Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改
OLAP 联机分析处理 Online Analysis Processing 查询
真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
Hadoop是啥
Hadoop的官网:http://hadoop.apache.org/
1、Hadoop是Apache旗下的一套开源软件平台
2、Hadoop提供的功能:利用服务器集群,根据户自定义业逻辑对海量数进行分布式处理
3、Hadoop的核心组件:
1)Hadoop Common:支持其他Hadoop模块的常用工具。
2) Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
3) Hadoop YARN:作业调度和集群资源管理的框架。
4) Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
大数据的处理主要就是存储和计算。
如果说安装hadoop集群,其实就是安装了两个东西: 一个操作系统YARN 和 一个文件系统HDFS。其实MapReduce就是运行在YARN之上的应用。
操作系统 文件系统 应用程序
win7 NTFS QQ,WeChat
YARN HDFS MapReduce
4、hadoop的概念:
狭义上: 就是apache的一个顶级项目:apahce hadoop
广义上: 就是指以hadoop为核心的整个大数据处理体系
5、Apache的其他Hadoop相关项目包括:
- Ambari™:一种用于供应,管理和监控Apache Hadoop集群的基于Web的工具,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个用于查看群集运行状况的仪表板,例如热图和可以直观地查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
- Avro™:数据序列化系统。
- Cassandra™:无单点故障的可扩展多主数据库。
- Chukwa™:管理大型分布式系统的数据收集系统。
- HBase™:可扩展的分布式数据库,支持大型表格的结构化数据存储。
- Hive™:提供数据汇总和即席查询的数据仓库基础架构。
- Mahout™:可扩展的机器学习和数据挖掘库。
- Pig™:用于并行计算的高级数据流语言和执行框架。
- Spark™:用于Hadoop数据的快速和通用计算引擎。Spark提供了一个简单而富有表现力的编程模型,它支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。
- Tez™:一种基于Hadoop YARN的通用数据流编程框架,它提供了一个强大且灵活的引擎,可执行任意DAG任务来处理批处理和交互式用例的数据。Hado™,Pig™和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)正在采用Tez来替代Hadoop™MapReduce作为底层执行引擎。
- ZooKeeper™:分布式应用程序的高性能协调服务。
HADOOP在大数据、云计算中的位置和关系
1、云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。1、
2、现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3、 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
Hadoop的技术应用
HADOOP应用于数据服务基础平台建设
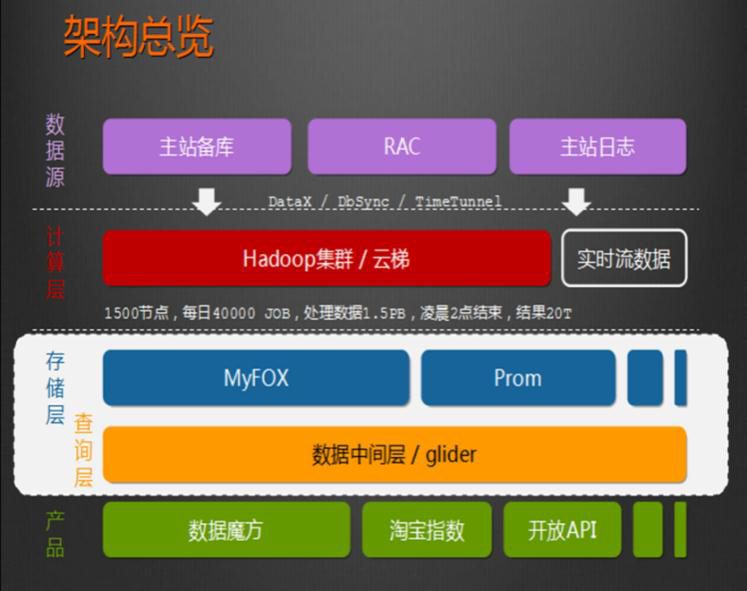
HADOOP用于用户画像
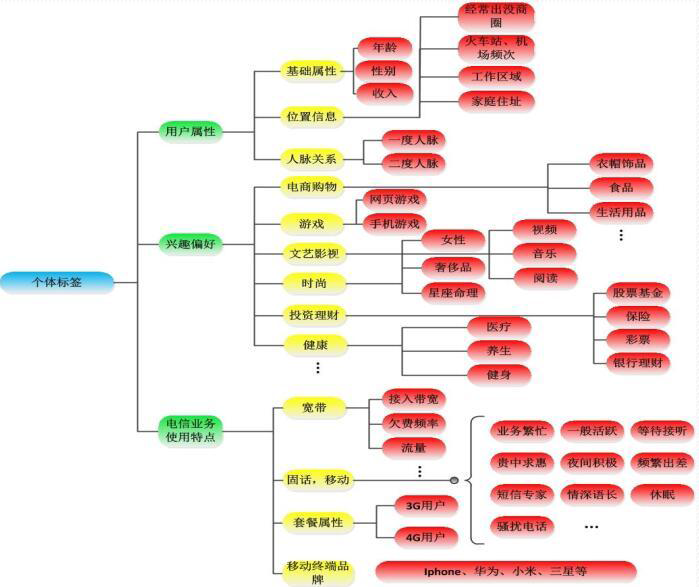
该图是中国电信的用户画像标签体系。
HADOOP用于网站点击流日志数据挖掘
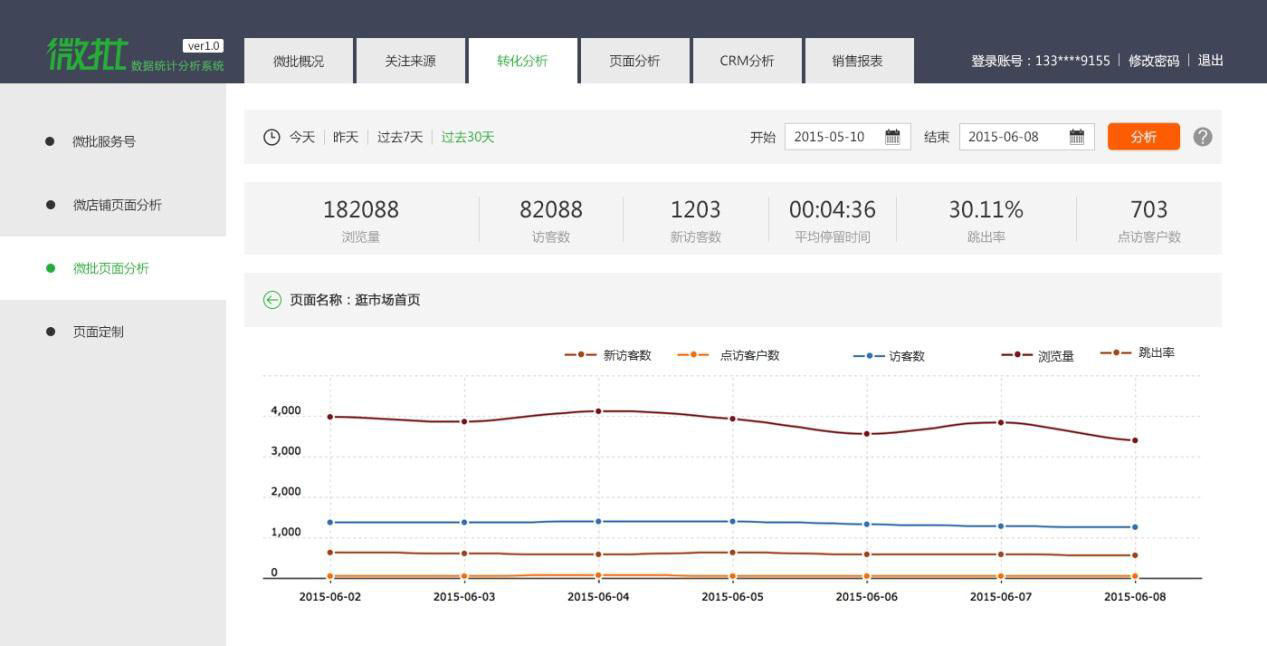
总结:hadoop并不会跟某个具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
HADOOP生态圈以及各组成部分的简介
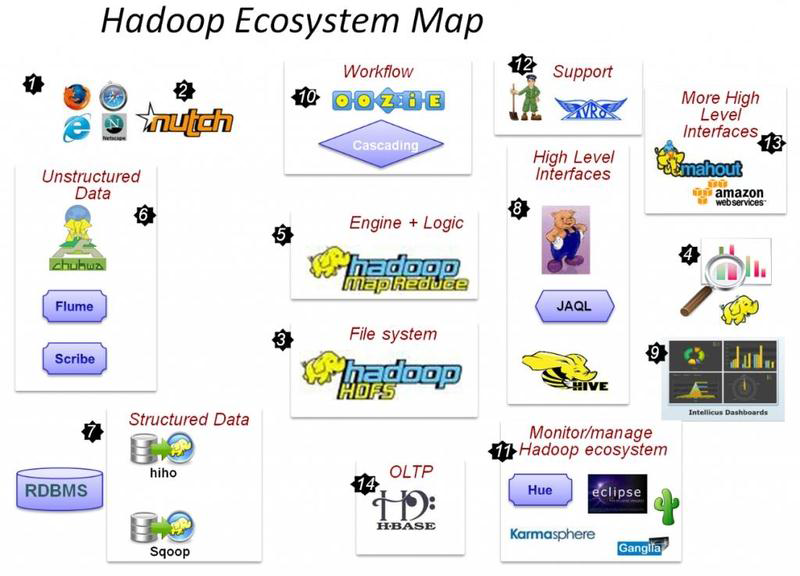
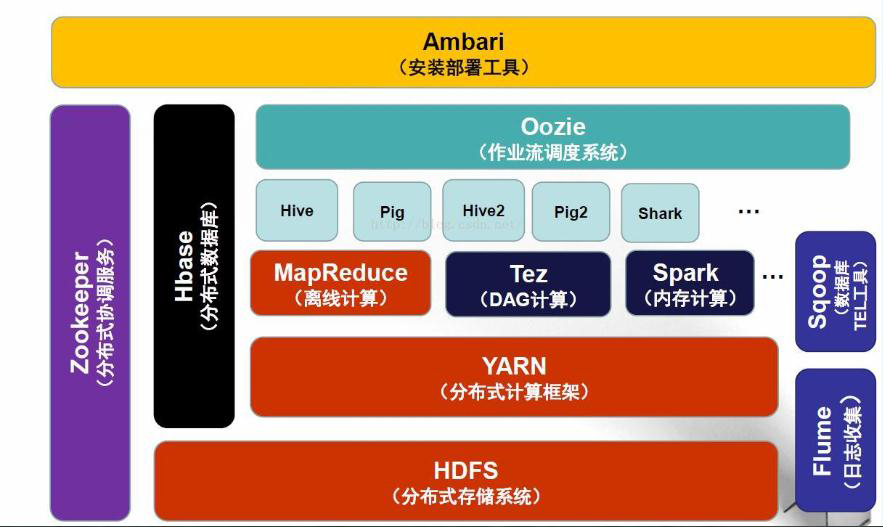
重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
获取数据的三种方式
1、自己公司收集的数据--日志 或者 数据库中的数据
2、有一些数据可以通过爬虫从网络中进行爬取
3、从第三方机构购买
国内HADOOP的就业情况分析
1、HADOOP就业整体情况
A. 大数据产业已纳入国家十三五规划
B. 各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
C. 互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
D. 相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
E. 随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
硬实力
A. HADOOP分布式集群的平台搭建
B. HADOOP分布式文件系统HDFS的原理理解及使用
C. HADOOP分布式运算框架MAPREDUCE的原理理解及编程
D. Hive数据仓库工具的熟练应用
E. Flume、sqoop、oozie等辅助工具的熟练使用
F. Shell/python等脚本语言的开发能力
软实力
A. 解决问题的能力(调试,阅读文档)
B. 沟通协调能力(寻求帮助)
C. 学习提升自己的能力(自我提高)
D. 组织管控能力(管理能力)
Hadoop学习之路(二)Hadoop发展背景的更多相关文章
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- Hadoop学习之路(二)HDFS基础
1.HDFS前言 HDFS:Hadoop Distributed File System,Hadoop分布式文件系统,主要用来解决海量数据的存储问题. 设计思想 分散均匀存储 dfs.blocksiz ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- hadoop学习笔记(二):centos7三节点安装hadoop2.7.0
环境win7+vamvare10+centos7 一.新建三台centos7 64位的虚拟机 master node1 node2 二.关闭三台虚拟机的防火墙,在每台虚拟机里面执行: systemct ...
随机推荐
- (POI)Excel格式转Html格式
Demo结构和引用的Jar包 源代码(TestDemo.java) POI中将Excel转换为HTML方法仅能转换HSSFWorkBook类型(即03版xls),故可以先将读取的xlsx文件转换成xl ...
- 重构一段基于原生JavaScript的表格绘制代码
为了在CardSimulate项目中方便的显示技能和效果列表,决定重构以前编写的一段JavaScript代码——att表格绘制库,这段代码的作用是将特定的JavaScript数据对象转化为表格,支持精 ...
- jQuery下拉框操作系列$("option:selected",this) &&(锋利的jQuery)
jQuery下拉框操作系列$("option:selected",this) &&(锋利的jQuery) <!DOCTYPE html> <ht ...
- webapi 后台跳转 后台输出html和script
1.跳转 [HttpGet]public HttpResponseMessage LinkTo(){ HttpResponseMessage resp = new HttpResponseMessag ...
- (文章也有问题,请自行跳过)react中的状态机每次setState都是重新创建新的对象,如需取值,应该在render中处理。
demo如下 class Demo4StateLearn extends React.Component { constructor(props) { super(props); this.state ...
- redis 数据淘汰策略与配置
redis 数据淘汰策略 volatile-lru:从已设置过期的数据集中挑选最近最少使用的淘汰volatile-ttr:从已设置过期的数据集中挑选将要过期的数据淘汰volatile-random:从 ...
- web 应用请求乱码问题
背景 作为非西欧语系的国家,总是要处理编码问题 使用java编码解码 @Test public void coderTest() throws UnsupportedEncodingException ...
- leetCode题解之First Missing Positive
1.问题描述 2.题解思路 本题的思路是对于数组中每个正的元素,应该将其放到数组中对应的位置,比如元素1 ,应该放在数组的第一个位置.以此类推,最后检查数组中元素值和下标不匹配的情况. 3.代码 in ...
- J2EE开发环境--RAP
J2EE开发环境--RAP J2EE开发环境分四步: 1.JDK环境 2.tomcat 3.redis环境 4.mysql环境 5.RAP包 线上环境,推荐使用源码,自建应用用户,设置对应规则,禁止关 ...
- Oracle闪回(FlashBack)数据库
Flashback Database功能非常类似与RMAN的不完全恢复,它可以把整个数据库回退到过去的某个时点的状态,这个功能依赖于Flashback log日志.比RMAN更快速和高效,因此Flas ...