J03-Java IO流总结三 《 FileInputStream和FileOutputStream 》
1. FileInputStream
FileInputStream是一个文件输入节点流,它是一个字节流,它的作用是将磁盘文件的内容读取到内存中。
FileInputStream的父类是InputStream。
该类的源码感觉不用细看,因为它是节点流,已经是相对底层的了,读源码没法读出来它是怎么实现的。
下面是该类的两种简单用法,分别是使用read()和read(byte[] buf)方法来读取流数据。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException; public class FileInputStreamTest {
public static void main(String[] args) {
System.out.println("一个一个字节地读取的效果:");
test1(); System.out.println("\n通过字节数组读取的效果:");
test2();
} //////////////////////////////////////////////////////////////////////
/**
* 使用read()方法,一个字节一个字节地读取
*/
private static void test1() {
FileInputStream fis = null; try {
fis = new FileInputStream("./src/res/1.txt");
int value = 0; while(-1 != (value = fis.read())) {
System.out.print((char)value);//转换为字符并打印出来
} } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
} //////////////////////////////////////////////////////////////////////
/**
* 使用read(byte b[])方法,一次最多读取b.length个字节到b字节数组中
*/
private static void test2() {
FileInputStream fis= null; try {
fis = new FileInputStream("./src/res/1.txt"); int len = 0;
byte[] buf = new byte[1024]; while(-1 != (len = fis.read(buf))) {
System.out.println(new String(buf, 0, len));
} } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
代码运行效果:
一个一个字节地读取的效果:
hello java hello hello ???ú
通过字节数组读取的效果:
hello java hello hello 中国
由上面的运行效果可以看到,当读取的文件中存在中文时,若使用read()方法一个字节一个字节地读取,并且每取到一个字节就打印出来,这个时候就会出现乱码,这是因为中文字符一般都不止占用一个字节(GBK编码时占用2个字节,UTF-8编码时占用3个字节),当取到一个字节时,有可能该字节只是一个中文字符的一部分,将中文截断了,这时打印出来肯定就是乱码的了。而第2种方法先将数据读取到字节数组,再用String的String(byte bytes[], int offset, int length)构造方法还原成字符串,则可以一定程度上避免了中文被截断的隐患,所以该方法可以正确的读取到文件内容,并且咩有出现乱码。
在上面的示例中,文件1.txt使用的是GBK编码,而使用方法2中的String(byte bytes[], int offset, int length)方法使用的也是平台的默认字符集GBK来进行解码的,因此可以正确地读取出文件内容,不会有乱码。倘若将1.txt的编码修改为UTF-8编码,此时还用方法2去读取,则会出现如下所示的乱码情况:
通过字节数组读取的效果:
hello java hello hello 涓浗
这种情况也很好理解,源文件1.txt是使用GBK编码的,我们使用UTF-8去解码,编码和解码使用的字符集不一致,得到的结果自然是乱码了。这时如果还想将源文件中的内容正确打印到控制台,可以将方法2修改下面所示的方法3:
private static void test3() {
FileInputStream fis= null;
try {
fis = new FileInputStream("./src/res/1.txt");
int len = 0;
byte[] buf = new byte[1024];
while(-1 != (len = fis.read(buf))) {
System.out.println(new String(buf, 0, len, "utf-8"));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
上面代码中,我们通过String的String(byte bytes[], int offset, int length, String charsetName)构造方法,以显式指定字符集的方式来解码字节数组。如此,同样可以正确读出文件中的内容。综上,可知还原字符串的时候,必须保证编码的统一!
2. FileOutputStream
FileOutputStream是文件输出节点流,同样它也是个字节流。根据API文档可知,FileOutputStream文件输出流是用于将数据写入 File 或 FileDescriptor 的输出流。
首先该类的几个构造方法需要注意一下:
FileOutputStream(String name) throws FileNotFoundException
该方法创建一个向具有指定名称的文件中写入数据的输出文件流,事实上该方法的底层会调用重载的构造方法来创建指向文件的输出流。由源码可以看出它的实现思路:
public FileOutputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null, false);
}
另外,需要注意的是,使用该方法指向的文件,若文件已存在,则通过该输出流写入时会覆盖文件中的原有内容;若文件不存在,则会先创建文件,再向文件中写入数据。即便如此,该方法还是有可能会抛出FileNotFoundException,这是因为,假如你传入的是一个根本不存在的文件路径(如:suhaha/xxx…/2.txt),那么jvm无法在一个不存在的路径上创建文件,这个时候就会报FileNotFoundException异常。
FileOutputStream(String name, boolean append) throws FileNotFoundException
该方法的功能跟上面的差不多一样,只不过它可以通过第二个参数append,来决定是追加还是覆盖目标文件中的内容,若传入true,则是追加,若传入false,则是覆盖。
示例代码:
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException; public class FileOutputStreamTest {
public static void main(String[] args) {
FileOutputStream fos = null; try {
fos = new FileOutputStream("./src/res/2.txt"); //路径正确时,若文件不存在,则自动创建
// fos = new FileOutputStream("suhaha/xxx"); //如果是随便乱写一个压根不存在的路径,则会报FileNotFoundException异常
String str1 = "hello java";
String str2 = "中国"; //将字符串转换为字节数组
byte[] bytes1 = str1.getBytes();
byte[] bytes2 = str2.getBytes(); fos.write(bytes1[0]); //将单个字节写入输出流中,写入:h
fos.write(bytes2); //将整个字节数组写入,写入:中国
fos.write(bytes1, 6, 4);//将字节数组bytes1中从索引6开始的4个字节写入输出流中,写入:java } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fos) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
代码运行效果:
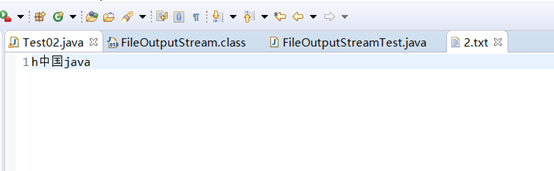
同样,在通过FileOutputStream将数据写入目标文件时,也有可能存在由编码引起的乱码问题。
在上面的示例中,在使用str1.getBytes()方法将字符串转换为字节数组时,由getBytes()方法的源码可以看出,它使用的是平台默认的字符集进行编码,我在windows平台上默认是使用GBK字符集。然后,最后通过输出流写入的文件也是使用GBK进行编码的,因此最后写入的数据没有出现乱码,倘若目标文件2.txt是UTF-8编码,则使用上面的代码进行写入就会出现如下所示的乱码:
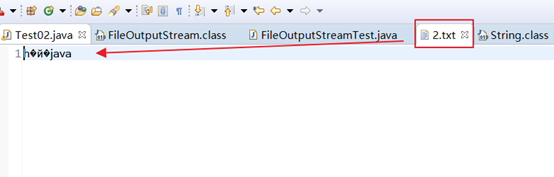
此时可以通过手动将2.txt文件的编码由UTF-8改为GBK,来将数据正确显式出来。
然而,如果我们的需求就是需要将数据写入一个用UTF-8编码的目标文件中,则可用通过使用String类的byte[] getBytes(String charsetName)方法显式指定字符集来将字符串转换为字节数组,这样就可以将数据正确写入一个UTF-8目标文件中。示例代码如下所示:
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException; public class FileOutputStreamTest {
public static void main(String[] args) {
FileOutputStream fos = null; try {
fos = new FileOutputStream("./src/res/2.txt"); //路径正确时,若文件不存在,则自动创建
// fos = new FileOutputStream("suhaha/xxx"); //如果是随便乱写一个压根不存在的路径,则会报FileNotFoundException异常
String str1 = "hello java";
String str2 = "中国"; //将字符串转换为字节数组
byte[] bytes1 = str1.getBytes();
byte[] bytes2 = str2.getBytes("utf-8"); fos.write(bytes1[0]); //将单个字节写入输出流中,写入:h
fos.write(bytes2); //将整个字节数组写入,写入:中国
fos.write(bytes1, 6, 4);//将字节数组bytes1中从索引6开始的4个字节写入输出流中,写入:java } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fos) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
3. FileInputStream和FileOutputStream综合使用示例
下面的代码中定义了两个方法,test1()和test2(),test1()方法从一个GBK编码的源文件中读取数据,复制到一个以UTF-8编码的目标文件中;test2()则正好反之,它从一个UTF-8编码的源文件中读取数据,复制到一个以GBK编码的目标文件中。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException; public class FileInOutStreamTest {
public static void main(String[] args) { // test1();
test2(); } /////////////////////////////////////////////////////
/**
* 从1.txt文件中读取数据,复制到2.txt文件中
* 其中,1.txt是用GBK编码的,2.txt使用UTF-8编码的
*/
private static void test1() {
FileInputStream fis = null;
FileOutputStream fos = null; try {
fis = new FileInputStream("./src/res/1.txt");
fos = new FileOutputStream("./src/res/2.txt"); int len = 0;
byte[] buf = new byte[1024]; while(-1 != (len = fis.read(buf))) { //从源文件1.txt读取到字节数组中的数据是GBK编码的
String str = new String(buf, 0, len); //先转为字符串,这里默认使用GBK进行解码
byte[] bytes = str.getBytes("utf-8"); //再显式指定以utf-8字符集进行编码
fos.write(bytes); //将字节数组数据写入到以utf-8编码的目标文件2.txt中
fos.flush();
} } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fos) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
} /////////////////////////////////////////////////////
/**
* 从2.txt文件中读取数据,复制到1.txt文件中
* 其中,1.txt是用GBK编码的,2.txt使用UTF-8编码的
*/
private static void test2() {
FileInputStream fis = null;
FileOutputStream fos = null; try {
fis = new FileInputStream("./src/res/2.txt");
fos = new FileOutputStream("./src/res/1.txt"); int len = 0;
byte[] buf = new byte[1024]; while(-1 != (len = fis.read(buf))) { //从源文件2.txt读取到字节数组中的数据是utf-8编码的
String str = new String(buf, 0, len, "utf-8"); //先转为字符串,这里显式指定使用utf-8进行解码
byte[] bytes = str.getBytes(); //再以默认字符集GBK进行编码
fos.write(bytes); //将字节数组数据写入到以GBK编码的目标文件1.txt中
fos.flush();
} } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fos) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
注:上面演示的方法可能比较low,但是如果只使用目前的这两个文件输入输出流的话,这是我能想到的一个解决办法。
通过转换流InputStreamReader和OutputStreamWriter也可以实现该功能,可以参考J07-Java IO流总结七 《 InputStreamReader和OutputStreamWriter 》
J03-Java IO流总结三 《 FileInputStream和FileOutputStream 》的更多相关文章
- java中OutputStream字节流与字符流InputStreamReader 每一种基本IO流BufferedOutputStream,FileInputStream,FileOutputStream,BufferedInputStream,BufferedReader,BufferedWriter,FileInputStream,FileReader,FileWriter,InputStr
BufferedOutputStream,FileInputStream,FileOutputStream,BufferedInputStream,BufferedReader,BufferedWri ...
- java IO流 (三) 节点流(或文件流)
1.FileReader/FileWriter的使用:1.1 FileReader的使用 /* 将day09下的hello.txt文件内容读入程序中,并输出到控制台 说明点: 1. read()的理解 ...
- java io系列07之 FileInputStream和FileOutputStream
本章介绍FileInputStream 和 FileOutputStream 转载请注明出处:http://www.cnblogs.com/skywang12345/p/io_07.html File ...
- IO流9 --- 使用FileInputStream和FileOutputStream读写非文本文件 --- 技术搬运工(尚硅谷)
字节流读写非文本文件(图片.视频等) @Test public void test5(){ File srcFile = new File("FLAMING MOUNTAIN.JPG&quo ...
- Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream
Java IO流学习总结三:缓冲流-BufferedInputStream.BufferedOutputStream 转载请标明出处:http://blog.csdn.net/zhaoyanjun6/ ...
- Java:IO流与文件基础
Java:IO流与文件基础 说明: 本章内容将会持续更新,大家可以关注一下并给我提供建议,谢谢啦. 走进流 什么是流 流:从源到目的地的字节的有序序列. 在Java中,可以从其中读取一个字节序列的对象 ...
- java IO流详解
流的概念和作用 学习Java IO,不得不提到的就是JavaIO流. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输 ...
- Java IO流学习总结
Java流操作有关的类或接口: Java流类图结构: 流的概念和作用 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输 ...
- Java IO流题库
一. 填空题 Java IO流可以分为 节点流 和处理流两大类,其中前者处于IO操作的第一线,所有操作必须通过他们进行. 输入流的唯一目的是提供通往数据的通道,程序可以通过这个通道读取数 ...
- Java IO流系统整理
Java IO流的分类 Java中的流,可以从不同的角度进行分类. 按流向分类: 输入流: 程序可以从中读取数据的流.输出流: 程序能向其中写入数据的流. 按数据传输单位分类: 字节流:以字节(8位二 ...
随机推荐
- iCn3D结构查看器的实现方法
iCn3D Structure Viewer:iCn3D结构查看器 演示效果如下: 上面只是一个Basic UI的演示,如果要Advanced UI的话可以去NCBI官网看API
- AVL树C++实现
1. AVL 树本质上还是一棵二叉搜索树,它的特点是: 本身首先是一棵二叉搜索树. 带有平衡条件: 每个结点的左右子树的高度之差的绝对值(平衡因子) 最多为 1. 2. 数据结构定义 AVL树节点类: ...
- 打包python为可执行文件时报错R6034解决方案
R6034 指的是:”An application has made an attempt to load the C runtime library incorrectly. Please cont ...
- day01(静态、代码块、类变量和实类变量辨析 )
静态: 关键字:static 概述: 使用static关键字修饰的成员方法.成员变量称为静态成员方法.静态成员变量. 优缺点: 优点:使用时不用创建对象,节约了空间.使得代 ...
- PAT 甲 1005. Spell It Right (20) 2016-09-09 22:53 42人阅读 评论(0) 收藏
1005. Spell It Right (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given ...
- js 面向对象 定义对象
js面向对象看了很多,却没有完全真正的理解,总是停留在一定的阶段,这次再认真看一下. 面向对象包含两种:定义类或对象:继承机制:都是通过工厂模式,构造函数,原型链,混合方法这四个阶段,原理也一样,只是 ...
- 团队博客-第三周:需求改进&系统设计(科利尔拉弗队)
针对课堂讨论环节老师和其他组的问题及建议,对修改选题及需求进行修改 需求规格说明书: 1.打开网页,弹出询问时候创建账号.是:分配数字组成账号,用户填写密码,确定登录进入首页:否,用已有账号登录(传参 ...
- 单元测试工具Numega BoundsChecker
1 前言 我在本文中详细介绍了测试工具NuMega Devpartner(以下简称NuMega)的使用方法. NuMega是一个动态测试工具,主要应用于白盒测试.该工具的特点是学习简单.使用方便.功能 ...
- Android-Git命令行操作
Git命令行操作,在Mac上使用的话,Mac会自带了Git,直接在终端或者iTerm都可以执行Git命令操作: Git命令行操作,在Windows系统电脑上使用的话,需要安装Git,安装好Git ...
- DevOps Workshop 研发运维一体化(成都站) 2016.05.08
成都的培训与广州.上海.北京一样,只是会议室比较小,比较拥挤,大家都将就了.可惜换了电脑以后,没有找到培训时的照片了,遗憾. 培训思路基没有太大变化,基本按照下面的思路进行: 第一天对软件开发的需求管 ...