Java内存模型JMM简单分析
参考博文:http://blog.csdn.net/suifeng3051/article/details/52611310
http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html
http://www.cnblogs.com/dolphin0520/p/3613043.html
一、Java内存区域的划分
由于Java程序是交给JVM执行的,所以我们在谈Java内存区域分析的时候事实上是指JVM内存区域划分。
根据《Java虚拟机规范》的规定,运行时数据区通常包括这几个部分:程序计数器(Program Counter Register)、Java栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。
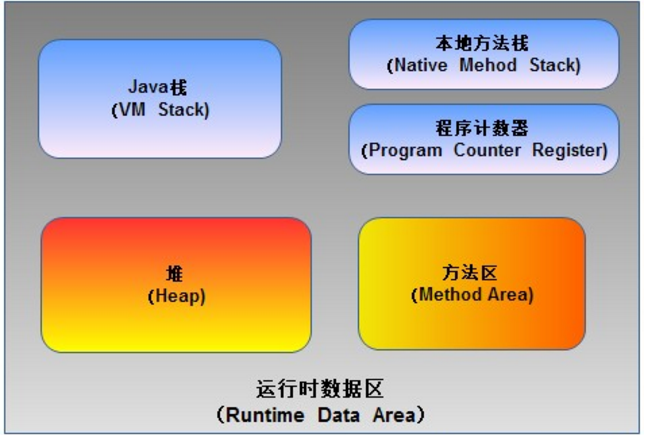
如上图所示,JVM中的运行时数据区应该包括这些部分。在JVM规范中虽然规定了程序在执行期间运行时数据区应该包括这几部分,但是至于具体如何实现并没有做出规定,不同的虚拟机厂商可以有不同的实现方式。
1.程序计数器:用来指示执行哪条命令
由于在JVM中,多线程是通过线程轮流切换来获得CPU执行时间的,因此,在任一具体时刻,一个CPU内核只会执行一条线程中的指令
因此,为了能够使得每个线程都在线程切换后能够恢复在切换之前的程序执行位置,每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序,
因此可以这么说,程序计数器是每个线程所私有的
2.Java栈:Java栈是Java方法执行的内存模型
Java栈中包含:
1.局部变量表(方法中局部变量) 2.操作数栈(程序中的所有计算过程都是在借助于操作数栈来完成的)
3.指向运行时常量池的引用(引用指向运行时常量) 4.方法返回地址(当一个方法执行完毕,要返回之前调用它的地方) 5.附加信息
由于每个线程正在执行的方法可能不同,因此每个线程都会有一个自己的Java栈,互不干扰
3.本地方法栈(为执行本地方法服务的)
本地方法栈与Java栈类似,区别只不过是Java栈是为执行Java方法服务器的,而本地方法栈则是为执行本地方法(Native Method)服务的
在HotSopt虚拟机中,直接就把本地方法栈和Java栈合二为一
4.堆
Java中的堆是用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。另外,堆是被所有线程共享的,在JVM中只有一个堆
堆内存包含三块:年轻代(年轻代分三个区。一个Eden区,两个 Survivor区(一般而言))、年老代、永久代(jdk1.8之前)
5.方法区
方法区与堆一样,是被线程共享的区域。在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译后的代码等
根据以上,网上有很多种说法没有说清楚:
我们说,创建一个线程时,会创建一个线程自己的工作内存,用于操作从主存拷贝过来的变量
所谓的线程的 工作内存 实际上 是对 CPU寄存器和高速缓存的抽象描述,(实际上是不存在的,只是为了帮助我们理解,而提出这个概念)
现在的计算机,cpu在计算的时候,并不总是从内存读取数据,它的数据读取顺序优先级 是:寄存器-高速缓存-内存。线程耗费的是CPU,线程计算的时候,原始的数据来自内存,在计算过程中,有些数据可能被频繁读取,这些数据被存储在寄存器 和高速缓存中,当线程计算完后,这些缓存的数据在适当的时候应该写回内存。当个多个线程同时读写某个内存数据时,就会产生多线程并发问题
实际上,线程创建的时候,只会为这个线程分配一个线程栈(当然,没有每个线程都有的程序计数器),后面我们提到的关于主存变量的拷贝,线程在工作内存去操作,都是基于寄存器和高速缓存抽象出来的
我们可以这样理解:
创建线程,一个线程会有一个线程栈,线程的工作内存就在这个栈中,一个方法调用就是一个栈帧。一个栈帧:局部变量区、操作数栈和帧数据区。
工作内存为局部变量区中的数据,这样理解实际上是错误的,原因我们上面说到了,但是找不到更好的类比方式了,
总:在线程中创建一个变量,是直接创建在主存上的
在线程中操作变量,是在寄存器和高速缓存中去操作,然后从缓存中刷新回主存的
拷贝的过程有没有呢?也是没有的,线程要操作主存中的变量,先看缓存中有没有,如果缓存中有,就在缓存中操作,如果缓存中没有,就去主存中操作
二、Java内存模型

||
抽象出
||
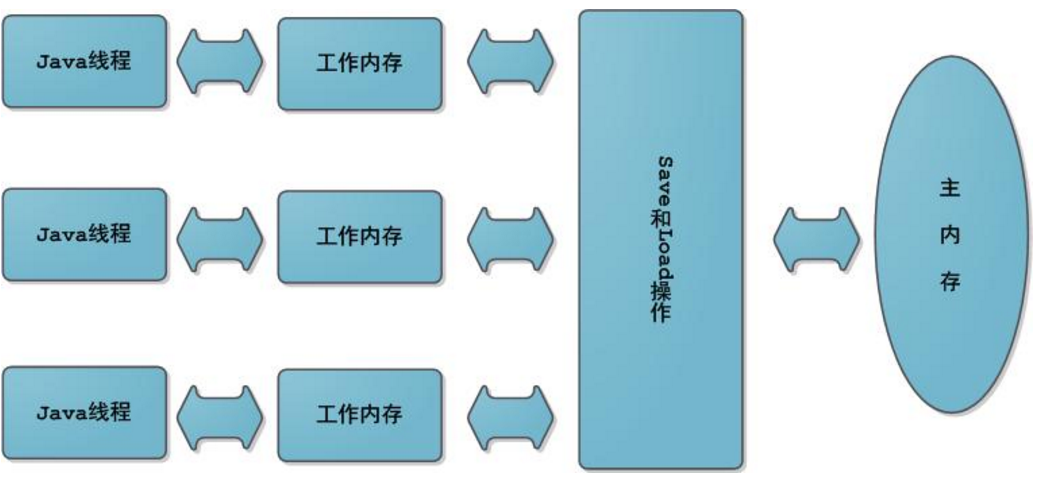
Java内存模型中规定了所有的变量都存储在主存中,每条线程还有自己的工作内存,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量,不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成
注:线程之间的通信
线程的通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种 共享内存和消息传递
消息传递:在java中典型的消息传递方式就是 wait() 和 notify()
共享内存:通过共享对象进行通信
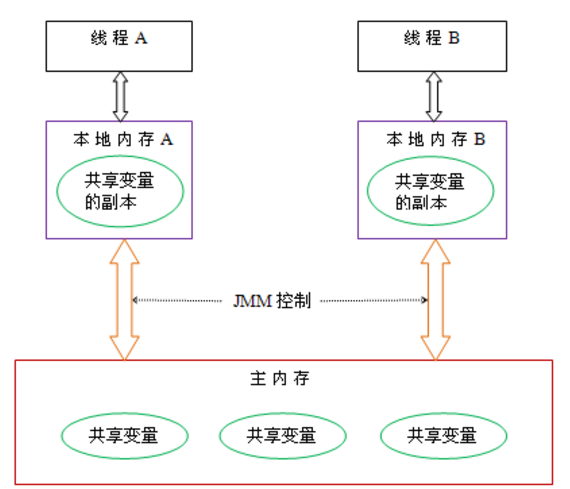
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
1.首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2. 然后,线程B到主内存中去读取线程A之前已更新过的共享变量。
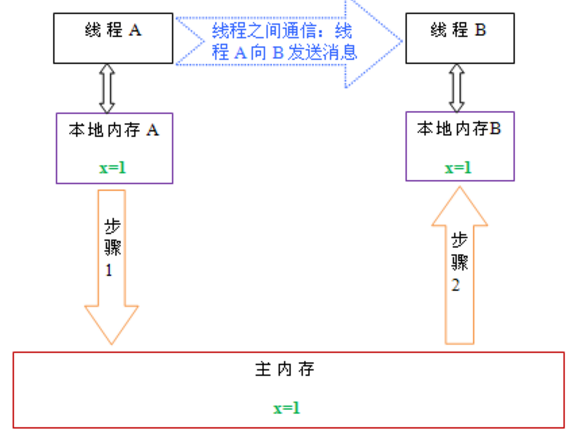
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。
(注:以下都是建立在Java内存模型的基础之上,抽象出现的,便于理解)
默认情况下,线程之间的工作内存是不可共享的,即A线程是看不到B线程的工作内存的,B线程从主存中copy了一份变量x,然后对这个变量进行操作
A是看不到B对x做了什么操作的,必须要等B将x的值刷新回内存,线程A才知道
在使用volatile关键字修饰变量x之后呢,volatile保存可见性的原理是在每次访问变量时都会进行一次刷新,因此每次访问都是主存中最新的版本
线程B从主存中copy了一份变量x,此时B对i进行操作后,会立即将更新后x的刷新回主存,A线程读取x的值时,刷新主存,得到的是x的最新值
最后可以理解为,线程是在主存上操作对象x(实际上不是,还是必须要在线程自己的工作空间上操作,只是有这个效果),线程之间 对于x对象都是可见的,
Java内存模型JMM简单分析的更多相关文章
- 全面理解Java内存模型(JMM)及volatile关键字(转载)
关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型(@Annotation) 深入理解Java类加载器(ClassLoad ...
- 全面理解Java内存模型(JMM)及volatile关键字(转)
原文地址:全面理解Java内存模型(JMM)及volatile关键字 关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型( ...
- Java内存模型JMM与可见性
Java内存模型JMM与可见性 标签(空格分隔): java 1 何为JMM JMM:通俗地讲,就是描述Java中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这 ...
- 多线程并发之java内存模型JMM
多线程概念的引入是人类又一次有效压寨计算机的体现,而且这也是非常有必要的,因为一般运算过程中涉及到数据的读取,例如从磁盘.其他系统.数据库等,CPU的运算速度与数据读取速度有一个严重的不平衡,期间如果 ...
- Java内存模型JMM 高并发原子性可见性有序性简介 多线程中篇(十)
JVM运行时内存结构回顾 在JVM相关的介绍中,有说到JAVA运行时的内存结构,简单回顾下 整体结构如下图所示,大致分为五大块 而对于方法区中的数据,是属于所有线程共享的数据结构 而对于虚拟机栈中数据 ...
- 对多线程java内存模型JMM
多线程概念的引入体现了人类重新有效压力寨计算机.这是非常有必要的,由于所涉及的读数据的过程中的一般操作,如从磁盘.其他系统.数据库等,CPU计算速度和数据读取速度已经严重失衡.假设印刷过程中一个线程将 ...
- 深入理解Java内存模型JMM与volatile关键字
深入理解Java内存模型JMM与volatile关键字 多核并发缓存架构 Java内存模型 Java线程内存模型跟CPU缓存模型类似,是基于CPU缓存模型来建立的,Java线程内存模型是标准化的,屏蔽 ...
- java内存模型(JMM)和happens-before
目录 重排序 Happens-Before 安全发布 初始化安全性 java内存模型(JMM)和happens-before 我们知道java程序是运行在JVM中的,而JVM就是构建在内存上的虚拟机, ...
- 深入理解Java内存模型JMM
本文转载自深入理解Java内存模型JMM JMM基础与happens-before 并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执 ...
随机推荐
- MySql通过数据库文件恢复数据库
以表”Table”为例: 如类型是MyISAM, 数据文件则以”Table.frm””Table.MYD””Table.MYI””三个文件存储于”/data/$databasename/”目录中. 如 ...
- linux升级python到2.7版本
linux的python安装包默认版本是2.6.6,yum程序默认也是依赖这个版本的python包的,但是其他一些程序如nodejs,却要的是2.7版本,因此必须要考虑升级后与yum的兼容问题.两步走 ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
- [转]windows 下 gcc/g++ 的安装
链接地址:https://www.jianshu.com/p/ff24a81f3637 不过下载地址直接进这里就可以了:https://sourceforge.net/projects/mingw/
- 【tensorflow基础】ubuntu-tensorflow可视化工具tensorboard-No dashboards are active for the current data set.
前言 今天基于tensorflow训练一个检测模型,本应看到训练曲线的,却只见到一个文件events.out.tfevents.1570520647.hostname,后来发现这个文件可以查看训练曲线 ...
- [LeetCode] 261. Graph Valid Tree 图是否是树
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), ...
- linux中安装cx_Oracle
https://blog.csdn.net/w657395940/article/details/41144225 各种尝试都,最后 pip install cx-Oracle 成功导入
- win10系统svn传图片卡死
win10系统svn传图片或者文件有时候会卡死,原因是此种文件的默认打开程序与svn冲突了 svn提交的时候要打开图片,但是图片默认打开程序也要打开 所以冲突了 改下不冲突的默认打开程序就行了 ...
- Linux的docker安装solr并创建core
查看solr列表 docker search solr 拉取solr镜像[注:这里默认latest],由于之前下载过 docker pull solr 启动一个做了端口映射的solr[-d:后台运行, ...
- [转帖]都在说DCEP,央行数字货币究竟跟你有什么关系?
都在说DCEP,央行数字货币究竟跟你有什么关系? https://kuaibao.qq.com/s/20191104A0G1D300?refer=spider 黄奇帆指出,DCEP 使得交易环节对 ...