hadoop作业
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
一、准备一个ubantu 系统
二、创建hadoop用户
创建

设密码

加入sudo权限

三、安装MySQL
更新软件资源库

安装mysql

开启mysql服务

四、安装java环境
下载jdk
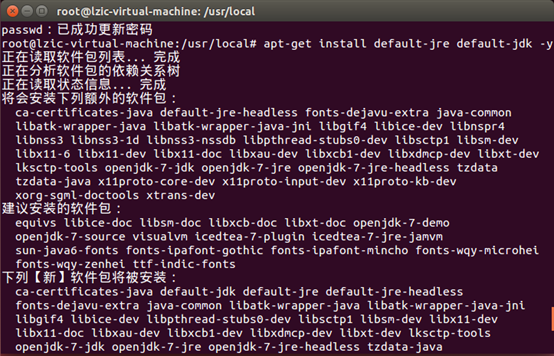
配置环境变量


检验环境变量

五、window使用xshell传文件到ubuntu
安装ssh
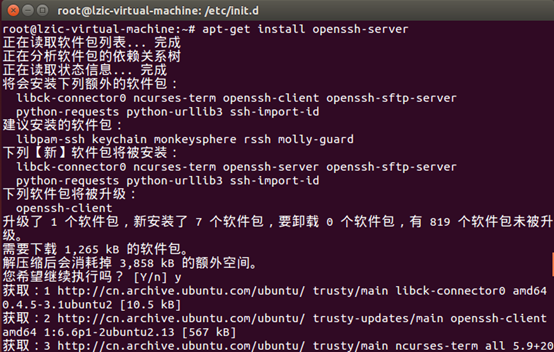
启动ssh和验证是否可以远程登录

生成密匙
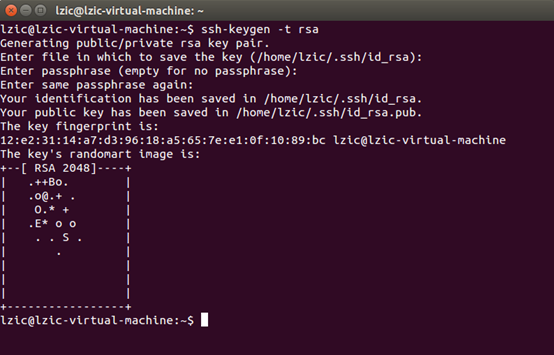
配置ssh无密码登录

window安装xsehll6
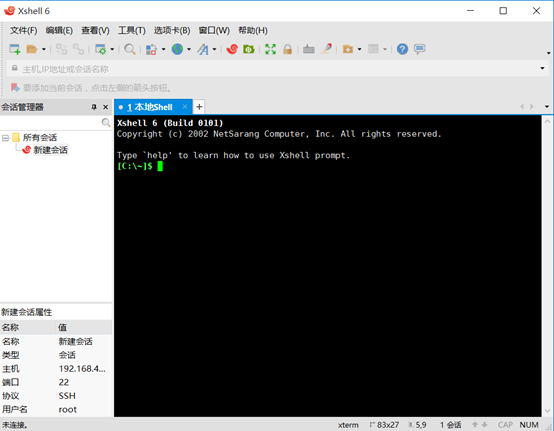
点击文件-->新建,输入Ubuntu的ip
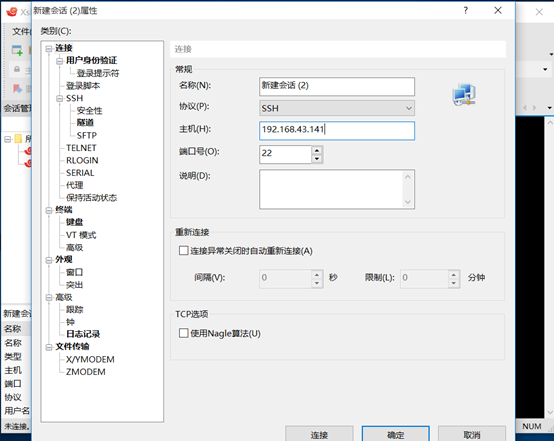
连接成功后,点击图中工具栏绿色按钮
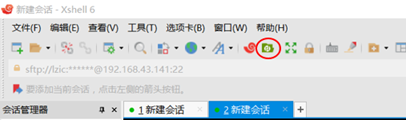
点击取消
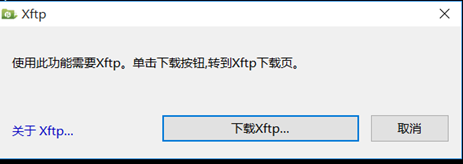
弹出一个新会话
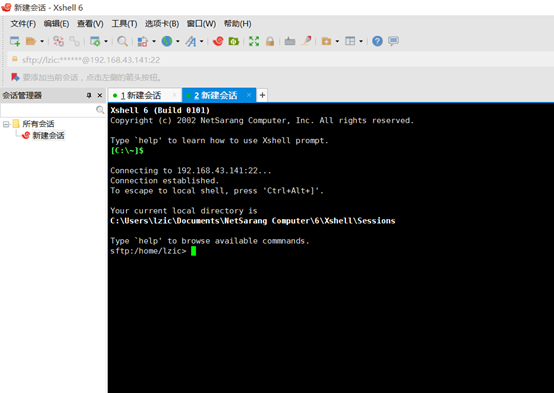
把文件拖动到新建会话黑色界面中就可传到Ubuntu。。
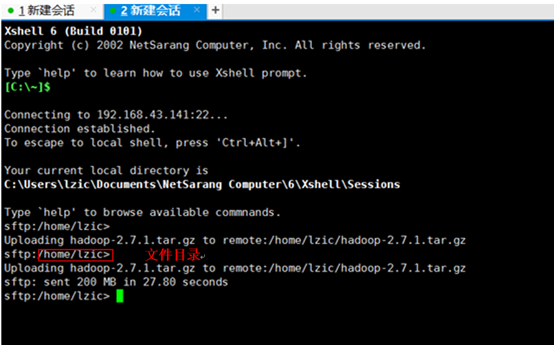
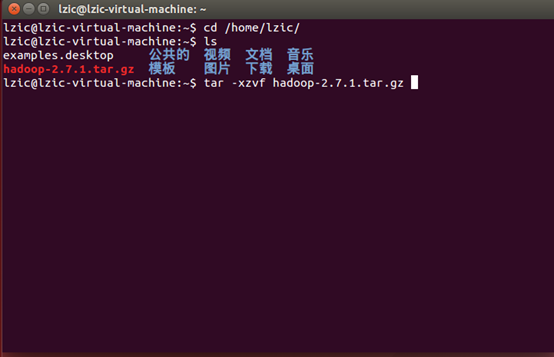
六、安装hadoop
解压
移动文件到 /usr/local目录
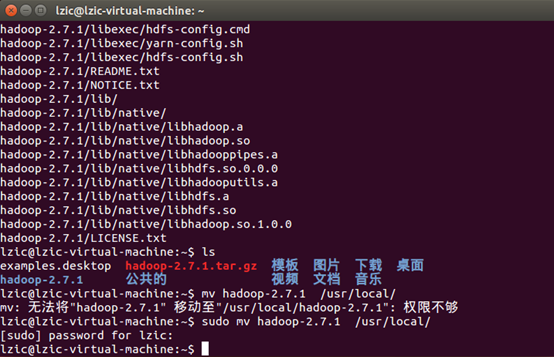
重命名文件夹
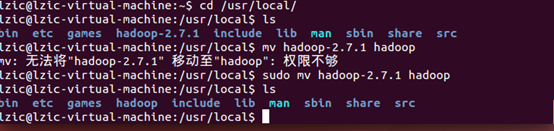
修改文件夹权限

检查hadoop是否可用
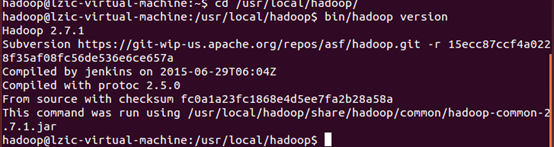
七、运行单机模式
运行grep例子



运行结果

八、运行伪分布模式
配置文件参考:https://www.cnblogs.com/MissDu/p/8831525.html
修改文件
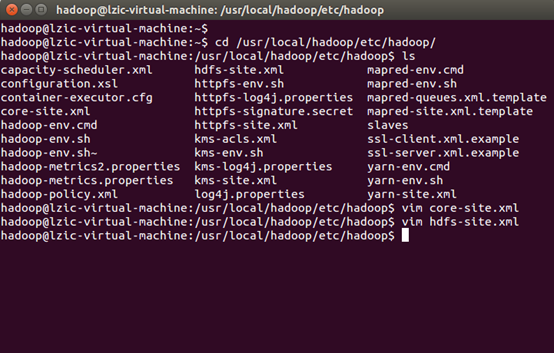
core-site.xml文件
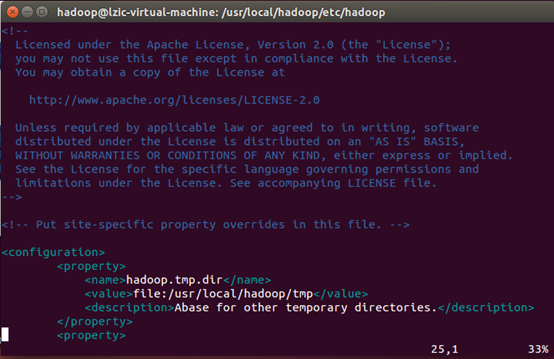
hdfs-site.xml文件

格式化NameNode

开启NameNode和DataNode失败,但是JAVA_HOME已经配置了
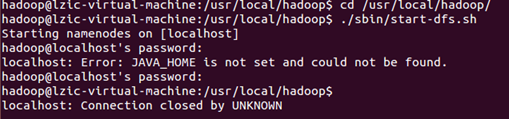
在网上找到原因,需要修改hadoop-env.sh文件


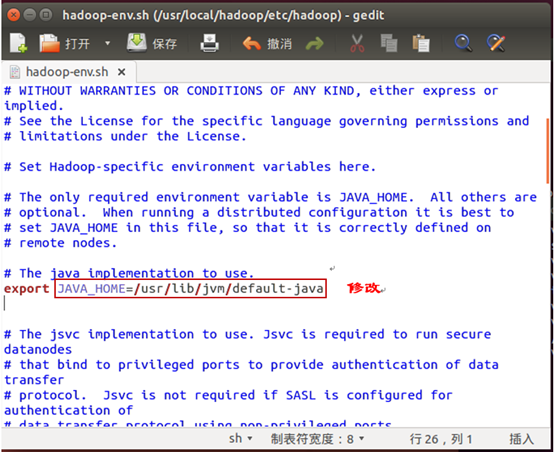
开启NameNode和DataNode成功
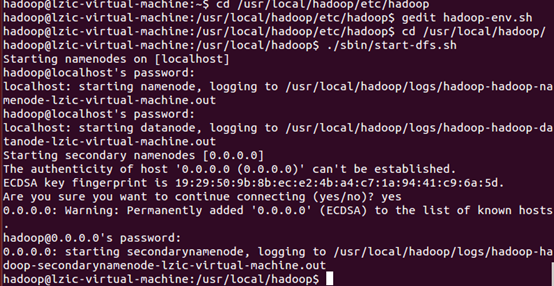
检测是否开启成功,成功则会出现下面进程

伪分布运行实例


运行结果

可把hdfs的output文件夹复制到本地

hadoop作业的更多相关文章
- Spark和Hadoop作业之间的区别
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的. 熟悉Hadoop的人应该都知道 ...
- 【hadoop代码笔记】hadoop作业提交之汇总
一.概述 在本篇博文中,试图通过代码了解hadoop job执行的整个流程.即用户提交的mapreduce的jar文件.输入提交到hadoop的集群,并在集群中运行.重点在代码的角度描述整个流程,有些 ...
- Hadoop作业提交之TaskTracker获取Task
[Hadoop代码笔记]Hadoop作业提交之TaskTracker获取Task 一.概要描述 在上上一篇博文和上一篇博文中分别描述了jobTracker和其服务(功能)模块初始化完成后,接收JobC ...
- 大数据 --> Spark和Hadoop作业之间的区别
Spark和Hadoop作业之间的区别 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个 ...
- hadoop作业调优参数整理及原理
hadoop作业调优参数整理及原理 10/22. 2013 1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并 ...
- Hadoop作业性能指标及參数调优实例 (三)Hadoop作业性能參数调优方法
作者: Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Had ...
- Hadoop作业性能指标及參数调优实例 (二)Hadoop作业性能调优7个建议
作者:Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Hado ...
- hadoop作业调度策略
一个Mapreduce作业是通过JobClient向master的JobTasker提交的(JobTasker一直在等待JobClient通过RPC协议提交作业),JobTasker接到JobClie ...
- Hadoop作业JVM堆大小设置优化 [转]
前段时间,公司Hadoop集群整体的负载很高,查了一下原因,发现原来是客户端那边在每一个作业上擅自配置了很大的堆空间,从而导致集群负载很高.下面我就来讲讲怎么来现在客户端那边的JVM堆大小的设置.我们 ...
- hadoop作业调优参数整理及原理(转)
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
随机推荐
- 如何给SAP云平台购买的账号分配Process Integration服务
在云平台控制台里,给global Account分配Integration Suite下面的Process Integration的API和Runtime两种服务: Process Integrati ...
- VirtualBox下设置 XP虚拟机桥接模式
virtualBox下设置虚拟机桥接模式
- 使用虹软ArcFac,java 离线SDK 进行人脸识别
公司项目需要人脸识别登录,需要支持离线识别,所以无法使用在线的人脸识别的API,于是使用到了离线SDK来对比识别人脸相识度. 获取人脸抓拍的图片需要对接设备,这里不做记录,假设我们已经获取到了人脸图片 ...
- leetcode 学习心得 (3)
源代码地址:https://github.com/hopebo/hopelee 语言:C++ 517. Super Washing Machines You have n super washing ...
- 最佳移动端h5自适应rem适配方案
一.利用lib-flexible.postcss-plugin-px2rem插件 进行移动端rem适配. 1.第一 引入lib-flexible . 安装lib-flexible: npm i lib ...
- 使用kubeadm 新加入节点(原始token过期后)---转发
kubeadm join kubeadm init 安装完成后你会得到以下的输出,使用join指令可以新增节点到集群,此token 有效期为24小时 You should now deploy a p ...
- session和cookie的区别和联系详解,Cookie Session相关看这篇就够了。
本文转自:91博客:原文地址:http://www.9191boke.com/199015867.html 有一朋友做面试官的时候,曾经问过很多朋友这个问题: Cookie 和 Session 有什么 ...
- 调整DataTable的列顺序
地址:https://www.cnblogs.com/gaocong/p/6490159.html 标题:DataTable 修改列名 删除列 调整列顺序 DataTable myDt =dt; // ...
- 编译heartbeat出现的问题
如报 cc1: warnings being treated as errors pils.c:245: error: initialization fromincompatible pointer ...
- Codeforces G. Ant colony
题目描述: F. Ant colonytime limit per test1 secondmemory limit per test256 megabytesinputstandard inputo ...