxi ...
随机推荐
- 【转】vector中erase()的使用注意事项
vector::erase():从指定容器删除指定位置的元素或某段范围内的元素 vector::erase()方法有两种重载形式 如下: iterator erase( iterator _Whe ...
- hibernate框架学习之核心API
ConfigurationSessionFactorySessionTransactionQueryCriteria Configuration Configuration对象用于封装Hibernat ...
- Alpha 冲刺 (4/10)
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:冲刺4 团队部分 后敬甲 过去两天完成了哪些任务 文字描述 主页部分图标的替换 -拍照按钮的设计和测试 GitHub代码 ...
- which命令和bin目录
命令: which 作用: 查看执行命令所在位置 使用: which ls which useradd 等等... bin和sbin: 绝大多数可执行文件都保存在 /bin./sbin./usr/bi ...
- 每天备份tomcat日志
#!/bin/bash Backup_Home=/data/backup-log mkdir -p $Backup_Home Log_Home=/data/Tomcat/logs App_Log_Ho ...
- Flask允许跨域
什么是跨域 在 HTML 中,<a>, <form>, <img>, <script>, <iframe>, <link> 等标 ...
- The word 'localhost' is not correctly spelled 这个问题怎么解决
The word 'localhost' is not correctly spelled 这个问题怎么解决 有时工程中有下划线并提示 The word is not correctly spelle ...
- Java 的 Api 文档生成工具 JApiDocs 程序文档工具
JApiDocs 详细介绍 简介 JApiDocs 是一个符合 Java 编程习惯的 Api 文档生成工具.最大程度地利用 Java 的语法特性,你只管用心设计好接口,添加必要的注释,JApiDocs ...
- Oracle12c从入门到精通(第二版) PDF 下载
一:下载地址: 二:本书图样 三本书目录 前言 第一章 Oracle数据库概述 第二章 Oracle在Windows 8上的安装与配置 第三章 SQL基础 第四章 Oracle PL/SQL及编程 第 ...
- Swift 通过字符串创建控制器
由于Swift 中新增了一个命名空间(在同一个命名空间中的文件可以直接访问而不用引入头文件)的概念 所以通过字符串创建控制器需要带上命名空间 1 首先为Bundle 写一个分类 获取命名空间 ext ...