JPA逆向工程
1.1 说明
所谓的逆向工程就是通过数据库的结构生成代码。
目的:提高开发的效率
|
|
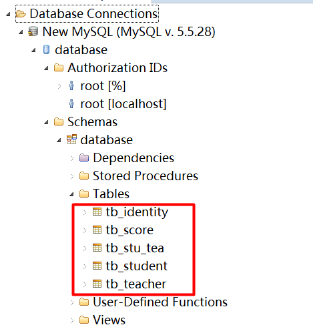
1.2 步骤
1.2.1 第一步:创建JPA项目
(1)创建项目
|
|
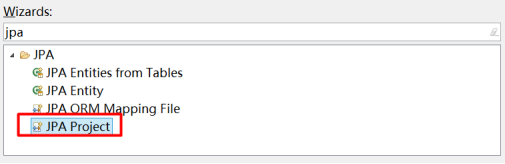
(2)指定项目名、JPA版本
|
|
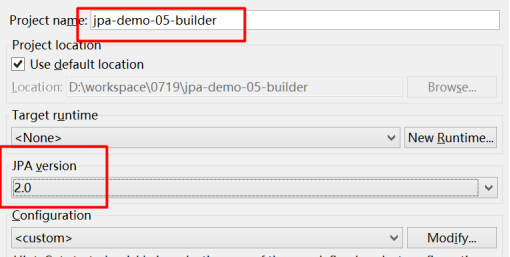
(3)完成创建
|
|
1.2.2 第二步:生成JPA代码
右击项目的src文件夹,选择new --> Other.. -->JPA的JPA Entities from Tables
1.2.2.1 Step1:创建新的数据库连接
(1)选择新建数据库连接
|
|
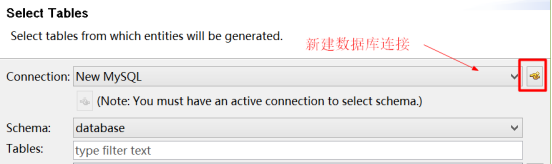
(2)指定数据库类型
|
|
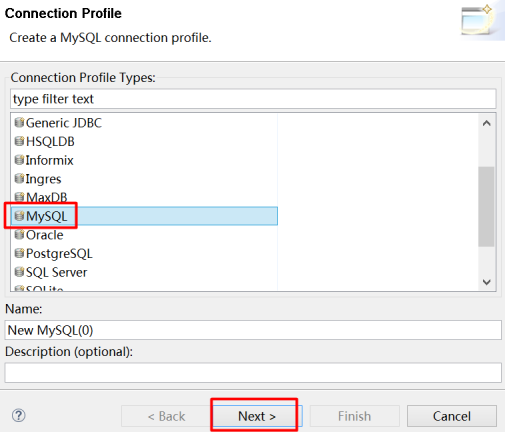
(3)新建数据库驱动
|
|

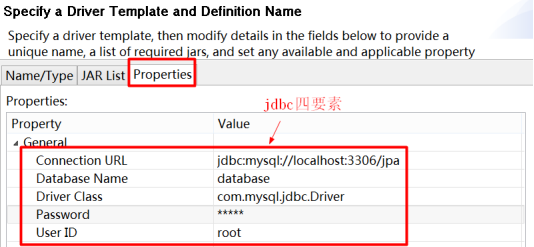
(4)配置驱动信息
驱动版本号
|
|
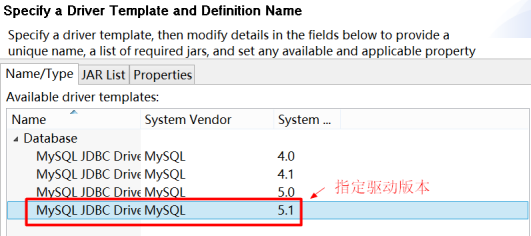
加载驱动jar包
|
|
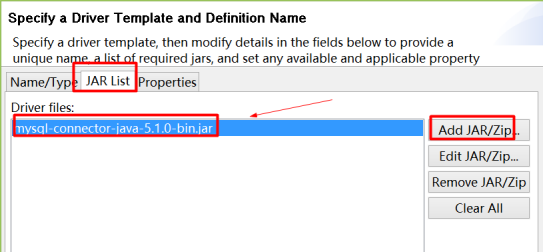
配置jdbc四要素
|
|
1.2.2.2 Step2:配置表与表直接的关联关系
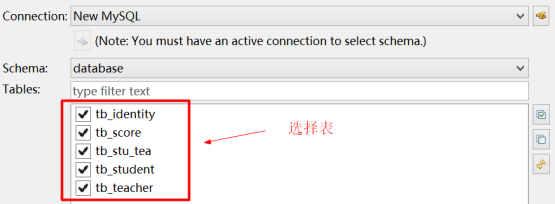
(1)配置表关联关系
选择表,全选即可。
|
|
配置Student、Score一对多
|
|
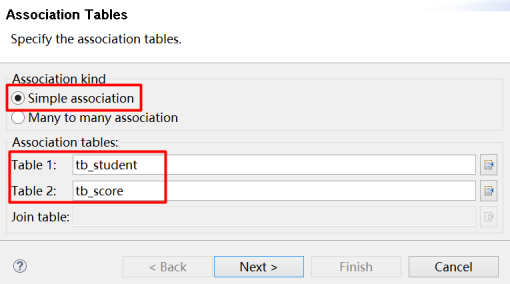
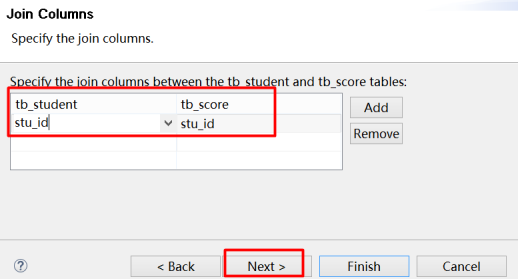
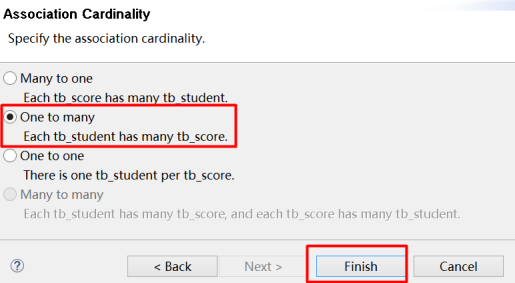
依次配置其它的关联关系即可。
|
|

1.2.2.3 Step3:指定生成实体类的名称及结构
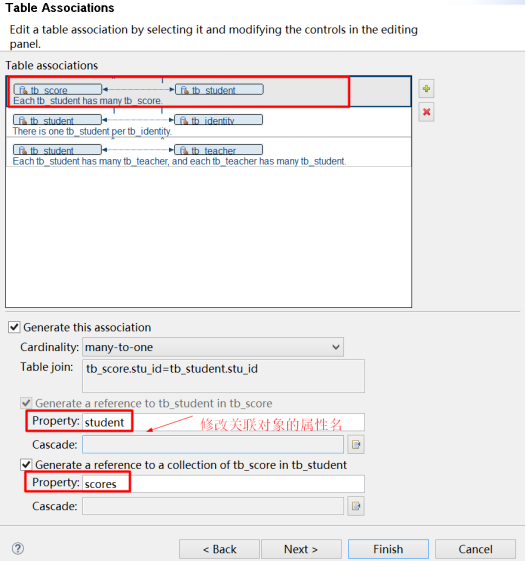
(1)修改关联对象的属性名
|
|
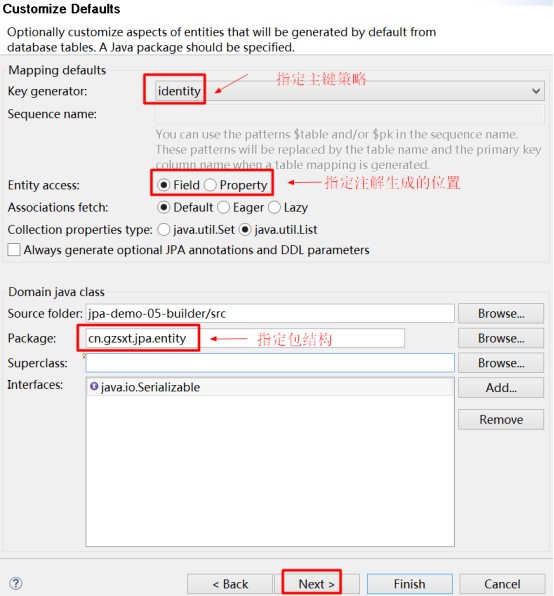
指定实体类的生成属性
|
|
指定实体类的类名
|
|
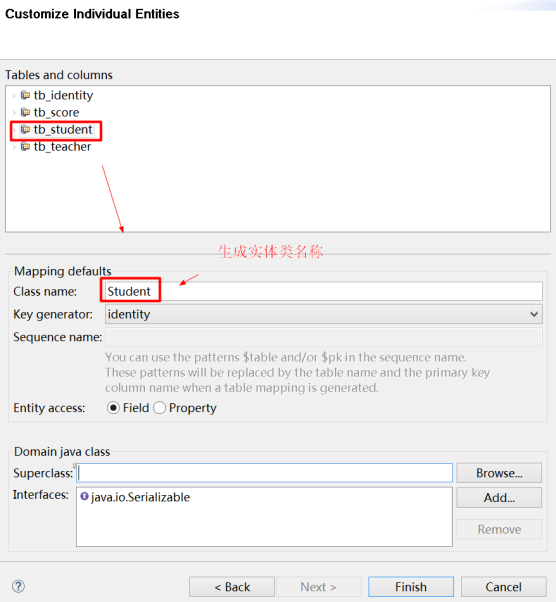
依次修改其它类的属性即可。
1.2.2.4 Step4:生成代码
|
|
1.2.3 第三步:导入所需jar依赖
说明:Maven项目是可以导入jar包到本地的。
方法:打开DOS窗口,进入项目的pom文件所在目录,执行命令:
mvn dependency:copy-dependencies
前提:已经配置了Maven环境变量。
|
|
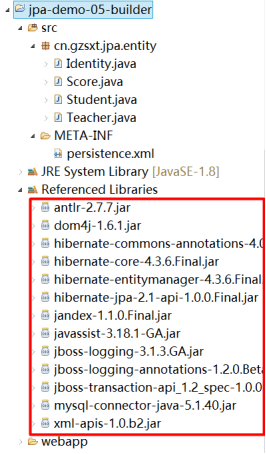
1.2.4 第四步:更新项目
|
|
2 JPQL语言
2.1 说明
JPQL : Java Persistence Query Language : java持久化查询语言。
它的作用是通过类似SQL的语法去操作实体类的对象。
语法和SQL一样的,SQL操作的数据表,JPQL操作的对象
作用:实现个性化的查询需求
2.2 示例代码
|
package cn.zj.jpa; import java.util.List; import javax.persistence.EntityManager; import javax.persistence.EntityTransaction; import javax.persistence.Query; import javax.persistence.TypedQuery; import org.junit.Test; import cn.zj.jpa.entity.Student; import cn.zj.jpa.util.JPAUtils; public class StudentDAOTest { //1.查询所有学生的信息 @Test public void findAll(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得JPQL查询对象 //标准的JPQL是必须要使用select //select语法: select 别名 from 类名 别名 TypedQuery<Student> query = manager.createQuery("select s from Student s", Student.class); //返回多条查询的数据,getResultList //TypedQuery解决了HIbernate返回有警告的问题 List<Student> students = query.getResultList(); for (Student student : students) { System.out.println("学生名:"+student.getStuName()); } manager.close(); } //2.条件查询 //需求:查询名字有张字的学生 //注意:JPQL的语法,使用?设置参数,必须要在?后面设置下标值,下标值不能为负数 @Test public void findByCondition(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得JPQL查询对象 //标准的JPQL是必须要使用select TypedQuery<Student> query = manager.createQuery("select s from Student s where s.stuName like ?1", Student.class); //3.设置条件 query.setParameter(1, "%张%"); List<Student> students = query.getResultList(); for (Student student : students) { System.out.println("学生名:"+student.getStuName()); } manager.close(); } @Test public void findByCondition1(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得JPQL查询对象 //标准的JPQL是必须要使用select TypedQuery<Student> query = manager.createQuery("select s from Student s where s.stuName like :stuName", Student.class); //3.设置条件 query.setParameter("stuName", "%张%"); List<Student> students = query.getResultList(); for (Student student : students) { System.out.println("学生名:"+student.getStuName()); } manager.close(); } //需求:返回学生表的记录数 @Test public void count(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得JPQL查询对象 //标准的JPQL是必须要使用select //JPQL中的count操作返回值是Long值,所以用Long类型接收 TypedQuery<Long> query = manager.createQuery("select count(s) from Student s", Long.class); //如果返回的是一个值的查询,使用getSingleResult Long count = query.getSingleResult(); System.out.println(count); manager.close(); } //需求:第二页,每页三条 @Test public void findByPage(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得JPQL查询对象 //标准的JPQL是必须要使用select TypedQuery<Student> query = manager.createQuery("select s from Student s", Student.class); //设置分页条件 //1.设置开始位置,下标从0开始,第四条数据的下标为3 query.setFirstResult(3); //2.设置每页的记录 query.setMaxResults(3); List<Student> students = query.getResultList(); for (Student student : students) { System.out.println("学生名:"+student.getStuName()); } manager.close(); } /* * 命名查询语句的调用 * * 所谓的命名查询,就是在实体类对象使用一个名字声明一条JPQL语句 * 这样可以通过name值获得Query的语句 * * 命名查询,在类名上做如下声明: @NamedQuery(name="Student.findAll", query="SELECT s FROM Student s") public class Student { */ @Test public void findAllByNamedQuery(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); //2.获得一个查询命名查询语句的对象 //可以通过该对象调用实体类声明的命名查询语句 TypedQuery<Student> query = manager.createNamedQuery("Student.findAll", Student.class); List<Student> students = query.getResultList(); for (Student student : students) { System.out.println(student.getStuName()); } manager.close(); } //需求:通过JQOL删除有张字的学生 @Test public void removeByCondition(){ //1获得操作对象 EntityManager manager = JPAUtils.getEntityManager(); EntityTransaction transaction = manager.getTransaction(); transaction.begin(); try { //2.获得JPQL查询对象 //注意,调用操作的JPQL是不需要指定返回的类型 Query query = manager.createQuery("delete from Student s where s.stuName like ?1"); //参数对应?设置的下标值 query.setParameter(1, "%张%"); int count = query.executeUpdate(); System.out.println(count); transaction.commit(); manager.close(); } catch (Exception e) { transaction.rollback(); e.printStackTrace(); } } } |
2.3 JPQL补充:N+1问题
在一对多或者多对多查询过程中,首先查询1这一方的数据,然后根据1这一份的数据,查询多的一方的数据。
当学生有N个的时候,总共查询次数N+1次。
这个就称之为N+1问题
当我们数据库的量不大的时候,N+1问题基本没有什么影响。如果当数据量很大的时候,查询数据库的次数,就很大了,这个就会影响数据库的性能。
如何解决这个问题?
可以通过JPQL来解决。
|
@Test public void one2manybyOne(){ //1、获取实体操作对象 EntityManager manager = JPAUtils.getEntityManager(); //JPQL是通过fetch这个关键词,在查询学生的信息的时候,一起将分数也查询出来 //最终执行的sql就只有一条 TypedQuery<Student> query = manager.createQuery("select distinct s from Student s inner join fetch s.scores", Student.class); List<Student> students = query.getResultList(); for (Student student : students) { System.out.println("学生姓名:"+student.getStuName()+",学生id:"+student.getStuId()); List<Score> scores = student.getScores(); for (Score score : scores) { System.out.println("科目:"+score.getScoSubject()+",分数:"+score.getScoScore()); } System.out.println("---------------------------------"); } } |
执行结果:
|
|
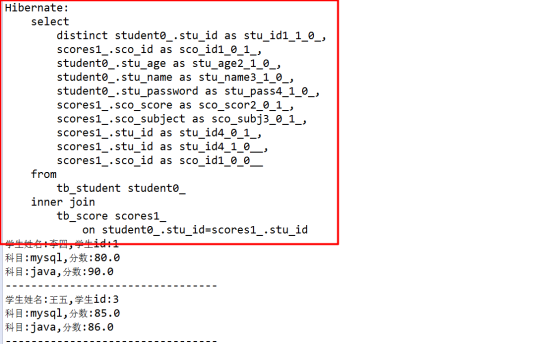
执行过程中,确实一条sql语句!!!
解决了频繁查询数据库,带来的数据库性能损耗。
JPA逆向工程的更多相关文章
- SpringBoot 阶段测试 1
SpringBoot 阶段测试 1 目录 SpringBoot 阶段测试 1 1.使用JDK8新语法完成下列集合练习: 1.1 List中有1,2,3,4,5,6,7,8,9几个元素要求; (1) 将 ...
- SpringBoot (四) - 整合Mybatis,逆向工程,JPA
1.SpringBoot整合MyBatis 1.1 application.yml # 数据源配置 spring: datasource: driver-class-name: com.mysql.c ...
- SpringBoot+Mybatis+Maven+MySQL逆向工程实现增删改查
SpringBoot+Mybatis+MySQL+MAVEN逆向工程实现增删改查 这两天简单学习了下SpringBoot,发现这玩意配置起来是真的方便,相比于SpringMVC+Spring的配置简直 ...
- MyEclipse使用教程:使用REST Web Services管理JPA实体
MyEclipse 在线订购专享特惠!火爆开抢>> MyEclipse最新版下载 使用REST Web Services来管理JPA实体.在逆向工程数据库表后生成REST Web服务,下面 ...
- 用MyEclipse JPA创建项目(二)
MyEclipse 3.15 Style——在线购买低至75折!火爆开抢>> [MyEclipse最新版下载] 本教程介绍了MyEclipse中的一些基于PA的功能. 阅读本教程时,了解J ...
- MyEclipse持续性开发教程:用JPA和Spring管理数据(二)
MyEclipse红运年货节 在线购买低至69折!火爆开抢>> [MyEclipse最新版下载] 本教程介绍了MyEclipse中的一些基于JPA / Spring的功能.有关设置JPA项 ...
- 用MyEclipse JPA创建项目
http://www.myeclipsecn.com/learningcenter/persistence-development/myeclipse-jpa/ 用MyEclipse JPA创建项目 ...
- 为什么放弃Hibernate、JPA、Mybatis,最终选择JDBCTemplate
一.前言 因为项目需要选择数据持久化框架,看了一下主要几个流行的和不流行的框架,对于复杂业务系统,最终的结论是,JOOQ是总体上最好的,可惜不是完全免费,最终选择JDBC Template. Hibe ...
- 快速搭建springmvc+spring data jpa工程
一.前言 这里简单讲述一下如何快速使用springmvc和spring data jpa搭建后台开发工程,并提供了一个简单的demo作为参考. 二.创建maven工程 http://www.cnblo ...
随机推荐
- 微信小程序丨将溢出的文本用省略号代替的方法
下面进入正题,有关于将溢出的文本用省略号代替的方法,不知道什么原因,我的程序用传统的代码无法解决: .text{ white-space: nowrap; overflow: hidden; text ...
- onenote 每天输入网络密码
1.问题:只局限 内网 笔记本的弹出输入远程内网服务器用户名密码的情况,每次重启电脑后又会要求输入,否则同步失败 2.解决 控制面板-windows用户-凭据管理器-添加凭据-从上到下一次输入 ip ...
- How to: Secure Connection Strings When Using Data Source Controls
https://docs.microsoft.com/en-us/previous-versions/dotnet/netframework-3.0/dx0f3cf2(v=vs.85) When wo ...
- FineReport 交叉报表
交叉报表 - FineReport报表官网http://www.finereport.com/knowledge/professional/crossreport.html FineReport--- ...
- winddows rabbitmq安装与配置
RabbitMQ是一个在AMQP协议标准基础上完整的,可复用的企业消息系统.它遵循Mozilla Public License开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,Rab ...
- MWC飞控增加声纳定高的方法(转)
源: MWC飞控增加声纳定高的方法
- cordova run android 可能遇到的错误解决
运行: ionic cordova build 等待下载,然后根据提示 输入android或者ios平台,即可 运行cordova run android 报错: 最快捷的解决方法就是使用Androi ...
- 【转】Python常见web系统返回码
responses = { 100: ('Continue', 'Request received, please continue'), 101: ('Switching Protocols', ' ...
- openresty开发系列30--openresty中使用http模块
OpenResty默认没有提供Http客户端,需要使用第三方提供的插件 我们可以从github上搜索相应的客户端,比如https://github.com/pintsized/lua-resty-ht ...
- Tekla 导出ifc并浏览
Tekla导出IFC