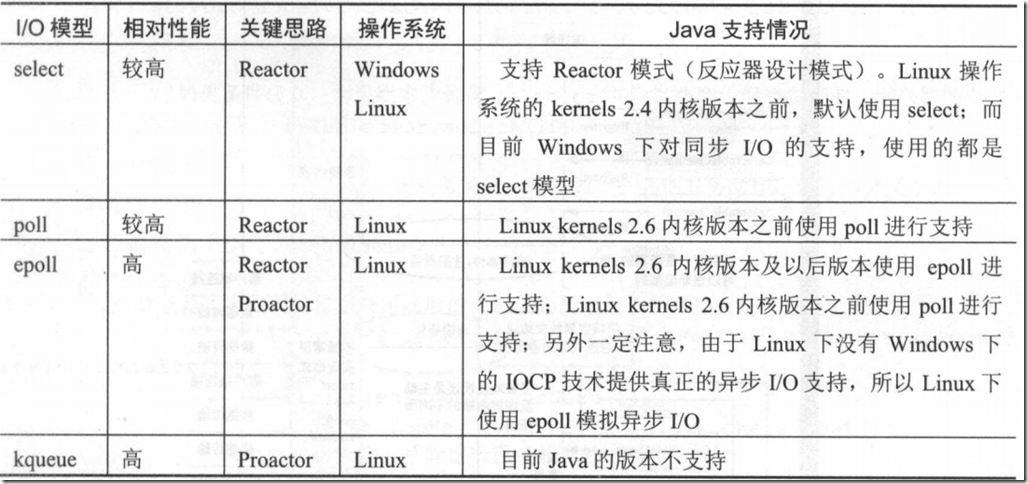
网络I/O模型--05多路复用I/O
多路复用I/O模型在应用层工作效率比我们俗称的 BIO 模型快的本质原因是,前者不再使用操作系统级别的“同步 I/O”模型 。 在 Linux 操作系统环境下, 多路复用 I/O 模型就是技术人员通常简称的 NIO 技术。多路复用I/O 目前具体的实现主要包括四种: select、 poll , epoll 、kqueue 。
多路复用 I/O技术最适用的是“高并发”场景,所谓高并发是指 l 毫秒内至少同时有成百上千个连接请求准备就绪,其他情况下多路复用I/O技术发挥不出它的明显优势 。
重要概念
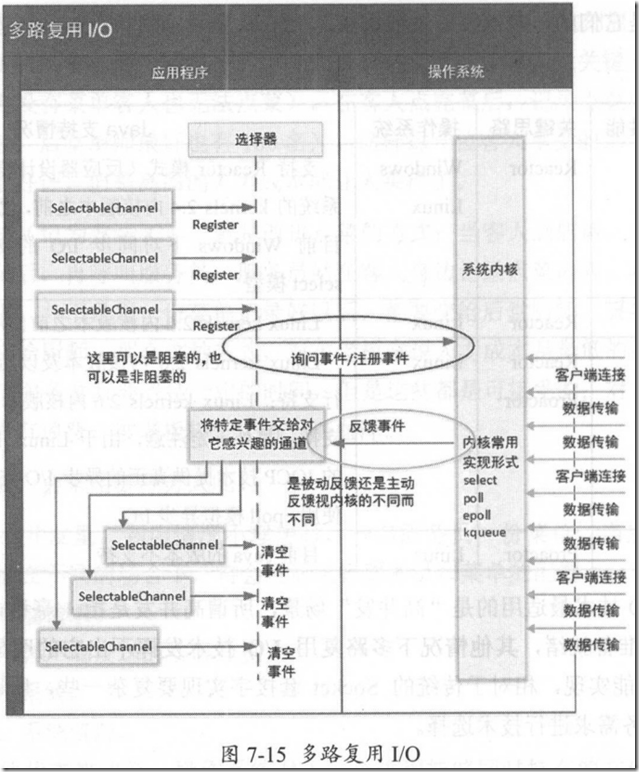
无论使用哪种实现方式,它们都会有“选择器”、 “通道”、 “缓存”这几个操作要素,那么可以为不同的多路复用盯0 技术创建一个统一的抽象组,井且为不同的操作系 统进行具体的实现。
Channel 通道: 是一个用来完成应用程序和操作系统交互事件、传递内容的渠道,注意是连接到操作系统。一个通道会有一个专属的文件状态描述符。既然是和操作系统进行内容的传递,那就说明应用程序可以通过通道从操作系统读取数据,也可以通过通道向操作系统写数据 。
Buffer数据缓存区: 在 Java 原生 NIO 框架中,为了保证每个通道的数据读/写速度, Java NIO 框架为每一种需要支持数据读/写 的通道集成了 Buffer 的支持。Buffer 有两种工作模式: 写模式和读模式。在读模式下,应用程序只能从 Buffer 中 读取数据,不能进行写操作 。 但是在写模式下,应用程序是可以进行读操作的,这就表示可能会出现脏读的情况 。 所以一旦决定要从 Buffer 中读取数据,就一定要将 Buffer 的状态改为读模式 。
• position : 缓存区目前正在操作的数据块位置。
• limit:缓存区最大可以进行操作的位置。缓存区的读/写状态正是由这个属性控制的 。
• capacity:缓存区的最大容量 。这个容量是在缓存区创建时进行指定的。由于高井发时通道数量往往会很庞大,所以每一个缓存区的容量最好不要过大。
Selector选择器:
可以把它称为“轮询代理器”、 “事件订阅器”、 “ Channel 容器管理机”等等。
• 事件订阅和 Channel 管理:应用程序将向 Selector 对象注册需要它关注的 Channel ,以及具体的某一个 Channel 会对哪些 I/O事件感兴趣。 Selector 中也会维护一个 “己经注册的 Channel“的容器 。
• 轮询代理:应用层不再通过阻塞模式或者非阻塞模式直接询问操作系统“事件有没有发生”,而是由 Selector 代其询问。
• 实现不同操作系统的支持: 之前己经提到过, 多路复用I/O 技术是需要操作系统进行支持的,其特点就是操作系统可以同时扫描同一个端口上的多个网络连接 。 所以作为上层 的 JVM,必须要为不同操作系统的多路复用 I/O 实现编写不同 的代码 。
package testBlockSocket; import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.nio.ByteBuffer;
import java.nio.channels.SelectableChannel;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class SocketServerReuseAddres {
private final static Logger LOGGER = LoggerFactory.getLogger(SocketServerReuseAddres.class);
private static final Map<Integer, StringBuffer> MESSAGEHASHCONTEXT = new ConcurrentHashMap<>(); public static void main(String[] args) throws Exception {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 一定要这样设置
serverChannel.configureBlocking(false);
ServerSocket serverSocket = serverChannel.socket();
serverSocket.setReuseAddress(true);
serverSocket.bind(new InetSocketAddress(8888));
Selector selector = Selector.open();
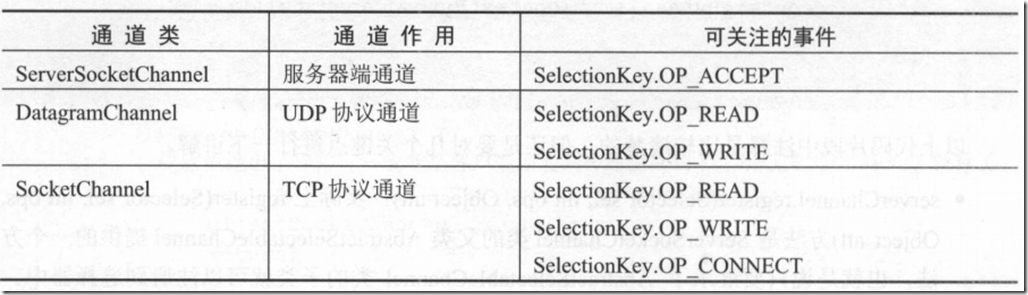
// 注意:服务器通道能且只能注册 SelectionKey . OP ACCEPT 事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
try {
while (true) {
// 如果条件成立,则说明本次询问 selector 并没有获取任何准备好的、感兴趣的事件
if (selector.select(100) == 0) {
// =============
// 这里祝业务情况,可以做一些其他业务动作,但实际意义不大
// =============
continue;
}
// 这就是本次询问操作系统所获取的“所关心的事件"的事件类型(每一个通道是独立的)
Iterator<SelectionKey> selecionKeys = selector.selectedKeys().iterator();
while (selecionKeys.hasNext()) {
SelectionKey readyKey = selecionKeys.next();
// 一定要移除这个已经处理的 readyKey 如果不移除,就会一直存在在 selector.selectedKeys 集合中 待到下一次 selector
// . select() > 0 时,这个 readyKey 又会被处理一次
selecionKeys.remove();
SelectableChannel selectableChannel = readyKey.channel();
if (readyKey.isValid() && readyKey.isAcceptable()) {
SocketServerReuseAddres.LOGGER.info("==channel 通道已经准备好===");
// 当 serverSocketChannel 通道已经准备好 , 就可以从 serverSocketChannel中获取socketChannel 了
// 拿到socketChannel后,要做的事情就是马上到
// selector注册这个socketChannel感兴趣的事情。否则无法监听到这个socketChannel到达的数据
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) selectableChannel;
SocketChannel socketChannel = serverSocketChannel.accept();
registerSocketChannel(socketChannel, selector);
} else if (readyKey.isValid() && readyKey.isReadable()) {
SocketServerReuseAddres.LOGGER.info("======socket channel数据准备完成,可以去读==读取======= ");
readSocketChannel(readyKey);
}
}
}
} catch (Exception e) {
SocketServerReuseAddres.LOGGER.error(e.getMessage(), e);
} finally {
serverSocket.close();
} } private static void registerSocketChannel(SocketChannel socketChannel, Selector selector) throws Exception {
socketChannel.configureBlocking(false);
// socket 通道可以且只可以注册三种事件! SelectionKey.OP_READ | SelectionKey.OP_WRITE |
// SelectionKey.OP_CONNECT
// 最后一个参数视为这个 socketchanne 分配的缓存区
socketChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(2048));
} private static void readSocketChannel(SelectionKey readyKey) throws Exception {
SocketChannel clientSocketChannel = (SocketChannel) readyKey.channel();
// 获取客户端使用的端口
InetSocketAddress sourceSocketAddress = (InetSocketAddress) clientSocketChannel.getRemoteAddress();
Integer resoucePort = sourceSocketAddress.getPort();
// 拿到这个 socket 通道使用的缓存区,准备读取数据
// 解缓存区的用法实际上重要的就是三个元素: capacity 、 position 和 limit
ByteBuffer contextBytes = (ByteBuffer) readyKey.attachment();
// 将通道的数据写入缓存区
// 由于之前设置了 ByteBuffer 的大小为 2048 byte ,所以可能存在写不完的情况
int realLen = -1;
StringBuffer message = new StringBuffer();
while ((realLen = clientSocketChannel.read(contextBytes)) != 0) {
// 一定要把 Buffer 切换成“读”模式 , 否则 由于 limit = capacity; 在 read 没有写满的情况下 , 就会导致多读
contextBytes.flip();
int position = contextBytes.position();
int capacity = contextBytes.capacity();
byte[] messageBytes = new byte[capacity];
contextBytes.get(messageBytes, position, realLen);
// 注意中文乱码的问题,使用 URLDecoder/URLEncoder 进行解编码,当然 Java NIO 框架本身也提供编解码方式,看个人使用习惯
String messageEncode = new String(messageBytes, 0, realLen, "UTF-8");
message.append(messageEncode);
// 再切换成“写”模式,直接存入缓存的方式最快捷
contextBytes.clear();
} // 如果发现本次接收的信息中有“ over ” 关键字 , 说明信息接收完成
if (URLDecoder.decode(message.toString(), "UTF-8").indexOf("over") != -1) {
// 则从 messageHashContext 中 , 取出之前已经收到的信息 , 组合成完整的信息
Integer channelUUID = clientSocketChannel.hashCode();
SocketServerReuseAddres.LOGGER.info("端口 :" + resoucePort + "客户端发来的{言息 == ====message : " + message);
StringBuffer completeMessage;
// 清空 MESSAGEHASHCONTEXT 中的历史记录
StringBuffer historyMessage = MESSAGEHASHCONTEXT.remove(channelUUID);
if (historyMessage == null) {
completeMessage = message;
} else {
completeMessage = historyMessage.append(message);
}
SocketServerReuseAddres.LOGGER.info("端口 :" + resoucePort + "客户端发来的完整 信息 ======completeMessage :"
+ URLDecoder.decode(completeMessage.toString(), "UTF-8")); // ======================
// 接收完成后,可以在这里正式处理业务了
// ====================
// 回发数据,并关闭 Channel
ByteBuffer sendBuffer = ByteBuffer.wrap(URLEncoder.encode("回发处理结果", "UTF-8").getBytes());
clientSocketChannel.write(sendBuffer);
clientSocketChannel.close();
} else {
// 如果没有发现“ over ”关键字,说明还没有接收究,则将本次接收到的信息存入 MESSAGEHASHCONTEXT
SocketServerReuseAddres.LOGGER.info("端口:" + resoucePort + "客户端信息还未接收完,继续接收======message :"
+ URLDecoder.decode(message.toString(), "UTF-8")); // 每一个 Channel 对象都是独立的,所以可以使用对象的 Hash 值,作为唯一标识
Integer channelUUID = clientSocketChannel.hashCode();
// 然后获取这个 Channel 下以前已经到达的信息
StringBuffer historyMessage = MESSAGEHASHCONTEXT.get(channelUUID);
if (historyMessage == null) {
historyMessage = new StringBuffer();
MESSAGEHASHCONTEXT.put(channelUUID, historyMessage.append(message));
}
historyMessage.append(message);
}
}
}
多路复用 I/O 技术由操作系统提供支持,并提供给各种高级语言进行使用。它针对阻塞式同步 I/O 和非阻塞式同步 I/O 而言有很多优势,最直接的效果就是它绕过了I/O在操作系统层面的 accept()方法的阻塞问题 。
• 使用多路复用I/O技术后 ,应用程序就可以不用再单纯使用多线程技术来解决并发I/O处理的性能问题了(针对操作系统内核I/O 管理模块和应用程序进程而言都是这样的)。在实际业务的处理中 , 应用程序进程还是需要引 入 (由线程池支持的)多线程技术的。
• 同一个端口可以处理多种网络协议。 例 如,使用 ServerSocketChannel 类的服务器端口监昕,既可以接收到 TCP 协议又可以接收到 UDP 协议内容。 也就是说端口的数据接收规则只和 Selector 注册的需要关心的事件有关。
• 操作系统级别的优化 : 多路复用 I/O 技术可以使操作系统级别在一个端口上能够同时接受多个客户端的 I/O 事件,同时具有之前我们讲到的阻塞式同步 I/O 和非阻塞式同步I/O的所有特点。 Selector 的一部分作用更相当于 “轮询代理器”。
• 都是同步 I/O 模型:目前我们介绍的阻塞式 I/O 、非阻塞式I/O , 甚至包括多路复用I/O ,这些都是基于操作系统级别对“同步I/O”的实现。我们一直在说“同步I/O ”, 一直都没有详细说什么叫作“同步I/O”。实际上一句话就可以解释清楚: 只有上层 (包括上层的某种代理机制)系统询问“我”是否有某个事件发生了,否则“我”不会主动告诉上层系统事件发生了。
网络I/O模型--05多路复用I/O的更多相关文章
- Linux 网络编程的5种IO模型:多路复用(select/poll/epoll)
Linux 网络编程的5种IO模型:多路复用(select/poll/epoll) 背景 我们在上一讲 Linux 网络编程的5种IO模型:阻塞IO与非阻塞IO中,对于其中的 阻塞/非阻塞IO 进行了 ...
- 从网络I/O模型到Netty,先深入了解下I/O多路复用
微信搜索[阿丸笔记],关注Java/MySQL/中间件各系列原创实战笔记,干货满满. 本文是Netty系列第3篇 上一篇文章我们了解了Unix标准的5种网络I/O模型,知道了它们的核心区别与各自的优缺 ...
- 简明网络I/O模型---同步异步阻塞非阻塞之惑
转自:http://www.jianshu.com/p/55eb83d60ab1 网络I/O模型 人多了,就会有问题.web刚出现的时候,光顾的人很少.近年来网络应用规模逐渐扩大,应用的架构也需要随之 ...
- I/O模型系列之二:Unix的五种网络I/O模型
1. Unix的五种I/O模型 从上往下:阻塞程度(高-----低)I/O效率 (低-----高) 阻塞I/O(Blocking I/O):传统的IO模型 非阻塞I/O(Non-Blocking I ...
- IO 模型 IO 多路复用
IO 模型 IO 多路复用 IO多路复用:模型(解决问题的方案) 同步:一个任务提交以后,等待任务执行结束,才能继续下一个任务 异步:不需要等待任务执行结束, 阻塞:IO阻塞,程序卡住了 非阻塞:不阻 ...
- 网络I/O模型---同步异步阻塞非阻塞之惑
网络I/O模型 人多了,就会有问题.web刚出现的时候,光顾的人很少.近年来网络应用规模逐渐扩大,应用的架构也需要随之改变.C10k的问题,让工程师们需要思考服务的性能与应用的并发能力. 网络应用需要 ...
- 网络I/O模型--07Netty基础
Netty 是由 JBOSS 提供的一个 Java 开源框架. Netty 提供异步的.事件驱动的网络应用程序框架和工具 ,用以快速开发高性能 . 高可靠性的网络服务器和客户端程序. Net ...
- Java 网络I/O模型
网络I/O模型 人多了,就会有问题.web刚出现的时候,光顾的人很少.近年来网络应用规模逐渐扩大,应用的架构也需要随之改变.C10k的问题,让工程师们需要思考服务的性能与应用的并发能力. 网络应用需要 ...
- Linux 网络 I/O 模型简介(图文)(转载)
Linux 网络 I/O 模型简介(图文)(转载) 转载:http://blog.csdn.net/anxpp/article/details/51503329 1.介绍 Linux 的内核将所有外部 ...
随机推荐
- 【xsy1018】 小A的字母游戏 扩展CRT
题目大意:有$n$个无限长的循环字符串,所谓循环字符串,就是由某一个子串重复叠加而成.现在想知道最早在哪一位,这n个字符串的那一位的字母相同. 数据范围:$n≤30000$,答案$<2^{63} ...
- JSON 字符串转换为JavaScript 对象.JSON.parse()和JSON.stringify()
使用 JavaScript 内置函数 JSON.parse() 将字符串转换为 JavaScript 对象: var text = '{ "sites" : [' + '{ &qu ...
- 转 ZFC公理系统
http://blog.sina.com.cn/s/blog_5d045b5c0100spld.html 首先,ZFC集合论中的公理大致分为3组: 1.外延公理. 2.子集公理模式.无序对公理.并集公 ...
- MySQl中的\g和\G
1. \g 在MySQL的sql语句后加上\g,效果等同于加上定界符,一般默认的定界符是分号; 2. \G 在MySQL的sql语句后加上\G,表示将查询结果进行按列打印,可以使每个字段打印到单独的行 ...
- 解析ASP.NET WebForm和Mvc开发的区别 分类: ASP.NET 2013-12-29 01:59 11738人阅读 评论(5) 收藏
因为以前主要是做WebFrom开发,对MVC开发并没有太深入的了解.自从来到创新工场的新团队后,用的技术都是自己以前没有接触过的,比如:MVC 和EF还有就是WCF,压力一直很大.在很多问题都是不清楚 ...
- gulp4.0 前端构建脚手架
最近看了下gulp4.0的升级,感觉和3.0相比变化还是比较大的,很多3.0的写法和插件会出现一些莫名其妙的变化,详细的变化就先不说了,这里我直接把我配置好的代码拿过来吧,方便各位可以更好的学习和使用 ...
- UTF8最好不要带BOM
摘自:http://www.cnblogs.com/findumars/p/3620078.html 几周前还在为BOM的问题苦恼着...正如@梁海所说,“不含 BOM 的 UTF-8 才是标准形 ...
- Struts文件上传(FormFile)
Struts中FormFile用于文件进行上传 1.在jsp文件中进行定义 <form action="/StrutsFileUpAndDown/register.do" m ...
- redis 迁移工具 redis-port 从阿里云迁移到aws
对于 redis 的 迁移我在网上看到了很多方法,有使用redis-dump 的,有使用 aof导入方式,有rdb文件迁移方式,和redis-port. 由于我是将 redis 从阿里云迁移到AW ...
- 高云的jQuery源码分析笔记
(function( window, undefined ) { // 构造jQuery对象 var jQuery = function( selector, context ) { return n ...