Redis源码阅读(四)集群-请求分配
Redis源码阅读(四)集群-请求分配
集群搭建好之后,用户发送的命令请求可以被分配到不同的节点去处理。那Redis对命令请求分配的依据是什么?如果节点数量有变动,命令又是如何重新分配的,重分配的过程是否会阻塞对外提供的服务?接下来会从这两个问题入手,分析Redis3.0的源码实现。
1. 分配依据——槽
Redis将每个客户端的请求命令通过哈希的方式映射到槽上,映射方法就是对该客户端请求中的键值求CRC16校验值,求得的值再和16383(0x3FFF)进行与操作,得到的结果即为槽值;Redis集群默认设置了16384个slot槽,集群的节点接管了哪些槽就会存储相对应的数据库键值对,每个节点可以接管的槽数量为[0, 16384]。客户端的命令发送到Redis集群的任意节点都会先根据该命令所要操作的key来计算其对应的槽。如果该槽是由接收命令的节点接管,则该节点可直接处理该命令并返回客户端结果,如果槽是由其他节点接管则会返回给客户端MOVED错误,并准备转向正确的节点进行处理。这就是Redis集群分配命令的基本原理。(备注:如果客户端的请求中不带有key,则该命令不会对Redis存储的数据进行操作,只是获取服务状态的命令,无需分配到其他节点)
1.1 槽初始分配
对槽的初始分配是通过cluster addslots命令实现的
Cluster addslots <slot>
各个节点是怎么知道每个槽分配给了哪个节点呢?上篇文章中介绍过每个集群节点都有一个clusterState结构体来记录集群的总体信息,可以看到在该结构体中有一个成员记录了每个槽指派给了哪个节点:
typedef struct clusterState {
...
clusterNode *slots[REDIS_CLUSTER_SLOTS];
...
}
槽i分配的Node节点就是slots[i]的值,查找出命令应该分配给哪个节点的时间复杂度是O(1)。我们看下cluster addslots命令的具体实现:
void clusterCommand(redisClient *c) {
......
else if ((!strcasecmp(c->argv[]->ptr,"addslots") ||
!strcasecmp(c->argv[]->ptr,"delslots")) && c->argc >= )
{
/* CLUSTER ADDSLOTS <slot> [slot] ... */
// 将一个或多个 slot 添加到当前节点
/* CLUSTER DELSLOTS <slot> [slot] ... */
// 从当前节点中删除一个或多个 slot
int j, slot;
// 一个数组,记录所有要添加或者删除的槽
unsigned char *slots = zmalloc(REDIS_CLUSTER_SLOTS);
// 检查这是 delslots 还是 addslots
int del = !strcasecmp(c->argv[]->ptr,"delslots");
// 将 slots 数组的所有值设置为 0
memset(slots,,REDIS_CLUSTER_SLOTS);
// 处理所有输入 slot 参数
for (j = ; j < c->argc; j++) {
// 获取 slot 数字
if ((slot = getSlotOrReply(c,c->argv[j])) == -) {
zfree(slots);
return;
}
// 如果这是 delslots 命令,并且指定槽为未指定,那么返回一个错误
if (del && server.cluster->slots[slot] == NULL) {
addReplyErrorFormat(c,"Slot %d is already unassigned", slot);
zfree(slots);
return;
// 如果这是 addslots 命令,并且槽已经有节点在负责,那么返回一个错误
} else if (!del && server.cluster->slots[slot]) {
addReplyErrorFormat(c,"Slot %d is already busy", slot);
zfree(slots);
return;
}
// 如果某个槽指定了一次以上,那么返回一个错误
if (slots[slot]++ == ) {
addReplyErrorFormat(c,"Slot %d specified multiple times",
(int)slot);
zfree(slots);
return;
}
}
// 处理所有输入 slot
for (j = ; j < REDIS_CLUSTER_SLOTS; j++) {
if (slots[j]) {
int retval;
/* If this slot was set as importing we can clear this
* state as now we are the real owner of the slot. */
// 如果指定 slot 之前的状态为载入状态,那么现在可以清除这一状态
// 因为当前节点现在已经是 slot 的负责人了
if (server.cluster->importing_slots_from[j])
server.cluster->importing_slots_from[j] = NULL;
// 添加或者删除指定 slot
retval = del ? clusterDelSlot(j) :
clusterAddSlot(myself,j);
redisAssertWithInfo(c,NULL,retval == REDIS_OK);
}
}
zfree(slots);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
addReply(c,shared.ok);
}
......
}
代码中可以看到在槽初始化的最后阶段还执行了clusterAddSlot函数(如果是删除槽分配信息的命令cluster delslots, 则会执行clusterDelSlot函数),clusterAddSlot函数除了修改clusterState里的slots数组之外,还对clusterNode中的一个slots位图变量进行了修改。clusterNode中的slots位图记录的是该节点负责处理的槽有哪些。如果clusterNode->slots位图的第i位为1,则表示第i个槽是该节点接管的,为0则表示第i个槽不属于该节点处理范围。注意下两个slots成员的区别:
ClusterState中的slots成员是指针数组,记录槽由哪个节点托管
ClusterNode中的slots成员是位图,记录各个clusterNode托管了哪些槽
用多个数据结构来记录槽的托管信息,最终目的就是为了让操作更快捷,比如判断命令需要转发到哪个节点时,可直接使用ClusterState.slots查询,时间复杂度是O(1),当需要判断某个特定的槽是否属于某节点处理则只需到该节点的slots位图中查看即可,时间也是O(1)。当然多个数据结构的弊端是牺牲了一定的空间和初始化效率,但初始化的频率远小于查找槽托管情况的频率,牺牲初始化效率换来高效率的查找是值得的。
1.2 和一致哈希的比较
这里简单介绍下一致性哈希,参考并摘录了网上相关博文的内容(https://www.cnblogs.com/lpfuture/p/5796398.html)。早期的时候,为解决负载均衡分配问题,引入哈希算法来做分配。系统中如果存在N个节点,将节点从0到N-1编号,对请求数据的某个特征做哈希运算后将结果对N取模,取模的值即该请求数据可以被分配的节点号。这种方法可以做到负载均衡,但当节点数发生变化时,请求数据的哈希值需要对新的节点数量取模,这样几乎所有数据被分配的节点号都可能发生变化,也就是所有的请求数据都要面对重新分配节点的问题。
针对这一问题,一致性哈希算法诞生了。一致性哈希将整个哈希值空间组织成一个虚拟的圆环,哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

算法的关键是将Node节点本身也做哈希,可以用IP或服务器名称来计算哈希值,将Node映射到哈希环上;环空间是固定的,节点的哈希值通常也是固定的也就是说节点在哈希环上的位置是固定的。数据也会计算哈希后映射到环空间上。数据应该交个哪个节点来处理呢?从数据对应位置开始,顺时针寻找第一个遇到的Node哈希值所对应的节点,该节点就是数据要分配的节点。可以看到如果新增或者删除了节点也不会影响其他节点在环空间的位置,这是保证大多数节点能在节点数量变更的情况下不受影响的关键。

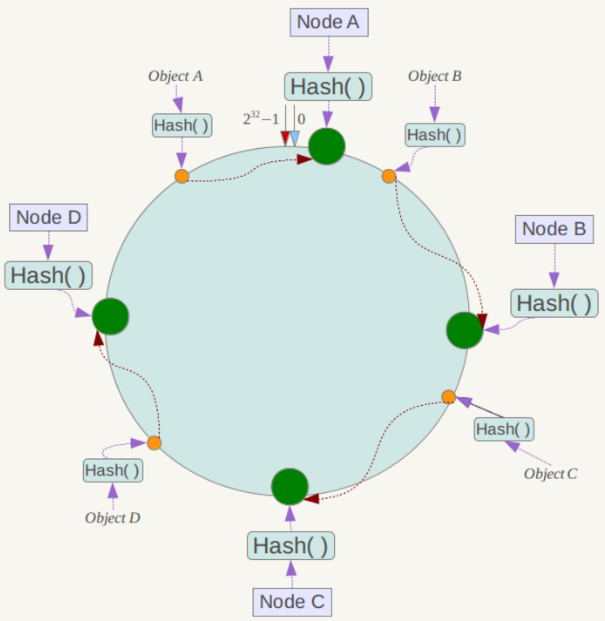
这里有两个需要注意的地方:
- 要尽量选择不会变化的指标来计算哈希值,避免节点哈希值有变化
- 不同节点不能映射到同一个位置上,避免数据无法决定分配到哪个节点上(虽然概率比较小,但还是有节点映射的哈希值相同的可能)
此外一致性哈希还可能遇到的问题就是几个节点的哈希值分布不均匀,会有大部分的数据被映射的某个或某几个节点上,造成负载偏重问题。一致性哈希的处理方式是给每个节点分配多个虚拟节点,人为增加节点数量,可以让节点的位置更加分散;分配到虚拟节点的数据还需要再多加一步,判断该虚拟节点隶属于哪个实际节点,才能决定该数据是由哪个节点处理。
一致性哈希的优点比较明显,可以比较好的做到负载均衡,而且动态变更节点时对其他节点的影响比较小。数据的分配完全由算法决定,需要配置的内容比较少。但也带来一个问题,就是很难做到手动将特定数据分配给指定机器。Redis的槽分配方式是可以任意指定的,可以将部分键值对手动的分配到指定的节点,便于根据业务来分配键值,配置方式灵活;而且可以随时对键值对的分配进行调整。同时也可以做到节点数据量变化时,只有局部的节点负责的键值对会受到影响。和一致性哈希比较,缺点则是初始化配置比较麻烦,如果完全通过人工分配槽的归属,工作量比较大且容易出错。
2. 重新分片
Redis集群的重新分片是指可以将原来指派给某个节点的任意数量槽重新指派给新的节点(可以是新加入的节点也可以是集群中其他的节点)。除了槽重新指派外,这些槽原来接管的键值对也会从原来的节点(源节点)转发到新的节点(目标节点)。
重新分片由于要将槽所管理的键值对也同步迁移,耗时是比较长的;在重新分片的过程中,Redis服务并没有中断服务。这是怎么做到的呢?在Redis集群中需要在实际执行迁移前,事先标记好待迁移的槽是要从哪个节点迁移到哪个节点,这样在迁移过程中如果发现键值对已经不再属于原节点,则通过ASK错误可以给出应该去哪个节点找到该键值对。这里要求所有键值对的迁移是原子的,避免用户取到未迁移完全的键值对。
2.1 重新分片流程
重新分片是由几个命令共同实现的,简述下单个槽的迁移步骤:
- 向目标节点发送Cluster setslot <slot> importing <source_id>,让目标节点准备好从source_id节点接管槽slot [只有目标节点知道键需要迁移]
- 向源节点发送Cluster setslot <slot> migrating <target_id>,让源节点准备向目标节点迁移槽slot [只有目标节点和源节点都知道键需要迁移]
- 向源节点发送Cluster getkeysinslot <slot> <count>,获取slot槽中最多count个键值对的键名称 [迁移中,会出现Ask错误]
- 将第3步中获取到的所有键值对转发到目的节点上,实现这一目标的话需要在转发每个键值对时向源节点发送Migrate <target_ip> <target_port> <key_name> 0 <timeout>命令[迁移中,会出现Ask错误,每个key的迁移都需要为原子的]
- 重复3、4两步直到槽下所有键值对都已转移 [迁移中,会出现Ask错误]
- 向源节点发送cluster setslot <slot> stable,取消槽的迁移标记
- 向集群中任意节点发送Cluster setslot <slot> node <target_id>,该节点获知槽slot已经转移给target_id对应的节点之后会将该消息通过gossip扩散给集群中所有节点[迁移完成,所有节点更新了槽的托管关系结构体]
我们来看下源码中这几个和槽迁移有关的命令的实现:
void clusterCommand(redisClient *c) {
......
// 将本节点的槽 slot 迁移至 node id 所指定的节点
if (!strcasecmp(c->argv[]->ptr,"migrating") && c->argc == ) {
// 被迁移的槽必须属于本节点
if (server.cluster->slots[slot] != myself) {
addReplyErrorFormat(c,"I'm not the owner of hash slot %u",slot);
return;
}
// 迁移的目标节点必须是本节点已知的
if ((n = clusterLookupNode(c->argv[]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[]->ptr);
return;
}
// 为槽设置迁移目标节点
server.cluster->migrating_slots_to[slot] = n;
// CLUSTER SETSLOT <slot> IMPORTING <node id>
// 从节点 node id 中导入槽 slot 到本节点
} else if (!strcasecmp(c->argv[]->ptr,"importing") && c->argc == ) {
// 如果 slot 槽本身已经由本节点处理,那么无须进行导入
if (server.cluster->slots[slot] == myself) {
addReplyErrorFormat(c,
"I'm already the owner of hash slot %u",slot);
return;
}
// node id 指定的节点必须是本节点已知的,这样才能从目标节点导入槽
if ((n = clusterLookupNode(c->argv[]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[]->ptr);
return;
}
// 为槽设置导入目标节点
server.cluster->importing_slots_from[slot] = n;
} else if (!strcasecmp(c->argv[]->ptr,"stable") && c->argc == ) {
/* CLUSTER SETSLOT <SLOT> STABLE */
// 取消对槽 slot 的迁移或者导入
//注意:在迁移源节点中的某个槽位到目的集群完毕后(包括数据迁移完毕),需要向源节点发送cluster setslot <slot> stable,通知
//源redis节点槽位迁移完毕,如果不清理在cluster nodes中会出现迁移过程状态,例如6f4e14557ff3ea0111ef802438bb612043f18480 10.2.4.5:7001 myself,master - 0 0 5 connected 4-5461 [2->-4f3012ab3fcaf52d21d453219f6575cdf06d2ca6] [3->-4f3012ab3fcaf52d21d453219f6575cdf06d2ca6]
server.cluster->importing_slots_from[slot] = NULL;
server.cluster->migrating_slots_to[slot] = NULL;
}
......
}
1)Cluster setslot <slot> importing <source_id> 命令主要就是将importing_slots_from[slot]的值设置为source_id所对应的clusterNode的指针。在clusterState结构体中定义了该成员变量:clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS]; 该数组记录了每个槽要从哪个节点导入进来;
2)Cluster setslot <slot> migrating <target_id> 命令主要就是将migrating_slots_to[slot]的值设置为target_id所对应的clusterNode的指针。在clusterState结构体中定义了该成员变量:clusterNode *migrating_slots_from[REDIS_CLUSTER_SLOTS]; 该数组记录了每个槽要迁移到哪个目标节点。
获取slot所包含的key是通过Cluster getkeysinslot <slot> <count>命令实现的,看下代码是如何处理该命令的:
void clusterCommand(redisClient *c) {
......
else if (!strcasecmp(c->argv[]->ptr,"getkeysinslot") && c->argc == ) {
/* CLUSTER GETKEYSINSLOT <slot> <count> */
// 打印 count 个属于 slot 槽的键
long long maxkeys, slot;
unsigned int numkeys, j;
robj **keys;
// 取出 slot 参数
if (getLongLongFromObjectOrReply(c,c->argv[],&slot,NULL) != REDIS_OK)
return;
// 取出 count 参数
if (getLongLongFromObjectOrReply(c,c->argv[],&maxkeys,NULL)
!= REDIS_OK)
return;
// 检查参数的合法性
if (slot < || slot >= REDIS_CLUSTER_SLOTS || maxkeys < ) {
addReplyError(c,"Invalid slot or number of keys");
return;
}
// 分配一个保存键的数组
keys = zmalloc(sizeof(robj*)*maxkeys);
// 将键记录到 keys 数组
numkeys = getKeysInSlot(slot, keys, maxkeys);
// 打印获得的键
addReplyMultiBulkLen(c,numkeys);
for (j = ; j < numkeys; j++) addReplyBulk(c,keys[j]);
zfree(keys);
}
......
}
// 记录 count 个属于 hashslot 槽的键到 keys 数组
// 并返回被记录键的数量
unsigned int getKeysInSlot(unsigned int hashslot, robj **keys, unsigned int count) {
zskiplistNode *n;
zrangespec range;
int j = ; range.min = range.max = hashslot;
range.minex = range.maxex = ; // 定位到第一个属于指定 slot 的键上面
n = zslFirstInRange(server.cluster->slots_to_keys, &range);
// 遍历跳跃表,并保存属于指定 slot 的键
// n && n->score 检查当前键是否属于指定 slot
// && count-- 用来计数
while(n && n->score == hashslot && count--) {
// 记录键
keys[j++] = n->obj;
n = n->level[].forward;
}
return j;
}
代码中server.cluster->slots_to_keys就是存储key和槽对应关系的数据结构,该数据结构是通常比较少见的跳跃表,该数据结构是一个多层链表,可以加速有序数据的查找,期望时间可以达到O(log n)。跳跃表实现起来要比平衡二叉树简单的多,且查找节点、插入/删除节点的操作也不需要做过多调整。这里简单介绍下跳跃表这个数据结构
跳跃表:
跳跃表简单来说就是多层的链表,用来存储有序的数据。对于普通的有序单链表来讲,查找一个节点的时间复杂度是O(n),这是由于每次查找都要遍历整个链表空间。

将部分元素从单链表中抽取出来,组成新的链表,在该层链表中再做查找,查找到某个范围后在到下层去查找。在上层遍历的只是这些抽取出的元素,假设抽取元素的方式是每隔一个元素就抽取出来,那么上层查找的时间复杂度就变为O(n/2),而下层最多查找2次(两个上层元素之间的距离为2),总的复杂度为O(n/2) + O(1), 也就是O(n/2)
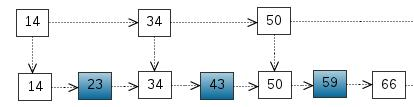
我们还可以将第二层再进行抽取,抽取出第三层的链表,和上面的标准相同,也是以每隔一个节点抽取出来的方式,此时查找的时间复杂度就为O(n/2²) + O(1) + O(1),也就是O(n/4)。当层数足够高时,可以看到查找的时间复杂度为O(log n)

这就是跳跃表的基本思想,其实最终的形态和树类似。但注意一点,如果严格按照上面提到的规则来抽取元素,插入和删除元素有可能要调整所有元素来保持这个结构,而跳跃表本身是希望能向链表一样插入和删除元素只对有限几个元素产生影响,所以不能采用上述那种严谨的方式来实现跳跃表(如果严格定义了抽取规则,则和二叉树等数据结构差别不大)
在实际实现上,跳跃表每个元素的层数是随机生成的,而为了保证跳跃表类似树的这种层次结构,要求层数越低的元素出现的概率越高,且概率呈幂次定律。元素层数的生成代码其实非常简单,我们看下Redis中生成元素层高的代码:
int zslRandomLevel(void) {
int level = ;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += ;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
没错只有这几行,不得不再说一次,确实非常简单;ZSKIPLIST_P默认值为0.25;我们注意到while循环的判断条件如下:
(random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)
这个判断条件为真的概率其实就是ZSKIPLIST_P,那么层数不高于1的概率就是1-0.25=0.75,层数2的概率0.25*(1-0.25),层数为3的概率为0.25*0.25*(1-0.25) ......
这里有个疑问,虽然层数level越高,概率越低,但特别极端情况下还是有可能出现level不停加下去的情况(当然按概率论来看,出现这种情况可能性微乎其微);所以还是觉得在while判断条件中加上层数限制会保险一些,像这样:
int zslRandomLevel(void) {
int level = ;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF) && level <ZSKIPLIST_MAXLEVEL)
level += ;
return level;
}
当然这种随机生成元素的层数也会带来弊端,每个节点的层数是随机的,虽然可以在概率上保证层数越高的元素数量越少,整个跳跃表呈现树状的层次,但是无法控制相同层次的元素之间的距离。最差情况下查找的时间复杂度可能会降到O(n)。下图为最差的跳跃表形态:
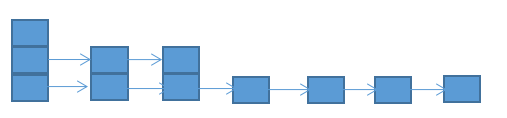
以上是对跳跃表做了简单的介绍,能够了解到什么是跳跃表就足够了。Redis中跳跃表的实现,后续会详细剖析下Redis中跳跃表的插入,删除,以及特殊的一些设计,想放到Redis数据结构源码分析中展开,真心觉着跳跃表是个很容易工程化的数据结构,实现起来很方便。这里回到我们根据槽值获取所有key的实现上;我们知道槽和key的关系是存储在跳跃表中的,每个跳跃表中的元素都记录了一个key值,而元素在跳跃表中排序用的值就是key对应的槽值。所有的key都按槽值大小排序好存入跳跃表中了,查找指定槽值下的所有key也就是查找槽值第一次出现在跳跃表中的位置,然后依次向后遍历,取出所有与指定槽值相等的元素所记录的key。
2.2 重新分片如何实现不对服务造成阻塞
重新分片过程中,Redis服务还是可以继续接收客户端的请求,当客户端请求的key刚好属于迁移过程中的slot,就轮到ask错误登场了。可能有些朋友会有疑问,之前不是有过一个Moved错误吗?什么情况下返回Moved错误,又是什么情况下返回ask错误呢?其实也很好区分,当命令所操作的key对应的槽不是属于接收命令的服务器处理时,会返回Moved错误;而当key对应的槽属于接收命令的服务器处理时(也就是槽隶属于该服务器),如果该槽正在被迁移,且key已经被转发出去,则这种情况下返回的是ask错误。假设key属于槽i,此时会从接收命令的服务器的server.cluster->migrating_slots_to[i]中取出槽i迁移的目的服务器,并在ask错误中返回给客户端,客户端可以向新的目的服务发送命令请求。
考虑这样一个场景,槽i属于节点A,重新分片将槽i分配给了节点B。在重新分片完成之前,槽i还是归属于A节点的。
- 此时客户端向服务器B发送命令请求(该命令操作的key计算哈希后落在槽i),由于此时槽i还不属于节点B处理,所以节点B会返回给客户端Moved错误,并告知客户端应该访问节点A。
- 客户端再次向节点A发送该命令请求时,A发现命令请求的key已经转移到节点B了,此时就会给客户端发送ask错误。
- 这次客户端还是要向节点B发送请求。
发现了一个问题,第3步和第1步是一样的,都是向B发送命令请求,这样不是就陷入一个死循环中了吗?
Redis是这样处理这种情况的,客户端在接收到ask错误之后,先向目的服务器发送一个Asking命令,让目的服务器给该客户端置一个Redis-asking标志,之后客户端再向目的服务器发送命令。也就是说在步骤3之前还需要向节点B发送一个Asking命令,然后B会将客户端结构体中的Redis-asking标志置为true,当节点B再收到该客户端发来的命令请求时发现该客户端处于Redis-asking状态且server.cluster->importing_slots_from[i]不为空时就会处理客户端的命令。要注意的是这个Redis-asking标志只是单次有效,在处理完之后就会恢复该标志位,如果下次再向节点B发送请求之前没有发送Asking命令,B节点就会返回客户端Moved错误,重新走一遍上述的流程。
引用:对跳跃表的介绍引用了https://blog.csdn.net/u014427196/article/details/52454462博文中的内容和图片
Redis源码阅读(四)集群-请求分配的更多相关文章
- tomcat源码阅读之集群
一. 配置: 在tomcat目录下的conf/Server.xml配置文件中增加如下配置: <!-- Cluster(集群,族) 节点,如果你要配置tomcat集群,则需要使用此节点. clas ...
- dubbo源码阅读之集群(故障处理策略)
dubbo集群概述 dubbo集群功能的切入点在ReferenceConfig.createProxy方法以及Protocol.refer方法中. 在ReferenceConfig.createPro ...
- Redis源码阅读(三)集群-连接初始化
Redis源码阅读(三)集群-连接建立 对于并发请求很高的生产环境,单个Redis满足不了性能要求,通常都会配置Redis集群来提高服务性能.3.0之后的Redis支持了集群模式. Redis官方提供 ...
- Redis源码阅读---连接建立
对于并发请求很高的生产环境,单个Redis满足不了性能要求,通常都会配置Redis集群来提高服务性能.3.0之后的Redis支持了集群模式. Redis官方提供的集群功能是无中心的,命令请求可以发送到 ...
- Redis源码阅读(六)集群-故障迁移(下)
Redis源码阅读(六)集群-故障迁移(下) 最近私人的事情比较多,没有抽出时间来整理博客.书接上文,上一篇里总结了Redis故障迁移的几个关键点,以及Redis中故障检测的实现.本篇主要介绍集群检测 ...
- Redis源码阅读(五)集群-故障迁移(上)
Redis源码阅读(五)集群-故障迁移(上) 故障迁移是集群非常重要的功能:直白的说就是在集群中部分节点失效时,能将失效节点负责的键值对迁移到其他节点上,从而保证整个集群系统在部分节点失效后没有丢失数 ...
- dubbo源码解析五 --- 集群容错架构设计与原理分析
欢迎来我的 Star Followers 后期后继续更新Dubbo别的文章 Dubbo 源码分析系列之一环境搭建 博客园 Dubbo 入门之二 --- 项目结构解析 博客园 Dubbo 源码分析系列之 ...
- 39 网络相关函数(七)——live555源码阅读(四)网络
39 网络相关函数(七)——live555源码阅读(四)网络 39 网络相关函数(七)——live555源码阅读(四)网络 简介 14)readSocket从套接口读取数据 recv/recvfrom ...
- 27 GroupSock概述(一)——live555源码阅读(四)网络
27 GroupSock概述(一)——live555源码阅读(四)网络 27 GroupSock概述(一)——live555源码阅读(四)网络 简介 1.网络通用数据类型定义 2.Tunnel隧道封装 ...
随机推荐
- css3动画效果小结
css3的动画功能有以下三种: 1.transition(过度属性) 2.animation(动画属性) 3.transform(2D/3D转换属性) 下面逐一进行介绍我的理解: 1.transiti ...
- jQuery内容横向拖拽滚动
如果有业务需求:使用横向滚动,而又不想用滚动条,可以使用横向拖拽滚动,主要是利用元素的scrollLeft特性: 废话不多说直接上代码: css: .box{ width:100%; height:3 ...
- C#动态加载/卸载Assembly的解决方案
1. Assembly中的类要从MarshalByRefObject继承,如果你想从你自己的类来继承,那么请选用interface或者继续研究其他解决方案. namespace Library { ...
- Elasticsearch之如何合理分配索引分片
大多数ElasticSearch用户在创建索引时通用会问的一个重要问题是:我需要创建多少个分片? 在本文中, 我将介绍在分片分配时的一些权衡以及不同设置带来的性能影响. 如果想搞清晰你的分片策略以及如 ...
- 牛顿法/拟牛顿法/DFP/BFGS/L-BFGS算法
在<统计学习方法>这本书中,附录部分介绍了牛顿法在解决无约束优化问题中的应用和发展,强烈推荐一个优秀博客. https://blog.csdn.net/itplus/article/det ...
- pom xml testng
<dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId ...
- .NET Core中多语言支持
在.NET Core项目中也是可以使用.resx资源文件,来为程序提供多语言支持.以下我们就以一个.NET Core控制台项目为例,来讲解资源文件的使用. 新建一个.NET Core控制台项目,然后我 ...
- C#中的结构体与类的区别 (转载)
经常听到有朋友在讨论C#中的结构与类有什么区别.正好这几日闲来无事,自己总结一下,希望大家指点. 1. 首先是语法定义上的区别啦,这个就不用多说了.定义类使用关键字class 定义结构使用关键字str ...
- iOS蓝牙APP常驻后台
iOS蓝牙类APP常驻后台的实现方法,经过在苹果开发者论坛询问,以及查看苹果开发者文档,最后得出正确的方法为: 1.设置plist,蓝牙权限 2.到target-capabilities-backgr ...
- Unity 4.7 导出工程在XCode9/10上报错 validateRenderPassDescriptor:644: failed assertion `XXXX'
Unity 4.7 导出工程在XCode9/10上报错 validateRenderPassDescriptor:644: failed assertion `Texture at colorAtta ...