Expectation Maximization-EM(期望最大化)-算法以及源码
在统计计算中,最大期望(EM)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。最大期望经常用在机器学习和计算机视觉的数据聚类(Data Clustering) 领域。最大期望算法经过两个步骤交替进行计算,第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;第二步是最大化(M),最大 化在 E 步上求得的最大似然值来计算参数的值。M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
最大期望值算法由 Arthur Dempster,Nan Laird和Donald Rubin在他们1977年发表的经典论文中提出。他们指出此方法之前其实已经被很多作者"在他们特定的研究领域中多次提出过"。
我们用 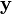 表示能够观察到的不完整的变量值,用
表示能够观察到的不完整的变量值,用  表示无法观察到的变量值,这样 和 一起组成了完整的数据。 可能是实际测量丢失的数据,也可能是能够简化问题的隐藏变量,如果它的值能够知道的话。例如,在混合模型(Mixture Model)中,如果“产生”样本的混合元素成分已知的话最大似然公式将变得更加便利(参见下面的例子)。
表示无法观察到的变量值,这样 和 一起组成了完整的数据。 可能是实际测量丢失的数据,也可能是能够简化问题的隐藏变量,如果它的值能够知道的话。例如,在混合模型(Mixture Model)中,如果“产生”样本的混合元素成分已知的话最大似然公式将变得更加便利(参见下面的例子)。
估计无法观测的数据
让  代表矢量 θ:
代表矢量 θ: 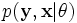 定义的参数的全部数据的概率分布(连续情况下)或者概率聚类函数(离散情况下),那么从这个函数就可以得到全部数据的最大似然值,另外,在给定的观察到的数据条件下未知数据的条件分布可以表示为:
定义的参数的全部数据的概率分布(连续情况下)或者概率聚类函数(离散情况下),那么从这个函数就可以得到全部数据的最大似然值,另外,在给定的观察到的数据条件下未知数据的条件分布可以表示为:
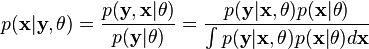
EM算法有这么两个步骤E和M:
- Expectation step: Choose q to maximize F:
- Maximization step: Choose θ to maximize F:


举个例子吧:高斯混合
假设 x = (x1,x2,…,xn) 是一个独立的观测样本,来自两个多元d维正态分布的混合, 让z=(z1,z2,…,zn)是潜在变量,确定其中的组成部分,是观测的来源.
即:
 and
and 
where
 and
and 
目标呢就是估计下面这些参数了,包括混合的参数以及高斯的均值很方差:

似然函数:

where  是一个指示函数 ,f 是 一个多元正态分布的概率密度函数. 可以写成指数形式:
是一个指示函数 ,f 是 一个多元正态分布的概率密度函数. 可以写成指数形式:

下面就进入两个大步骤了:
E-step
给定目前的参数估计 θ(t), Zi 的条件概率分布是由贝叶斯理论得出,高斯之间用参数 τ加权:
 .
.
因此,E步骤的结果:

M步骤
Q(θ|θ(t))的二次型表示可以使得 最大化θ相对简单. τ, (μ1,Σ1) and (μ2,Σ2) 可以单独的进行最大化.
首先考虑 τ, 有条件τ1 + τ2=1:

和MLE的形式是类似的,二项分布 , 因此:

下一步估计 (μ1,Σ1):

和加权的 MLE就正态分布来说类似
 and
and 
对称的:
 and
and  .
.
这个例子来自Answers.com的Expectation-maximization algorithm,由于还没有深入体验,心里还说不出一些更通俗易懂的东西来,等研究了并且应用了可能就有所理解和消化。另外,liuxqsmile也做了一些理解和翻译。
============
在网上的源码不多,有一个很好的EM_GM.m,是滑铁卢大学的Patrick P. C. Tsui写的,拿来分享一下:
运行的时候可以如下进行初始化:
% matlab code
X = zeros(,);
X(:,:) = normrnd(,,,);
X(:,:) = normrnd(,,,);
X(:,:) = normrnd(,,,);
[W,M,V,L] = EM_GM(X,,[],[],,[])
下面是程序源码:
%matlab code function [W,M,V,L] = EM_GM(X,k,ltol,maxiter,pflag,Init)
% [W,M,V,L] = EM_GM(X,k,ltol,maxiter,pflag,Init)
%
% EM algorithm for k multidimensional Gaussian mixture estimation
%
% Inputs:
% X(n,d) - input data, n=number of observations, d=dimension of variable
% k - maximum number of Gaussian components allowed
% ltol - percentage of the log likelihood difference between iterations ([] for none)
% maxiter - maximum number of iteration allowed ([] for none)
% pflag - for plotting GM for 1D or 2D cases only, otherwise ([] for none)
% Init - structure of initial W, M, V: Init.W, Init.M, Init.V ([] for none)
%
% Ouputs:
% W(,k) - estimated weights of GM
% M(d,k) - estimated mean vectors of GM
% V(d,d,k) - estimated covariance matrices of GM
% L - log likelihood of estimates
%
% Written by
% Patrick P. C. Tsui,
% PAMI research group
% Department of Electrical and Computer Engineering
% University of Waterloo,
% March,
% %%%% Validate inputs %%%%
if nargin <= ,
disp('EM_GM must have at least 2 inputs: X,k!/n')
return
elseif nargin == ,
ltol = 0.1; maxiter = ; pflag = ; Init = [];
err_X = Verify_X(X);
err_k = Verify_k(k);
if err_X | err_k, return; end
elseif nargin == ,
maxiter = ; pflag = ; Init = [];
err_X = Verify_X(X);
err_k = Verify_k(k);
[ltol,err_ltol] = Verify_ltol(ltol);
if err_X | err_k | err_ltol, return; end
elseif nargin == ,
pflag = ; Init = [];
err_X = Verify_X(X);
err_k = Verify_k(k);
[ltol,err_ltol] = Verify_ltol(ltol);
[maxiter,err_maxiter] = Verify_maxiter(maxiter);
if err_X | err_k | err_ltol | err_maxiter, return; end
elseif nargin == ,
Init = [];
err_X = Verify_X(X);
err_k = Verify_k(k);
[ltol,err_ltol] = Verify_ltol(ltol);
[maxiter,err_maxiter] = Verify_maxiter(maxiter);
[pflag,err_pflag] = Verify_pflag(pflag);
if err_X | err_k | err_ltol | err_maxiter | err_pflag, return; end
elseif nargin == ,
err_X = Verify_X(X);
err_k = Verify_k(k);
[ltol,err_ltol] = Verify_ltol(ltol);
[maxiter,err_maxiter] = Verify_maxiter(maxiter);
[pflag,err_pflag] = Verify_pflag(pflag);
[Init,err_Init]=Verify_Init(Init);
if err_X | err_k | err_ltol | err_maxiter | err_pflag | err_Init, return; end
else
disp('EM_GM must have 2 to 6 inputs!');
return
end %%%% Initialize W, M, V,L %%%%
t = cputime;
if isempty(Init),
[W,M,V] = Init_EM(X,k); L = ;
else
W = Init.W;
M = Init.M;
V = Init.V;
end
Ln = Likelihood(X,k,W,M,V); % Initialize log likelihood
Lo = *Ln; %%%% EM algorithm %%%%
niter = ;
while (abs(*(Ln-Lo)/Lo)>ltol) & (niter<=maxiter),
E = Expectation(X,k,W,M,V); % E-step
[W,M,V] = Maximization(X,k,E); % M-step
Lo = Ln;
Ln = Likelihood(X,k,W,M,V);
niter = niter + ;
end
L = Ln; %%%% Plot 1D or 2D %%%%
if pflag==,
[n,d] = size(X);
if d>,
disp('Can only plot 1 or 2 dimensional applications!/n');
else
Plot_GM(X,k,W,M,V);
end
elapsed_time = sprintf('CPU time used for EM_GM: %5.2fs',cputime-t);
disp(elapsed_time);
disp(sprintf('Number of iterations: %d',niter-));
end
%%%%%%%%%%%%%%%%%%%%%%
%%%% End of EM_GM %%%%
%%%%%%%%%%%%%%%%%%%%%% function E = Expectation(X,k,W,M,V)
[n,d] = size(X);
a = (*pi)^(0.5*d);
S = zeros(,k);
iV = zeros(d,d,k);
for j=:k,
if V(:,:,j)==zeros(d,d), V(:,:,j)=ones(d,d)*eps; end
S(j) = sqrt(det(V(:,:,j)));
iV(:,:,j) = inv(V(:,:,j));
end
E = zeros(n,k);
for i=:n,
for j=:k,
dXM = X(i,:)'-M(:,j);
pl = exp(-0.5*dXM'*iV(:,:,j)*dXM)/(a*S(j));
E(i,j) = W(j)*pl;
end
E(i,:) = E(i,:)/sum(E(i,:));
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Expectation %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%% function [W,M,V] = Maximization(X,k,E)
[n,d] = size(X);
W = zeros(,k); M = zeros(d,k);
V = zeros(d,d,k);
for i=:k, % Compute weights
for j=:n,
W(i) = W(i) + E(j,i);
M(:,i) = M(:,i) + E(j,i)*X(j,:)';
end
M(:,i) = M(:,i)/W(i);
end
for i=:k,
for j=:n,
dXM = X(j,:)'-M(:,i);
V(:,:,i) = V(:,:,i) + E(j,i)*dXM*dXM';
end
V(:,:,i) = V(:,:,i)/W(i);
end
W = W/n;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Maximization %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%% function L = Likelihood(X,k,W,M,V)
% Compute L based on K. V. Mardia, "Multivariate Analysis", Academic Press, , PP. -
% to enchance computational speed
[n,d] = size(X);
U = mean(X)';
S = cov(X);
L = ;
for i=:k,
iV = inv(V(:,:,i));
L = L + W(i)*(-0.5*n*log(det(*pi*V(:,:,i))) ...
-0.5*(n-)*(trace(iV*S)+(U-M(:,i))'*iV*(U-M(:,i))));
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Likelihood %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%% function err_X = Verify_X(X)
err_X = ;
[n,d] = size(X);
if n<d,
disp('Input data must be n x d!/n');
return
end
err_X = ;
%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_X %%%%
%%%%%%%%%%%%%%%%%%%%%%%%% function err_k = Verify_k(k)
err_k = ;
if ~isnumeric(k) | ~isreal(k) | k<,
disp('k must be a real integer >= 1!/n');
return
end
err_k = ;
%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_k %%%%
%%%%%%%%%%%%%%%%%%%%%%%%% function [ltol,err_ltol] = Verify_ltol(ltol)
err_ltol = ;
if isempty(ltol),
ltol = 0.1;
elseif ~isreal(ltol) | ltol<=,
disp('ltol must be a positive real number!');
return
end
err_ltol = ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_ltol %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%% function [maxiter,err_maxiter] = Verify_maxiter(maxiter)
err_maxiter = ;
if isempty(maxiter),
maxiter = ;
elseif ~isreal(maxiter) | maxiter<=,
disp('ltol must be a positive real number!');
return
end
err_maxiter = ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_maxiter %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% function [pflag,err_pflag] = Verify_pflag(pflag)
err_pflag = ;
if isempty(pflag),
pflag = ;
elseif pflag~= & pflag~=,
disp('Plot flag must be either 0 or 1!/n');
return
end
err_pflag = ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_pflag %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%% function [Init,err_Init] = Verify_Init(Init)
err_Init = ;
if isempty(Init),
% Do nothing;
elseif isstruct(Init),
[Wd,Wk] = size(Init.W);
[Md,Mk] = size(Init.M);
[Vd1,Vd2,Vk] = size(Init.V);
if Wk~=Mk | Wk~=Vk | Mk~=Vk,
disp('k in Init.W(1,k), Init.M(d,k) and Init.V(d,d,k) must equal!/n')
return
end
if Md~=Vd1 | Md~=Vd2 | Vd1~=Vd2,
disp('d in Init.W(1,k), Init.M(d,k) and Init.V(d,d,k) must equal!/n')
return
end
else
disp('Init must be a structure: W(1,k), M(d,k), V(d,d,k) or []!');
return
end
err_Init = ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Verify_Init %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%% function [W,M,V] = Init_EM(X,k)
[n,d] = size(X);
[Ci,C] = kmeans(X,k,'Start','cluster', ...
'Maxiter',, ...
'EmptyAction','drop', ...
'Display','off'); % Ci(nx1) - cluster indeices; C(k,d) - cluster centroid (i.e. mean)
while sum(isnan(C))>,
[Ci,C] = kmeans(X,k,'Start','cluster', ...
'Maxiter',, ...
'EmptyAction','drop', ...
'Display','off');
end
M = C';
Vp = repmat(struct('count',,'X',zeros(n,d)),,k);
for i=:n, % Separate cluster points
Vp(Ci(i)).count = Vp(Ci(i)).count + ;
Vp(Ci(i)).X(Vp(Ci(i)).count,:) = X(i,:);
end
V = zeros(d,d,k);
for i=:k,
W(i) = Vp(i).count/n;
V(:,:,i) = cov(Vp(i).X(:Vp(i).count,:));
end
%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Init_EM %%%%
%%%%%%%%%%%%%%%%%%%%%%%% function Plot_GM(X,k,W,M,V)
[n,d] = size(X);
if d>,
disp('Can only plot 1 or 2 dimensional applications!/n');
return
end
S = zeros(d,k);
R1 = zeros(d,k);
R2 = zeros(d,k);
for i=:k, % Determine plot range as x standard deviations
S(:,i) = sqrt(diag(V(:,:,i)));
R1(:,i) = M(:,i)-*S(:,i);
R2(:,i) = M(:,i)+*S(:,i);
end
Rmin = min(min(R1));
Rmax = max(max(R2));
R = [Rmin:0.001*(Rmax-Rmin):Rmax];
clf, hold on
if d==,
Q = zeros(size(R));
for i=:k,
P = W(i)*normpdf(R,M(:,i),sqrt(V(:,:,i)));
Q = Q + P;
plot(R,P,'r-'); grid on,
end
plot(R,Q,'k-');
xlabel('X');
ylabel('Probability density');
else % d==
plot(X(:,),X(:,),'r.');
for i=:k,
Plot_Std_Ellipse(M(:,i),V(:,:,i));
end
xlabel('1^{st} dimension');
ylabel('2^{nd} dimension');
axis([Rmin Rmax Rmin Rmax])
end
title('Gaussian Mixture estimated by EM');
%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Plot_GM %%%%
%%%%%%%%%%%%%%%%%%%%%%%% function Plot_Std_Ellipse(M,V)
[Ev,D] = eig(V);
d = length(M);
if V(:,:)==zeros(d,d),
V(:,:) = ones(d,d)*eps;
end
iV = inv(V);
% Find the larger projection
P = [,;,]; % X-axis projection operator
P1 = P * *sqrt(D(,)) * Ev(:,);
P2 = P * *sqrt(D(,)) * Ev(:,);
if abs(P1()) >= abs(P2()),
Plen = P1();
else
Plen = P2();
end
count = ;
step = 0.001*Plen;
Contour1 = zeros(,);
Contour2 = zeros(,);
for x = -Plen:step:Plen,
a = iV(,);
b = x * (iV(,)+iV(,));
c = (x^) * iV(,) - ;
Root1 = (-b + sqrt(b^ - *a*c))/(*a);
Root2 = (-b - sqrt(b^ - *a*c))/(*a);
if isreal(Root1),
Contour1(count,:) = [x,Root1] + M';
Contour2(count,:) = [x,Root2] + M';
count = count + ;
end
end
Contour1 = Contour1(:count-,:);
Contour2 = [Contour1(,:);Contour2(:count-,:);Contour1(count-,:)];
plot(M(),M(),'k+');
plot(Contour1(:,),Contour1(:,),'k-');
plot(Contour2(:,),Contour2(:,),'k-');
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%% End of Plot_Std_Ellipse %%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
from: http://www.zhizhihu.com/html/y2010/2109.html
Expectation Maximization-EM(期望最大化)-算法以及源码的更多相关文章
- EM 期望最大化算法
(EM算法)The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用到了. ...
- GWO(灰狼优化)算法MATLAB源码逐行中文注解(转载)
以优化SVM算法的参数c和g为例,对GWO算法MATLAB源码进行了逐行中文注解. tic % 计时器 %% 清空环境变量 close all clear clc format compact %% ...
- SURF算法与源码分析、下
上一篇文章 SURF算法与源码分析.上 中主要分析的是SURF特征点定位的算法原理与相关OpenCV中的源码分析,这篇文章接着上篇文章对已经定位到的SURF特征点进行特征描述.这一步至关重要,这是SU ...
- 6种基础排序算法java源码+图文解析[面试宝典]
一.概述 作为一个合格的程序员,算法是必备技能,特此总结6大基础算法.java版强烈推荐<算法第四版>非常适合入手,所有算法网上可以找到源码下载. PS:本文讲解算法分三步:1.思想2.图 ...
- 十大基础排序算法[java源码+动静双图解析+性能分析]
一.概述 作为一个合格的程序员,算法是必备技能,特此总结十大基础排序算法.java版源码实现,强烈推荐<算法第四版>非常适合入手,所有算法网上可以找到源码下载. PS:本文讲解算法分三步: ...
- SURF算法与源码分析、上
如果说SIFT算法中使用DOG对LOG进行了简化,提高了搜索特征点的速度,那么SURF算法则是对DoH的简化与近似.虽然SIFT算法已经被认为是最有效的,也是最常用的特征点提取的算法,但如果不借助于硬 ...
- 三种排序算法python源码——冒泡排序、插入排序、选择排序
最近在学习python,用python实现几个简单的排序算法,一方面巩固一下数据结构的知识,另一方面加深一下python的简单语法. 冒泡排序算法的思路是对任意两个相邻的数据进行比较,每次将最小和最大 ...
- Java数据结构和算法 - TreeMap源码理解红黑树
前言 本篇将结合JDK1.6的TreeMap源码,来一起探索红-黑树的奥秘.红黑树是解决二叉搜索树的非平衡问题. 当插入(或者删除)一个新节点时,为了使树保持平衡,必须遵循一定的规则,这个规则就是红- ...
- faster rcnn算法及源码及论文解析相关博客
1. 通过代码理解faster-RCNN中的RPN http://blog.csdn.net/happyflyy/article/details/54917514 2. faster rcnn详解 R ...
随机推荐
- centos7 关闭默认firewalld,开启iptables
编者按: 对于使用了centos6系列系统N年的运维来说,在使用centos7的时候难免会遇到各种不适应.比如防火墙问题.本文主要记录怎么关闭默认的firewalld防火墙,重新启用iptables. ...
- log4j:WARN No appenders could be found for logger (org.springframework.web.context.ContextLoader).
一.异常描述: log4j:WARN No appenders could be found for logger (org.springframework.web.context.ContextLo ...
- linux保证程序单实例运行
static int proc_detect(const char *procname){ char filename[100] = {0}; sprintf(filename, "%s/% ...
- 5.5版本以上”No input file specified“问题解决
.htaccess文件中的 RewriteRule ^(.*)$ index.php/$1 [QSA,PT,L] 在默认情况下会导致No input file specified. 修改成 Rewri ...
- React Native性能优化之可取消的异步操作
前沿 在前端的项目开发中,异步操作是一个不可获取的,从用户的角度来说,异步操作所带来的体验是美妙的,但有时候也会带来一些性能隐患.比如说:有一个异步请求还没有返回结果,但是页面却关闭了,这时由于异步操 ...
- CSUOJ 1011 Counting Pixels
Description Did you know that if you draw a circle that fills the screen on your 1080p high definiti ...
- 一文搞定 Mybatis 的应用
Mybatis 介绍 Mybatis 是一个开源的持久层框架,原来叫 ibatis ,它对 jdbc 操作数据库的过程进行了封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动. ...
- IdentityServer4之JWT签名(RSA加密证书)及验签
一.前言 在IdentityServer4中有两种令牌,一个是JWT和Reference Token,在IDS4中默认用的是JWT,那么这两者有什么区别呢? 二.JWT与Reference Token ...
- ICMP隧道工具ptunnel
ICMP隧道工具ptunnel 在一些网络环境中,如果不经过认证,TCP和UDP数据包都会被拦截.如果用户可以ping通远程计算机,就可以尝试建立ICMP隧道,将TCP数据通过该隧道发送,实现不受 ...
- iOS 11开发教程(六)iOS11Main.storyboard文件编辑界面
iOS 11开发教程(六)iOS11Main.storyboard文件编辑界面 在1.2.2小节中提到过编辑界面(Interface builder),编辑界面是用来设计用户界面的,单击打开Main. ...