Spark基于自定义聚合函数实现【列转行、行转列】
一.分析
Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现。但是这有明显的局限性【sqlContext不支持】,因此,基于编码逻辑或自定义聚合函数实现相同的逻辑就显得非常重要了。
二.列转行代码实现
package utils
import com.hankcs.hanlp.tokenizer.StandardTokenizer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{SparkSession, Row}
import org.apache.spark.sql.types.{StringType, StructType, StructField}
/**
* Created by Administrator on 2019/12/17.
*/
object Column2Row {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate()
val sc = spark.sparkContext
val sqlContext = spark.sqlContext val array : Array[String] = Array("spark-高性能大数据解决方案", "spark-机器学习图计算", "solr-搜索引擎应用广泛", "solr-ES灵活高效")
val rdd = sc.parallelize(array) val termRdd = rdd.map(row => { // 标准分词,挂载Hanlp分词器
var result = ""
val type_content = row.split("-")
val termList = StandardTokenizer.segment(type_content(1))
for(i <- 0 until termList.size()){
val term = termList.get(i)
if(!term.nature.name.contains("w") && !term.nature.name().contains("u") && !term.nature.name().contains("m")){
if(term.word.length > 1){
result += term.word + " "
}
}
}
Row(type_content(0),result)
}) val structType = StructType(Array(
StructField("arth_type", StringType, true),
StructField("content", StringType, true)
)) val termDF = sqlContext.createDataFrame(termRdd,structType)
termDF.show(false)
/**
* 列转行
*/
val termCheckDF = termDF.rdd.flatMap(row =>{
val arth_type = row.getAs[String]("arth_type")
val content = row.getAs[String]("content")
var res = Seq[Row]()
val content_array = content.split(" ")
for(con <- content_array){
res = res :+ Row(arth_type,con)
}
res
}).collect() val termListDF = sqlContext.createDataFrame(sc.parallelize(termCheckDF), structType)
termListDF.show(false) sc.stop()
}
}
三.列转行执行结果
列转行之前:

列转行:
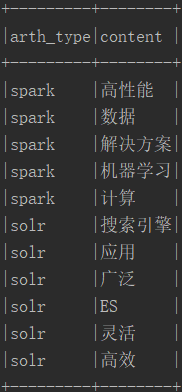
四.行转列代码实现
package test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
/**
* 自定义聚合函数实现行转列
*/
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction{
//聚合函数输入数据结构
override def inputSchema:StructType = StructType(StructField("input", StringType) :: Nil)
//缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("result", StringType) :: Nil)
//结果数据结构
override def dataType : DataType = StringType
// 是否具有唯一性
override def deterministic : Boolean = true
//初始化
override def initialize(buffer : MutableAggregationBuffer) : Unit = {
buffer(0) = ""
}
//数据处理 : 必写,其它方法可选,使用默认
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if(input.isNullAt(0)) return
if(buffer.getString(0) == null || buffer.getString(0).equals("")){
buffer(0) = input.getString(0) //拼接字符串
}else{
buffer(0) = buffer.getString(0) + "," + input.getString(0) //拼接字符串
}
}
//合并
override def merge(bufferLeft: MutableAggregationBuffer, bufferRight: Row): Unit ={
if(bufferLeft(0) == null || bufferLeft(0).equals("")){
bufferLeft(0) = bufferRight.getString(0) //拼接字符串
}else{
bufferLeft(0) = bufferLeft(0) + "," + bufferRight.getString(0) //拼接字符串
}
}
//计算结果
override def evaluate(buffer: Row): Any = buffer.getString(0)
}
/**
* Created by Administrator on 2019/12/17.
*/
object Row2Columns {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate()
val sc = spark.sparkContext
val sqlContext = spark.sqlContext
val array : Array[String] = Array("大数据-Spark","大数据-Hadoop","大数据-Flink","搜索引擎-Solr","搜索引擎-ES")
val termRdd = sc.parallelize(array).map(row => { // 标准分词,挂载Hanlp分词器
val content = row.split("-")
Row(content(0), content(1))
})
val structType = StructType(Array(
StructField("arth_type", StringType, true),
StructField("content", StringType, true)
))
val termDF = sqlContext.createDataFrame(termRdd,structType)
termDF.show()
termDF.createOrReplaceTempView("term")
/**
* 注册udaf
*/
spark.udf.register("concat_ws", AverageUserDefinedAggregateFunction)
spark.sql("select arth_type,concat_ws(content) content from term group by arth_type").show()
}
}
五.行转列执行结果
行转列之前:

行转列:

Spark基于自定义聚合函数实现【列转行、行转列】的更多相关文章
- mysql列转行 行转列
列转行 SELECT flag ,substring_index(substring_index(t.context,), ) as result FROM ( select 'aa' as flag ...
- Sqlserver 列转行 行转列
sqlserver的行转列 列转行问题 行转列:1 使用Case when 方式 CREATE TABLE [StudentScores]( [UserName] NVARCHAR(20), --学生 ...
- SQL 横转竖 、竖专横(转载) 列转行 行转列
普通行列转换 问题:假设有张学生成绩表(tb)如下: 姓名 课程 分数 张三 语文 张三 数学 张三 物理 李四 语文 李四 数学 李四 物理 想变成(得到如下结果): 姓名 语文 数学 物理 --- ...
- ORACLE 自定义聚合函数
用户可以自定义聚合函数 ODCIAggregate,定义了四个聚集函数:初始化.迭代.合并和终止. Initialization is accomplished by the ODCIAggrega ...
- SQL Server 自定义聚合函数
说明:本文依据网络转载整理而成,因为时间关系,其中原理暂时并未深入研究,只是整理备份留个记录而已. 目标:在SQL Server中自定义聚合函数,在Group BY语句中 ,不是单纯的SUM和MAX等 ...
- oracle 自定义 聚合函数
Oracle自定义聚合函数实现字符串连接的聚合 create or replace type string_sum_obj as object ( --聚合函数的实质就是一个对象 sum ...
- sql内置函数pivot强大的行转列功能
原文:sql内置函数pivot强大的行转列功能 语法: PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PIVO ...
- SQL Server 动态行转列(参数化表名、分组列、行转列字段、字段值)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 实现代码(SQL Codes) 方法一:使用拼接SQL,静态列字段: 方法二:使用拼接SQL, ...
- sql server 2012 自定义聚合函数(MAX_O3_8HOUR_ND) 计算最大的臭氧8小时滑动平均值
采用c#开发dll,并添加到sql server 中. 具体代码,可以用visual studio的向导生成模板. using System; using System.Collections; us ...
随机推荐
- 【Linux】查看端口和进程
netstat -tunlp ps -ef|grep process_name
- 【Matplotlib】使用速记
[持续更新] pyplot matplotlib.pyplot is a state-based interface to matplotlib. It provides a MATLAB-like ...
- Checking Types Against the Real World in TypeScript
转自:https://www.olioapps.com/blog/checking-types-real-world-typescript/ This is a follow-up to Type-D ...
- Python错误“ImportError: No module named MySQLdb”解决方法
这个错误可能是因为没有安装MySQL模块,这种情况下执行如下语句安装: pip install MySQLdb 如果安装时遇到错误“_mysql.c:29:20: 致命错误:Python.h:没有那个 ...
- 学习知识点的比较好的blog
树状数组 https://blog.csdn.net/flushhip/article/details/79165701 FFT https://blog.csdn.net/ggn_2015/arti ...
- ddns+ros(routeros)+centos7.6+nginx+php+dnspod
参考文章: http://www.myxzy.com/post-464.html https://www.cnblogs.com/crazytata/p/9686490.html php的源码下载: ...
- gcc命令详解
gcc命令使用GNU推出的基于C/C++的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点.目前,GCC可以用来编译C/C++.FORTRAN.JAVA.OBJC. ...
- promise、async和await
async:async function 声明将定义一个返回 AsyncFunction 对象的异步函数.当调用一个 async 函数时,会返回一个 Promise 对象.当这个 async 函数返回 ...
- json字符串手动拼接
return "xxx{" + "xxx='" + xxx+ '\'' + ", ggg='" + ggg+ '\'' + ", ...
- [转帖]SQL Server 2000~2017补丁包
SQL Server 2000~2017补丁包 https://www.cnblogs.com/VicLiu/p/11510510.html 最新更新 Product Version Latest S ...