阿里云搭建hadoop集群服务器,内网、外网访问问题(详解。。。)
这个问题花费了我将近两天的时间,经过多次试错和尝试,现在想分享给大家来解决此问题避免大家入坑,以前都是在局域网上搭建的hadoop集群,并且是局域网访问的,没遇见此问题。
因为阿里云上搭建的hadoop集群,需要配置映射集群经过内网访问,也就是局域网的ip地址。
如果配置为公网IP地址,就会出现集群启动不了,namenode和secondarynamenode启动不了,如果将主机的映射文件配置为内网IP集群就可以正常启动了。但通过eclipse开发工具访问
会出错,显示了阿里云内网的ip地址来访问datanode,这肯定访问不了啊,这问题真实醉了,就这样想了找了好久一致没有思路。
最终发现需要在hdfs-site.xml中修改配置项dfs.client.use.datanode.hostname设置为true,就是说客户端访问datanode的时候是通过主机域名访问,就不会出现通过内网IP来访问了
最初查看日志发现:
一、查看日志
1. less hadoop-hadoop-namenode-master.log

2.less hadoop-hadoop-secondarynamenode-master.log

二、解决集群访问问题
1.查看hosts映射文件

上面是公网IP需要替换为内网IP

然后正常搭建hadoop集群
2.core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/BigData/hadoop-2.7.3/data</value>
</property>
3.hadoop-env.sh 修改export JAVA_HOME值
export JAVA_HOME=/home/hadoop/BigData/jdk1.8
4.hdfs-site.xml 注意:添加一个dfs.client.use.datanode.hostname配置
<!-- 指定namenode的http通信地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 如果是通过公网IP访问阿里云上内网搭建的集群 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
5.mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory的address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- jobhistory的webapp.address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
6. yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
7.hadoop namenode -format格式化,然后启动start-all.sh
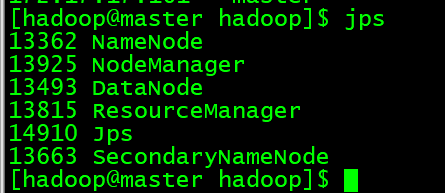
8.在本地IDE环境中编写单词统计测试集群访问
public class WordCount {
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable item:values) {
sum += item.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>....] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length -1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileSystem fs = FileSystem.get(conf);
Path output = new Path(otherArgs[otherArgs.length - 1]);
if(fs.exists(output)) {
fs.delete(output, true);
System.out.println("output directory existed! deleted!");
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
}
9.运行的时候配置一个数据的存放路径和数据的输出路径位置
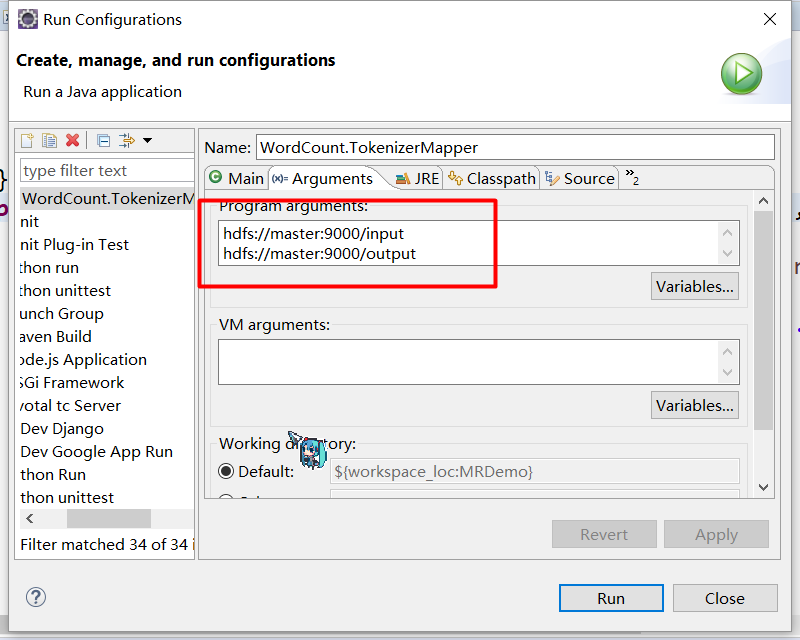
10 . 正常运行并访问了阿里云的hadoop集群
阿里云搭建hadoop集群服务器,内网、外网访问问题(详解。。。)的更多相关文章
- Hadoop集群(第6期)_WordCount运行详解
1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然 ...
- 阿里云搭建redis集群
1.安装redis # 下载redis包 wget http://download.redis.io/releases/redis-5.0.5.tar.gz tar -zxvf redis-5.0.5 ...
- [BD] 阿里云部署hadoop集群
安装方式 rpm包安装:下载rpm文件后离线装,安装过程中会下载相应依赖 bin文件安装:在线安装 tar包安装 步骤 下载安装文件:买香港机器,按量付费,传到windows电脑 购买三台,按需付费, ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 虚拟机搭建Hadoop集群
安装包准备 操作系统:ubuntu-16.04.3-desktop-amd64.iso 软件包:VirtualBox 安装包:hadoop-3.0.0.tar.gz,jdk-8u161-linux-x ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
随机推荐
- DI spring.net简单使用
IOC或DI spring.net简单使用 一.spring.net是什么? Spring 框架本是 Java 平台上一个应用非常多的.开源的框架.虽然语言是固定的,但是好的方法应该是通用的,于是 ...
- 『原创』手把手教你搭建一个实用的油耗App(一)
前言: 入行快10年,有点积蓄,三年前买了代步车.于是乎,汽车油耗开销就成了每个月都必须关注的问题.三年来,用过了无数油耗记录软件,比如最知名的“小熊油耗”,从第一次用,一直到最新一版,感觉越来越“臃 ...
- s11 day104 数据库表结构与立即支付流程
数据库表结构: 13张 1. 课程大类 2.课程子类 3.学位课程 4.老师表 5.奖学金 6.专题课 7.课程详情 8.课程大纲 9.常见问题 10.章节 11.课时 12.作业表 13.价格策略 ...
- Day 25 多态.
一.多态的概念 多态指的是一类事物有多种形态.动物有多种形态:人,狗,猪 from abc import ABCMeta,abstractmethod class Animal(metaclass=a ...
- Python3.5 学习九
进程与线程 线程(Thread)是计算机运算调度的最小单位,它存在于进程中,是实际运作单位.每个进程都可能并发多线程. 每一个程序的内存是独立的. 线程:是操作系统最小的运算调度单位,是一串指令的集合 ...
- spring定时任务的注解实现方式
STEP 1:在spring配置文件中添加相应配置,以支持定时任务的注解实现 (一)在xml里加入task的命名空间 <!-- beans里添加:--> xmlns:task=" ...
- 【bzoj2789】 Letters 树状数组
又是一道树状数组求逆序对的题目. 这一题我们可以将第二个串中的每一个字母,与第一个串中的字母做两两匹配,令第二个串第i个字母的值id[i]为该字母与第一个串中的字母匹配到的位置. 然后考虑到所求答案为 ...
- APP版本升级,测试用例总结
APP升级主要在线升级.离线升级.当有新版本时,提示更新,用户点击更新,下载最新版本,进行安装升级,这种就是在线升级:已有升级包,安装升级包进行升级,这种就是离线升级. 在线升级.离线升级常见测试用例 ...
- easyui 中iframe嵌套页面,提示弹窗遮罩的解决方法,parent.$.messager.alert和parent.$.messager.confirm
项目中用到easyui 布局,用到north,west,center三个区域,且在center中间区域嵌入iframe标签.在主内容区做一些小提示弹窗(例如删除前的弹窗提示确认)时,会遇到遮罩问题,由 ...
- 使用TopShelf做windows服务安装 ---安装参数解释
转自:https://topshelf.readthedocs.io/en/latest/overview/commandline.html Topshelf Command-Line Referen ...