【运维理论】RAID级别简介
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(RAID, Redundant Array of Inexpensive Disks),简称硬盘阵列。由伯克利大学一位教授提出,其基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、容量巨大的硬盘。根据选择的版本不同,RAID比单颗硬盘有以下一个或多个方面的好处:增强数据集成度,增强容错功能,增加处理量或容量。但也有可能降低安全性、降低性能等多种缺点。另外,磁盘阵列对于计算机来说,看起来就像一个单独的硬盘或逻辑存储单元。根据不同的RAID级别,基础RAID级别可以分为RAID-0,RAID-1,RAID-2,RAID-3,RAID-4,RAID-5,RAID-6,RAID-7(存储计算机公司独有技术),JBOD。根据基础RAID级别,可以进行进一步组合,实现使用者自己想要的方案。
简而言之,RAID就是针对硬盘提供一种虚拟化方案,将多个物理硬盘组合成一个逻辑硬盘,操作系统只会把这个逻辑硬盘当作“一个硬盘”。RAID常被用在服务器计算机上,并且使用完全相同的硬盘作为组合。由于硬盘价格的不断下降(机械硬盘,基于TLC和QLC的固态硬盘)并且RAID功能更多的集成到主板上,因而电脑组装爱好者也热衷于给自己的数据存储模块加入RAID技术。
加入RAID技术主要是为了增加以下一项或多项功能:
1.增加数据可靠性
2.增加存储器读写性能
3.增加容量
以下依次介绍部分主流RAID基本级别。
一、RAID0 又称Strip,条带化模式
原理:数据交付给RAID控制单元,切割成若干条带,并行写入阵列
得失:理论上最高可提升读写速度为原来N倍,存储容量扩充为单块硬盘N倍,N为阵列内硬盘个数,数据安全性降低为原来的1/N,阵列内任意一块硬盘故障,整个阵列崩溃!而且从实际情况来看,由于本身切割数据也需要耗费计算资源,所以实际读写提升将略小于理论值,并且会随着硬盘个数增加而提升越来越少。
应用情况:适用于对读写要求高,成本控制严格,安全性要求不高的场合,单独RAID0笔者本人原来组准系统的时候用过,主要是为了提升跑分好看。一般都是采用其他组合的方案。
原理图示:

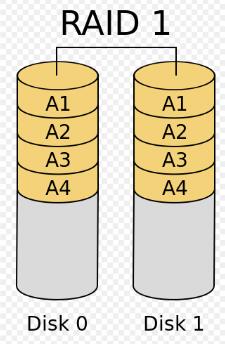
二、RAID-1 又称Mirror,镜像模式
原理:数据交付给RAID控制单元,对阵列内所有磁盘写入相同数据。读取时,与RAID0相仿,可以同时从阵列中所有可用硬盘内读取所需数据。
得失:理论上数据安全性提升N倍,写能力不受影响,读取数据能力提升为原来N倍(性能基准与单块硬盘比较,N为硬盘个数)。实际情况中,数据安全性提升比率更大(要镜像阵列中所有盘坏才会定义为崩溃,所以崩溃几率是相乘,会成倍减小),读取数据能力提升不足N倍(受控制器影响,和控制策略算法影响),写能力微弱下降(控制单元损耗)
应用情况:适用于对数据安全性要求高,读多写极少的情况,故也不适合单独拿来大规模应用。
原理图示:
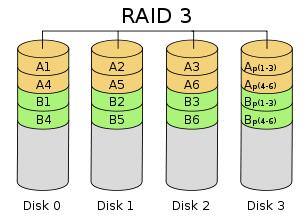
三、RAID3 带专用校验盘的数据条带
原理:数据交付给RAID控制单元,控制单元将向阵列中一块固定的磁盘写入校验信息,同时将数据信息写入其余磁盘。校验信息为异或值(Xor),如果任意一块硬盘发生错误,那么都可以通过其余磁盘信息异或后重建。
得失:当整个阵列健康时,能够提供接近RAID0的性能(倍数要排除掉校验盘),同时提供一定的容灾能力(允许一块硬盘故障)。但一旦出现坏盘进入降级模式,每一次读写坏区块的信息都要通过计算其余盘的内容,性能会大大下降
应用情况:由于RAID5能够更好的代替RAID3,所以基本上RAID3应用不多。
原理图示:
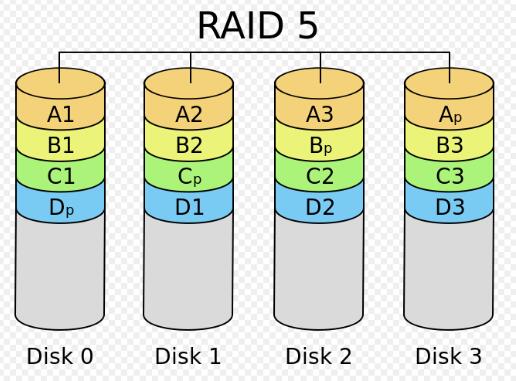
四、RAID5 分散校验盘的数据条带
原理:校验数据分布在阵列中的所有磁盘上,而没有采用专门的校验磁盘。对于数据和校验数据,它们的写操作可以同时发生在完全不同的磁盘上。
得失:读取速度接近RAID0(倍数要排除掉校验盘),同时提供一定的容灾能力(允许一块硬盘故障)。但RAID5还提供良好的扩展性,磁盘数量增加,能提供更高的容量和更快的速度。当然,对替换盘重建数据时,性能依然会受到较大影响。RAID5 兼顾存储性能、数据安全和存储成本等各方面因素,它可以理解为 RAID0 和 RAID1 的折中方案,是目前综合性能最佳的数据保护解决方案。
应用情况:RAID5 基本上可以满足大部分的存储应用需求,数据中心大多采用它作为应用数据的保护方案。但实际的应用中,也通常不单使用RAID5,而是有其他多种的组合方案。
原理图示:
当然,还有其他的诸如RAID2,RAID4,RAID6及7等非主流基本阵列模式,这种阵列模式一般商用产品都是不支持的,仅供理论了解,这里也贴一篇很好的博文,供大家参考。
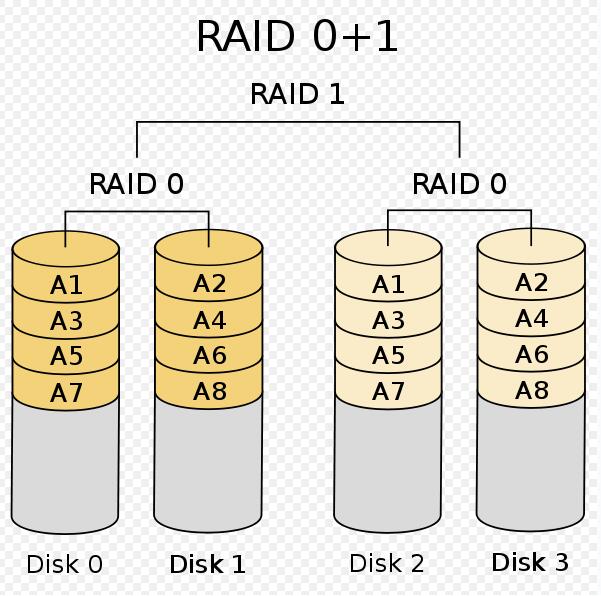
五、RAID的常见基础组合,raid10和raid01
原理:RAID10又称RAID1+0,是先将买来的硬盘分成两组,做镜像,再对每组硬盘做条带化。而RAID01则恰恰相反,是先将买来的硬盘分成两组,做条带化,再对每组硬盘做镜像。
得失:在对每个子组保持基本RAID等级的特性下,RAID10比RAID01有更好的容错能力,能够允许多个子RAID1都有坏盘,只要不是一个RAID1组中硬盘全部坏掉就OK。然而RAID01只能允许在其中一个RAID0组中有坏盘。成组至少四块硬盘,由于都有RAID1,所以磁盘利用率50%
应用情况:鉴于RAID10和01都至少四块硬盘,并且磁盘利用率在完全健康下都一致,基于RAID10数据更强的容灾能力,因而主流的磁盘阵列产品都只支持RAID10。
原理图示:
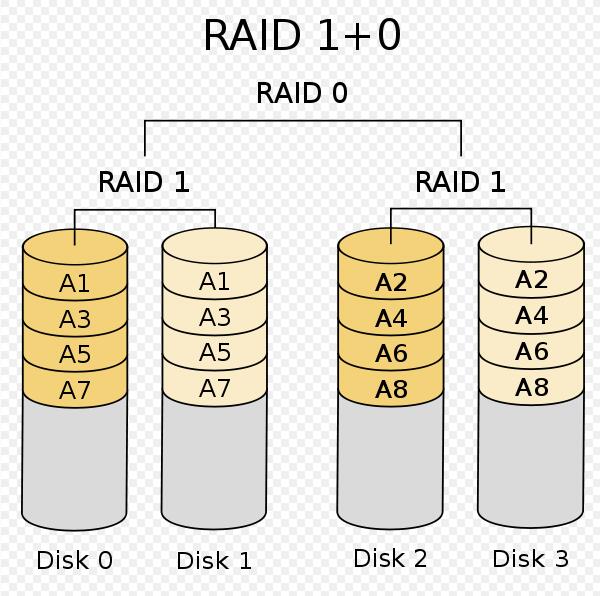
还有其他更多的组合,但都不常用。读者可以在我之前贴出的那个链接里去查阅,那篇文章很详细。
看完我这篇文章,应付一般面试都是没有问题的了。而且列举的阵列模式都是常用/支持商业化的,所以大家也可以灵活利用这些常用阵列,提升自己的硬盘效能和数据安全性。
Intel的SRT技术也可以看成是RAID的一种,只不过是Intel独有,这里就不放在这里介绍拉,有机会的话,我自己也会写一篇博客。
感谢观看。
【运维理论】RAID级别简介的更多相关文章
- RAID级别简介
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(RAID, Redundant Array of Inexpensive ...
- 自动化运维工具之SaltStack简介与安装
1.SaltStack简介 官方网址:http://www.saltstack.com官方文档:http://docs.saltstack.comGitHub:https:github.com/sal ...
- Python运维开发基础-概述-简介
Python基础知识分为以下几块 1.Python概述 2.基础语法 3.数据结构 4.Python进阶 5.实训案例 一.Python概述 1.Python简介 2.Hello World 3.搭建 ...
- 开源运维自动化平台-opendevops
开源运维自动化平台-opendevops 简介 官网 | Github| 在线体验 CODO是一款为用户提供企业多混合云.自动化运维.完全开源的云管理平台. CODO前端基于Vue iview开发. ...
- 【运维】略谈Raid级别
*何为Raid? Raid就是磁盘阵列(Redundant Arrays of Independent Disks,RAID),有"独立磁盘构成的具有冗余能力的阵列&quo ...
- ZooKeeper: 简介, 配置及运维指南
1. 概览 ZooKeeper是一个供其它分布式应用程序使用的软件, 它为其它分布式应用程序提供所谓的协调服务. 所谓的协调服务, 是指ZooKeeper的如下能力 naming 命名 configu ...
- 线上 S1 故障是什么, 线上 S1 故障, 运维故障分级, 运维, 故障分级, P1 级别故障, 故障, P1 , S1
线上 S1 故障是什么 线上 S1 故障, 运维故障分级, 运维, 故障分级, P1 级别故障, 故障, P1 , S1 故障复盘 https://time.geekbang.org/column/a ...
- 《开源安全运维平台:OSSIM最佳实践》内容简介
<开源安全运维平台:OSSIM最佳实践 > 李晨光 著 清华大学出版社出版 内 容 简 介在传统的异构网络环境中,运维人员往往利用各种复杂的监管工具来管理网络,由于缺乏一种集成安全运维平台 ...
- 运维工具shell简介
运维第一工具-shell编程 shell历史 Shell的作用是解释执行用户的命令,用户输入一条命令,Shell就解释执行一条,这种方式称为交互式(Interactive),Shell还有一种执行命令 ...
随机推荐
- Java并发编程原理与实战三十四:并发容器CopyOnWriteArrayList原理与使用
1.ArrayList的实现原理是怎样的呢? ------>例如:ArrayList本质是实现了一个可变长度的数组. 假如这个数组的长度为10,调用add方法的时候,下标会移动到下一位,当移动到 ...
- Hbase建模选择
日期 2017年3月17日 HBase建模记录 OLTP 应用场景: OLAP 应用场景: 语音分析系统的应用场景 基于HBase的建模考虑 1.话单为主来考虑hbase的rowkey的生成规则: 1 ...
- APScheduler定时执行外加supervisor管理后台运行
最近写的天气爬虫想要让它在后台每天定时执行,一开始用的celery,但不知道为什么明明设置cron在某个时间运行,但任务却不间断的运行.无奈转用apscheduler,但是不管怎么设置都不能使得当调用 ...
- [转载]Require.js Example – Setup Time 2 Minutes
http://www.sitepoint.com/require-js-setup-time-2-minutes/ Setup Require.js in just 2 minutes. or dow ...
- 纯javascript代码实现浏览器图片选择预览、旋转、批量上传
工作中遇到的业务场景,和同事一起研究了下,主要是为了兼容IE版本 其实就是一些琐碎的知识点在网上搜集下解决方式,然后集成了下,主要有以下点: 1. IE input type=file的图片预览要用I ...
- 20155323 2016-2017-2 《Java程序设计》第7周学习总结
20155323 2016-2017-2 <Java程序设计>第7周学习总结 使用Lambda语法来代替匿名的内部类,代码不仅简洁,而且还可读. 时间的度量:GMT.UT.TAI.UTC. ...
- POJ 2230 Watchcow && USACO Watchcow 2005 January Silver (欧拉回路)
Description Bessie's been appointed the new watch-cow for the farm. Every night, it's her job to wal ...
- Entity Framework(EF的Model First方法)
EntityFramework,是Microsoft的一款ORM(Object-Relation-Mapping)框架.同其它ORM(如,NHibernate,Hibernate)一样, 一是为了使开 ...
- Java 8 Lambda表达式,让你的代码更简洁
Lambda表达式是Java 8一个非常重要的新特性.它像方法一样,利用很简单的语法来定义参数列表和方法体.目前Lambda表达式已经成为高级编程语言的标配,像Python,Swift等都已经支持La ...
- iOS学习笔记(1)— UIView 渲染和内容管理
iOS中应用程序基本上都是基于MVC模式开发的.UIView就是模型-视图-控制器中的视图,在iOS终端上看到的.摸到的都是UIView. UIView在屏幕上定义了一个矩形区域和管理区域内容的接口. ...