无限级分类,抓取某元素的所有下级id
mysql> select id,invite_qke_id from tf_qke;
+----+---------------+
| id | invite_qke_id |
+----+---------------+
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
+----+---------------+
rows in set (0.00 sec)
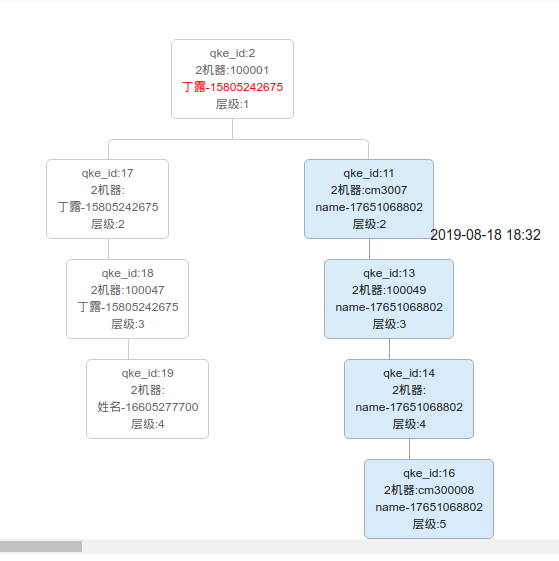
public function ttss(){
$id = 2;
$res = $this->son_ids($id,1);
dump($res);
}
public function son_ids($uid,$level,&$res_data = []){
$qkeModel = D('Qke');
if ($level == 1 && !$res_data){
$res_data[] = (string)$uid;
}
$sonlists = $qkeModel
->where(['invite_qke_id' => $uid])
->order('id desc')
->field('id,invite_qke_id')
->select();
if ($sonlists)
{
foreach ($sonlists as $k => $v)
{
echo $level;
// 这个拦截需在递归上面,放下面不行!!!!---防止最下级的下级是顶级,这样会陷入死循环!--会把服务器跑死!!!!!
if (in_array($v['id'],$res_data)){
continue;
}
$this->son_ids($v['id'],$level + 1,$res_data);
$res_data[] = $v['id'];
}
return $res_data;
}
}
<pre>
array(8) {
[0] => string(1) 2
[1] => string(2) 19
[2] => string(2) 18
[3] => string(2) 17
[4] => string(2) 16
[5] => string(2) 14
[6] => string(2) 13
[7] => string(2) 11
}
</pre>
无限级分类,抓取某元素的所有下级id的更多相关文章
- PHP 正则表达式的简单应用以 preg_match_all 抓取HTML元素为例 [转载]
PHP 正则表达式的简单应用以 preg_match_all 抓取HTML元素为例 2011-12-02 17:09:39| 分类: PHP|举报|字号 订阅 下载LOFTER我的照片书 ...
- find_elements后点击不了抓取的元素
1.莫名其妙抓不到元素,要去看句柄,是不是没有切换 h=driver.current_window_handle nh=driver.window_handles for i in nh: if i! ...
- Spider--动态网页抓取--审查元素
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,我们需要使用动态网页抓取技术. # Ajax: Asynchronou ...
- Python之抓取网页元素
import urllib.request from bs4 import BeautifulSoup url = "http://www.wal-martchina.com/walmart ...
- 教您使用java爬虫gecco抓取JD全部商品信息
gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定. JD网站的分析 要抓取JD网站的全部商品信息, ...
- Web自动化框架LazyUI使用手册(4)--控件抓取工具Elements Extractor详解(批量抓取)
概述 前面的一篇博文详细介绍了单个控件抓取的设计思路&逻辑以及使用方法,本文将详述批量控件抓取功能. 批量抓取:打开一个web页面,遍历页面上所有能被抓取的元素,获得每个元素的iframe.和 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
随机推荐
- 安装node.js 和 npm 的完整步骤
vue 生命周期 1,beforeCreate 组件刚刚被创建 2,created 组件创建完成 3,beforeMount 挂载之前 4,mounted 挂载之后 5,beforeDestory 组 ...
- windbg调试托管代码 .Net clr
现在很多的程序都是多语言混合编程的,比如我司的产品,就是用C++/.net clr混合编制的.那么当我们调试这样的程序时,一定要注意,比如有时我们只看到c++的栈和名称,而.net clr的代码确看不 ...
- UVA 11468 Substring (记忆化搜索 + AC自动鸡)
传送门 题意: 给你K个模式串, 然后,再给你 n 个字符, 和它们出现的概率 p[ i ], 模式串肯定由给定的字符组成. 且所有字符,要么是数字,要么是大小写字母. 问你生成一个长度为L的串,不包 ...
- setitimer()函数
定时器时间函数 struct itimerval: struct itimerval *new_value,其定义如下: struct itimerval { struct timeval it_in ...
- [golang]在Go中处理时区
许多新手开发人员在处理时区时感到困惑. 如何将它们存储在数据库中 如何在Go中解析它们 当将时区存储在数据库中时,请始终遵循一个标准时区,理想的做法是保存UTC时间,并在显示时区时根据需要将其转化为各 ...
- select和C标签
<select name="cpcyModel.rwzj" id="cpcyModel_rwzj"> <option value=" ...
- 和小哥哥一起刷洛谷(8) 图论之Floyd“算法”
关于floyd floyd是一种可以计算图中所有端点之间的最短的"算法",其伪代码如下: for(所有起点i) for(所有终点j) 如果i=j: i到j最短路设为0 如果i与j相 ...
- Image.FromFile 之后无法删除这个文件
Image.FromFile 之后无法删除这个文件 pictrue图片是从文件加载的,现在想换张图片,更改之前要删除原有的文件,在删除原有的文件出现了异常 string path = @" ...
- mac环境使用python处理protobuf
安装 brew install protobuf 然后再安装protobuf需要的依赖 brew install autoconf automake libtool 验证是否安装成功 protoc – ...
- 2018-2019-2 网络对抗技术 20165212 Exp7 网络欺诈防范
2018-2019-2 网络对抗技术 20165212 Exp7 网络欺诈防范 原理与实践说明 1.实践目标 理解常用网络欺诈背后的原理,以提高防范意识,并提出具体防范方法. 2.实践内容概述 简单应 ...