hadoop作业
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
一、准备一个ubantu 系统
二、创建hadoop用户
创建

设密码

加入sudo权限

三、安装MySQL
更新软件资源库

安装mysql

开启mysql服务

四、安装java环境
下载jdk
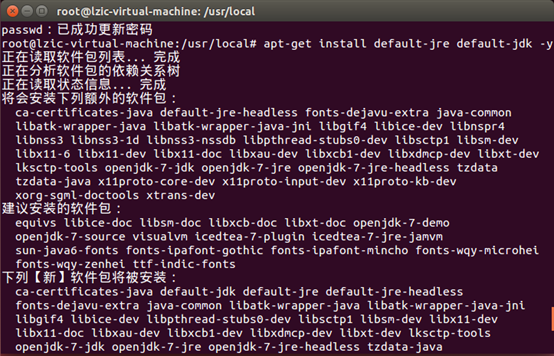
配置环境变量


检验环境变量

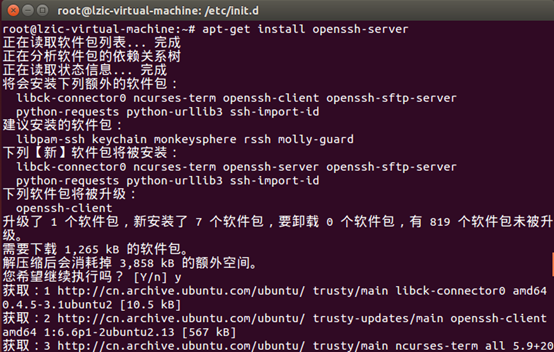
五、window使用xshell传文件到ubuntu
安装ssh
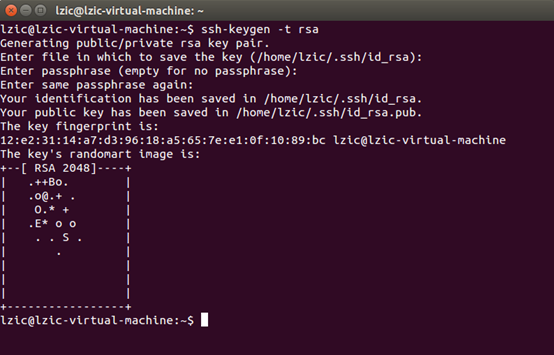
启动ssh和验证是否可以远程登录

生成密匙
配置ssh无密码登录

window安装xsehll6
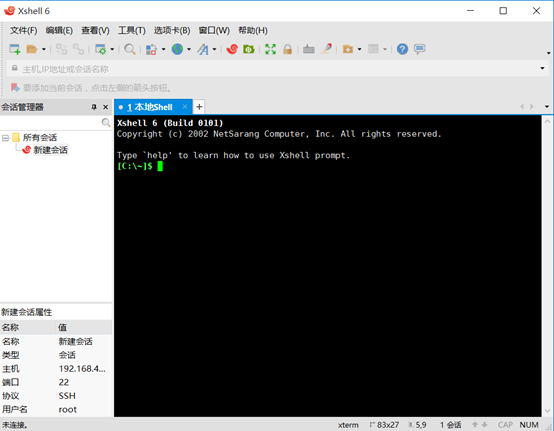
点击文件-->新建,输入Ubuntu的ip
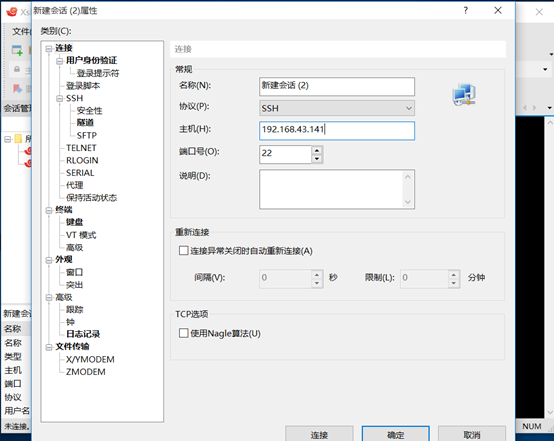
连接成功后,点击图中工具栏绿色按钮
点击取消
弹出一个新会话
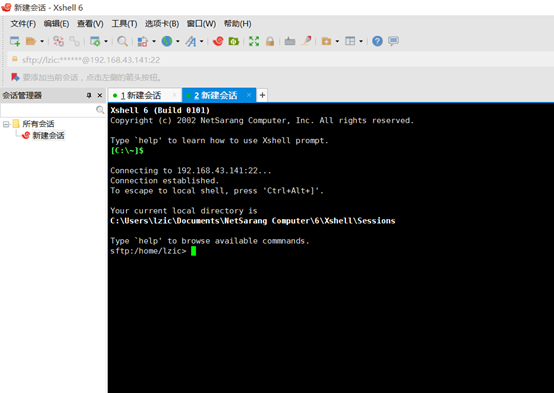
把文件拖动到新建会话黑色界面中就可传到Ubuntu。。
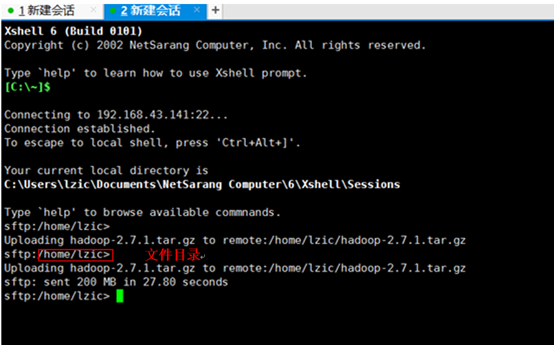
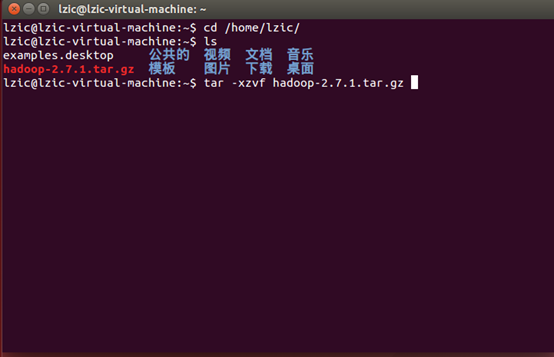
六、安装hadoop
解压
移动文件到 /usr/local目录
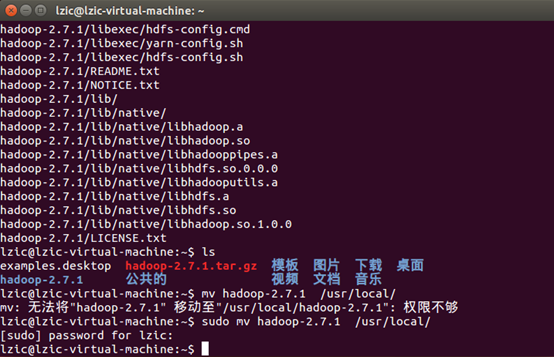
重命名文件夹
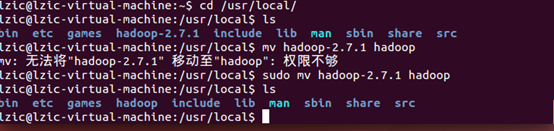
修改文件夹权限

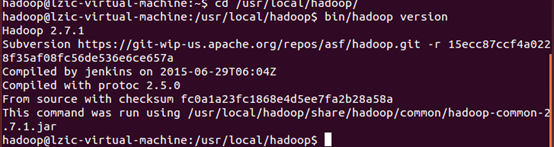
检查hadoop是否可用
七、运行单机模式
运行grep例子



运行结果

八、运行伪分布模式
配置文件参考:https://www.cnblogs.com/MissDu/p/8831525.html
修改文件
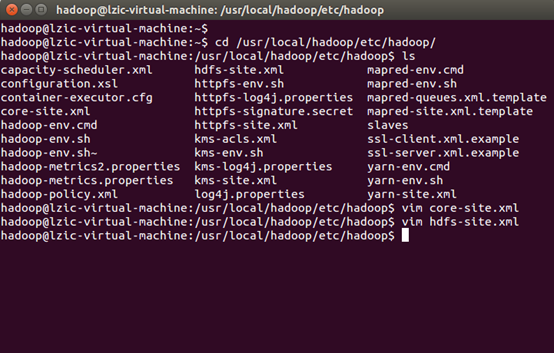
core-site.xml文件
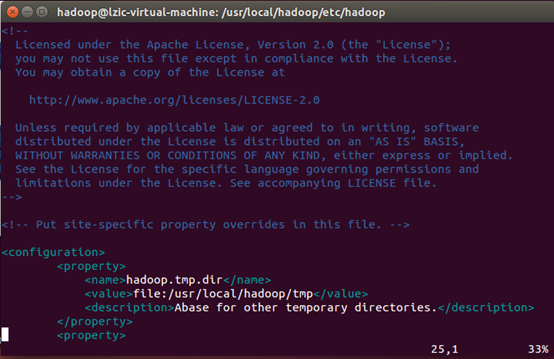
hdfs-site.xml文件

格式化NameNode

开启NameNode和DataNode失败,但是JAVA_HOME已经配置了
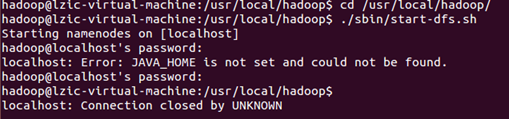
在网上找到原因,需要修改hadoop-env.sh文件


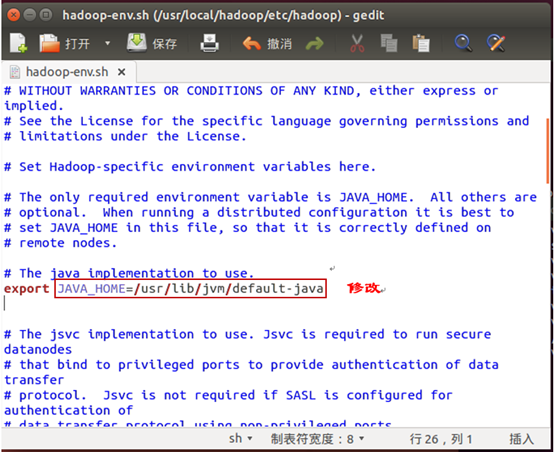
开启NameNode和DataNode成功
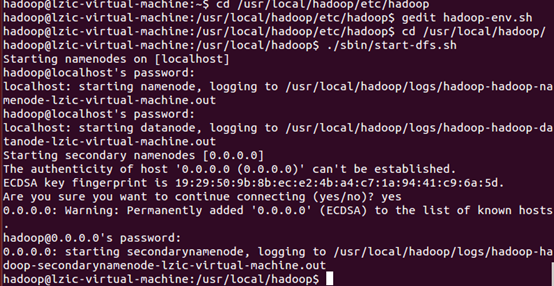
检测是否开启成功,成功则会出现下面进程

伪分布运行实例


运行结果

可把hdfs的output文件夹复制到本地

hadoop作业的更多相关文章
- Spark和Hadoop作业之间的区别
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的. 熟悉Hadoop的人应该都知道 ...
- 【hadoop代码笔记】hadoop作业提交之汇总
一.概述 在本篇博文中,试图通过代码了解hadoop job执行的整个流程.即用户提交的mapreduce的jar文件.输入提交到hadoop的集群,并在集群中运行.重点在代码的角度描述整个流程,有些 ...
- Hadoop作业提交之TaskTracker获取Task
[Hadoop代码笔记]Hadoop作业提交之TaskTracker获取Task 一.概要描述 在上上一篇博文和上一篇博文中分别描述了jobTracker和其服务(功能)模块初始化完成后,接收JobC ...
- 大数据 --> Spark和Hadoop作业之间的区别
Spark和Hadoop作业之间的区别 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个 ...
- hadoop作业调优参数整理及原理
hadoop作业调优参数整理及原理 10/22. 2013 1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并 ...
- Hadoop作业性能指标及參数调优实例 (三)Hadoop作业性能參数调优方法
作者: Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Had ...
- Hadoop作业性能指标及參数调优实例 (二)Hadoop作业性能调优7个建议
作者:Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Hado ...
- hadoop作业调度策略
一个Mapreduce作业是通过JobClient向master的JobTasker提交的(JobTasker一直在等待JobClient通过RPC协议提交作业),JobTasker接到JobClie ...
- Hadoop作业JVM堆大小设置优化 [转]
前段时间,公司Hadoop集群整体的负载很高,查了一下原因,发现原来是客户端那边在每一个作业上擅自配置了很大的堆空间,从而导致集群负载很高.下面我就来讲讲怎么来现在客户端那边的JVM堆大小的设置.我们 ...
- hadoop作业调优参数整理及原理(转)
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
随机推荐
- html5的基本介绍
前言 (1)什么是HTML? 指超文本标记语言(Hyper Text Markup Language); 是用来描述网页的一种语言: 不是编程语言,是一种标记语言: (更多详细内容,百度:https: ...
- nginx-1.12.0安装
1.配置相关环境: yum install -y gcc glibc gcc-c++ zlib pcre-devel openssl-devel rewrite模块需要pcre库 ssl功能需要ope ...
- redhat7.2下VNC没法显示图像
1,Symptom /root/.vnc/HR-ECC-PRD-02:1.log内容有信息如下: VNCSconnST: Server default pixel fromat depth 24 (3 ...
- java-Ehcache缓存
springmvc配置文件: <beans .... xmlns:cache="http://www.springframework.org/schema/cache" xs ...
- 如何寻找sql注入漏洞?
1.sql注入是怎么产生的 2.如何寻找sql注入漏洞 在地址栏输入单双引号造成sql执行异常(get) post请求,在标题后输入单引号,造成sql执行异常.
- 2019年牛客多校第一场 I题Points Division 线段树+DP
题目链接 传送门 题意 给你\(n\)个点,每个点的坐标为\((x_i,y_i)\),有两个权值\(a_i,b_i\). 现在要你将它分成\(\mathbb{A},\mathbb{B}\)两部分,使得 ...
- docker学习3-镜像的基本使用
前言 Docker的三大核心概念:镜像.容器.仓库.初学者对镜像和容器往往分不清楚,学过面向对象的应该知道类和实例,这跟面向对象里面的概念很相似 我们可以把镜像看作类,把容器看作类实例化后的对象. d ...
- 解决SELinux导致Apache更改端口后无法启动的问题
systemctl start httpd # 将Apache的默认端口改为90后,启动Apache时提示失败 systemctl status httpd # 查看Apache的状态 可 ...
- 【http】认识HTTP
HTTP基础概念 我们学计算机网络的时候就知道,我们把计算机网络分层了5层,一般我们现在用的都是TCP/IP这么一个分层结构. 虽然官方的是ISO 提出的7层结构,但是仅仅是理论基础,在实际上大多人都 ...
- 192-0070 Final project proposal
Final project proposal192-00701 – Summary of your project.It is based on an existing game which is c ...