论文阅读笔记五十九:Res2Net: A New Multi-scale Backbone Architecture(CVPR2019)

论文原址:https://arxiv.org/abs/1904.01169
摘要
视觉任务中多尺寸的特征表示十分重要,作为backbone的CNN的对尺寸表征能力越强,性能提升越大。目前,大多数多尺寸的表示方法是layer-wise的。本文提出的Res2Net通过在单一残差块中对残差连接进行分级,进而可以达到细粒度层级的多尺度表征,同时,提高了网络每层的感受野大小。该Res2Net结构可以嵌入到其他网络模型中。
介绍
在自然场景中,视觉模式经常表现多尺寸特征。如下图所示,(1)一张图片中可能会存在不同尺寸的物体。比如,沙发及被子的大小是不同的。(2)一个物体自身的上下文信息可能会覆盖比自身更大范围的区域。比如,依赖于桌子的上下文信息,进而判断桌子上的黑色斑点是杯子还是笔筒。(3)不同尺寸的感知信息对于像细粒度分类及分割等对于理解目标物局部信息的任务十分重要。
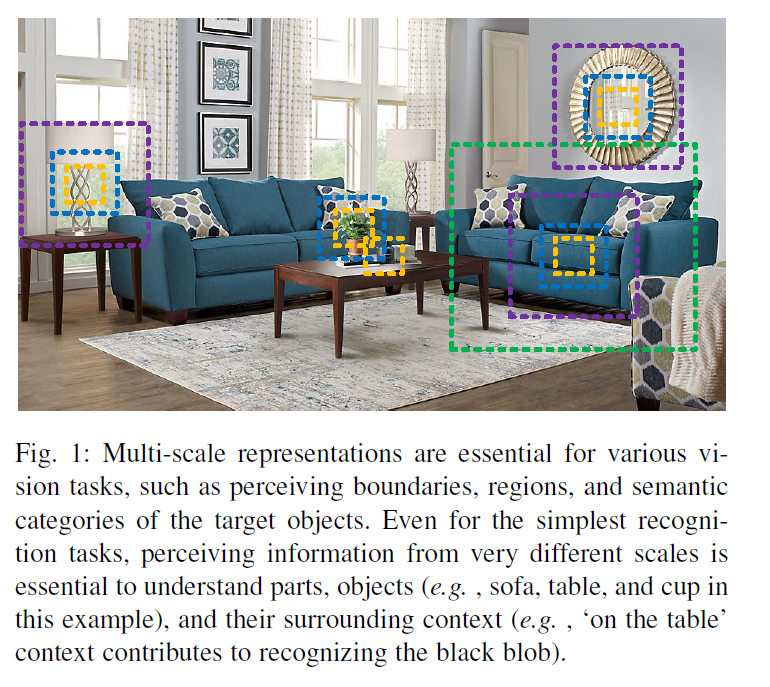
为了获得多尺寸表示能力,要求特征提取可以以较大范围的感受野来描述不同尺寸的 object/part/context。CNN通过简单的堆叠卷积操作得到coarse-to-fine的多尺寸特征。早期的工作像VGG,Alex通过简单的堆积卷积让多尺寸信息成为了可能。后来,通过组合不同大小的卷积核来获得多尺寸信息,比如Inception系列。作为backbone的CNN表现更高效,多尺寸的表征能力更强。
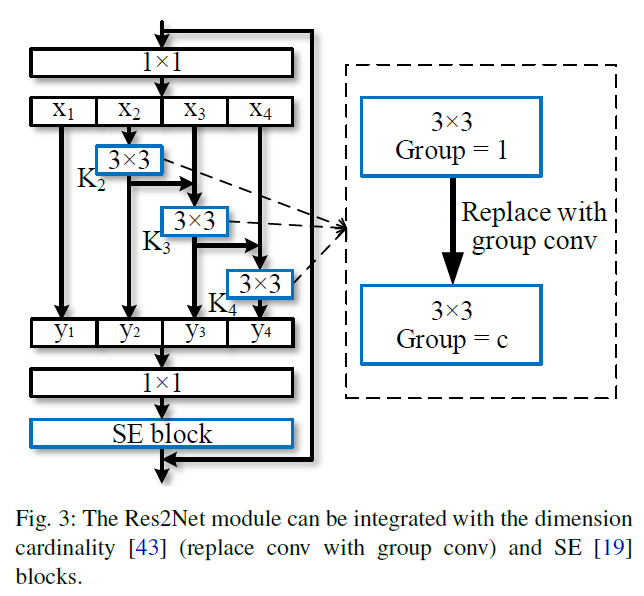
本文提出了简单高效的多尺寸模块,不同于以前的模型提高layer-wise的多尺寸表征能力,本文以更精细的水平提高模型的多尺寸表征能力。为此,本文将3x3xn的卷积核替换为3x3xw的group filters,其中,n = w x s。如下图所示,更小的filter group通过类似于残差连接的方式进行连接,从而提高输出的表示数量,首先,将输入分成几部分,一组filter从对应的一组输入feature map中提取信息。前面得到的信息送到另一组filter中作为输入。重复此操作,知道处理完所有输入feature map。最后,每组输出的feature map通过拼接操作送入1x1的卷积中用于进行特征融合。此方法引入了一个新的维度scale,用于控制group的数量。scale同height,width,cardinality相似,都为基本量,本文实验发现,通过增加scale的数量的提升效果要比其他量要好。
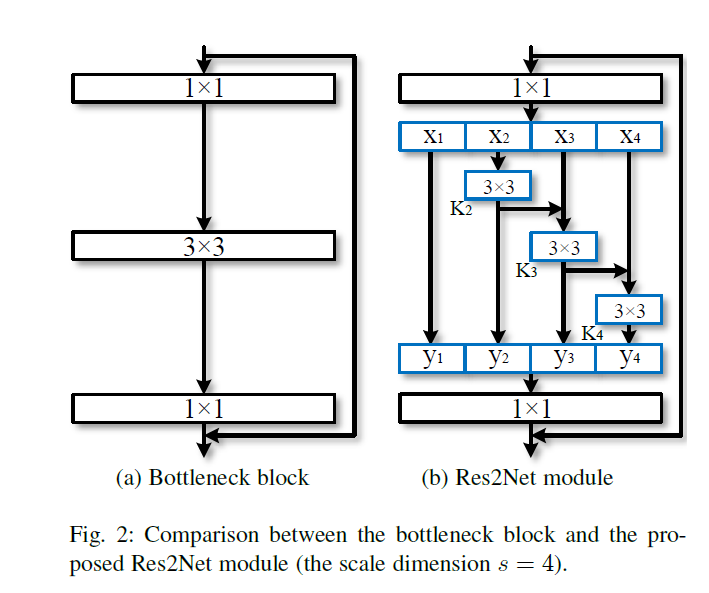
Res2Net
上图是backbone网络中比较常见的结构。本文将其中的3x3的卷积核替换为几组小的卷积核并以残差的方式进行连接,在计算力相同的条件下获得更强的多尺寸表征信息。如上图b所示,将输入feature map分为s个subset,由xi表示,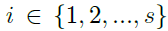 ,每个subuset的宽及高相同,但是通道数为输入feature map的1/s。除了x1,每个xi都有一个3x3的卷积核Ki,其输出由yi表示。同时,子集xi与Ki-1的输出相加并作为Ki的输入。为了忽略参数量,并提高s,x1中并不存在3x3的卷积核,因此,yi的表达式如下
,每个subuset的宽及高相同,但是通道数为输入feature map的1/s。除了x1,每个xi都有一个3x3的卷积核Ki,其输出由yi表示。同时,子集xi与Ki-1的输出相加并作为Ki的输入。为了忽略参数量,并提高s,x1中并不存在3x3的卷积核,因此,yi的表达式如下
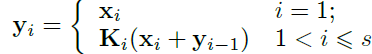
值得注意的是,每个3x3的卷积核可以接受来自该层前面的所有分离的特征 ,每次分类特征经过3x3的卷积处理后,其输出的感受野要比输入更大,由于不同的组合方式,Res2Net的输出包含不同大小及数量的感受野。在Res2Net中,Split以多尺寸的方式进行处理,有利于提取全局及局部特征。为了融合不同尺寸的信息,将输出送入到1x1的卷积中。分离拼接操作可以增强卷积的处理能力。为了减少参数量,忽略了第一个group的卷积,这也可以看作是feature map的再利用。
,每次分类特征经过3x3的卷积处理后,其输出的感受野要比输入更大,由于不同的组合方式,Res2Net的输出包含不同大小及数量的感受野。在Res2Net中,Split以多尺寸的方式进行处理,有利于提取全局及局部特征。为了融合不同尺寸的信息,将输出送入到1x1的卷积中。分离拼接操作可以增强卷积的处理能力。为了减少参数量,忽略了第一个group的卷积,这也可以看作是feature map的再利用。
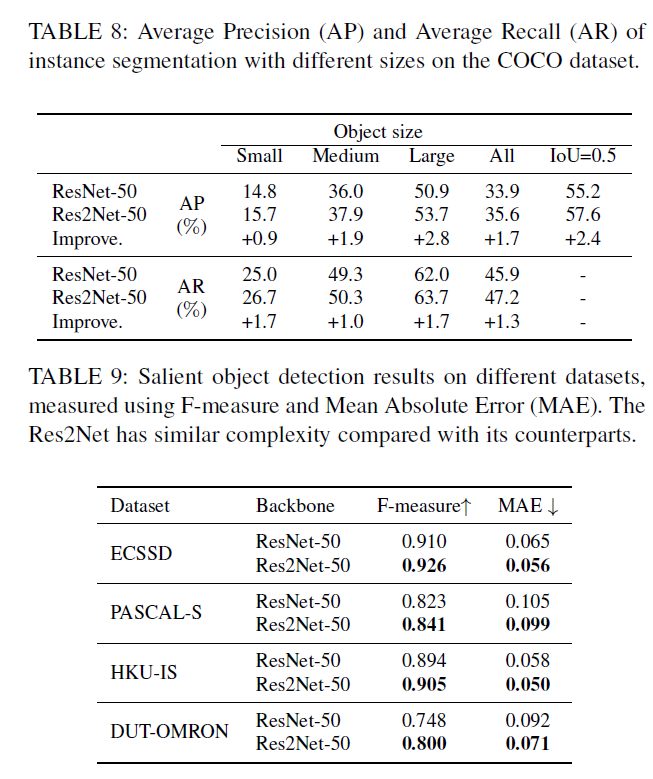
本文使用一个s作为控制尺寸维度的参数量。s越大,多尺寸表征能力更强,通过引入拼接操作,并未增加计算及内存消耗。如下图所示,Res2Net可以很方便的与现代模型进行结合。
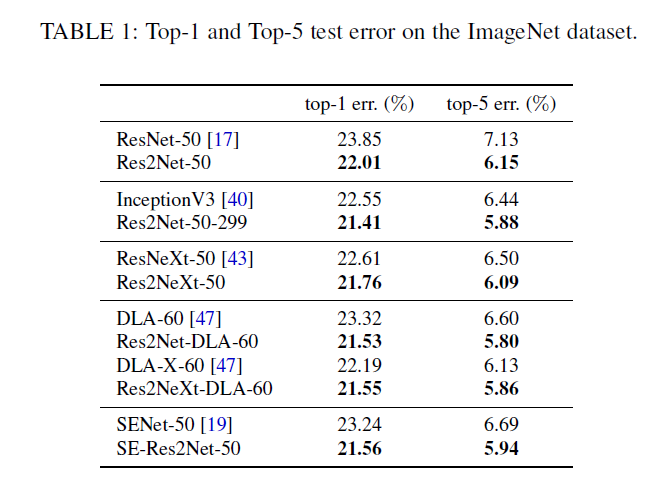
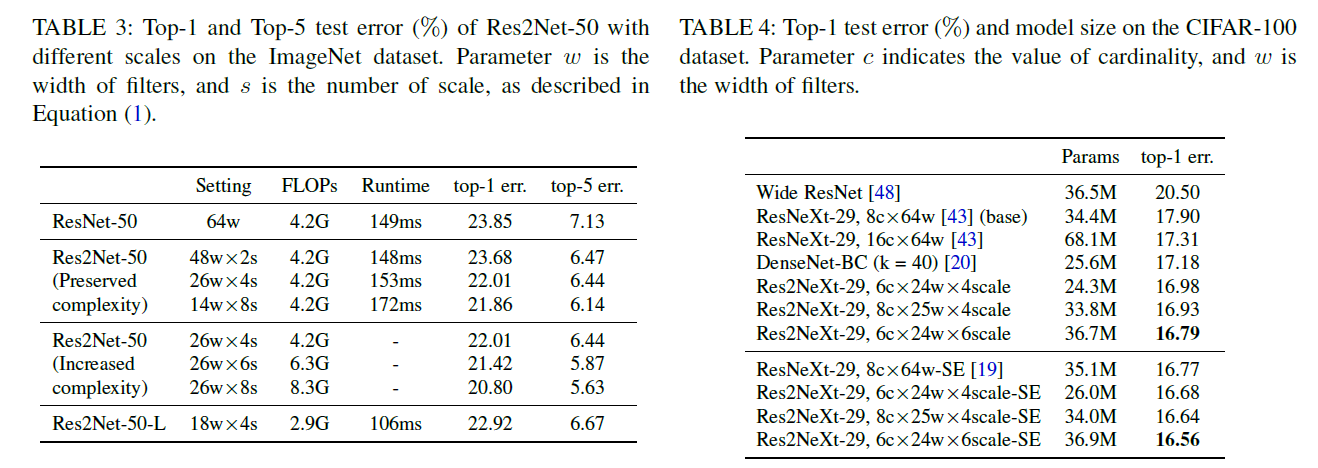
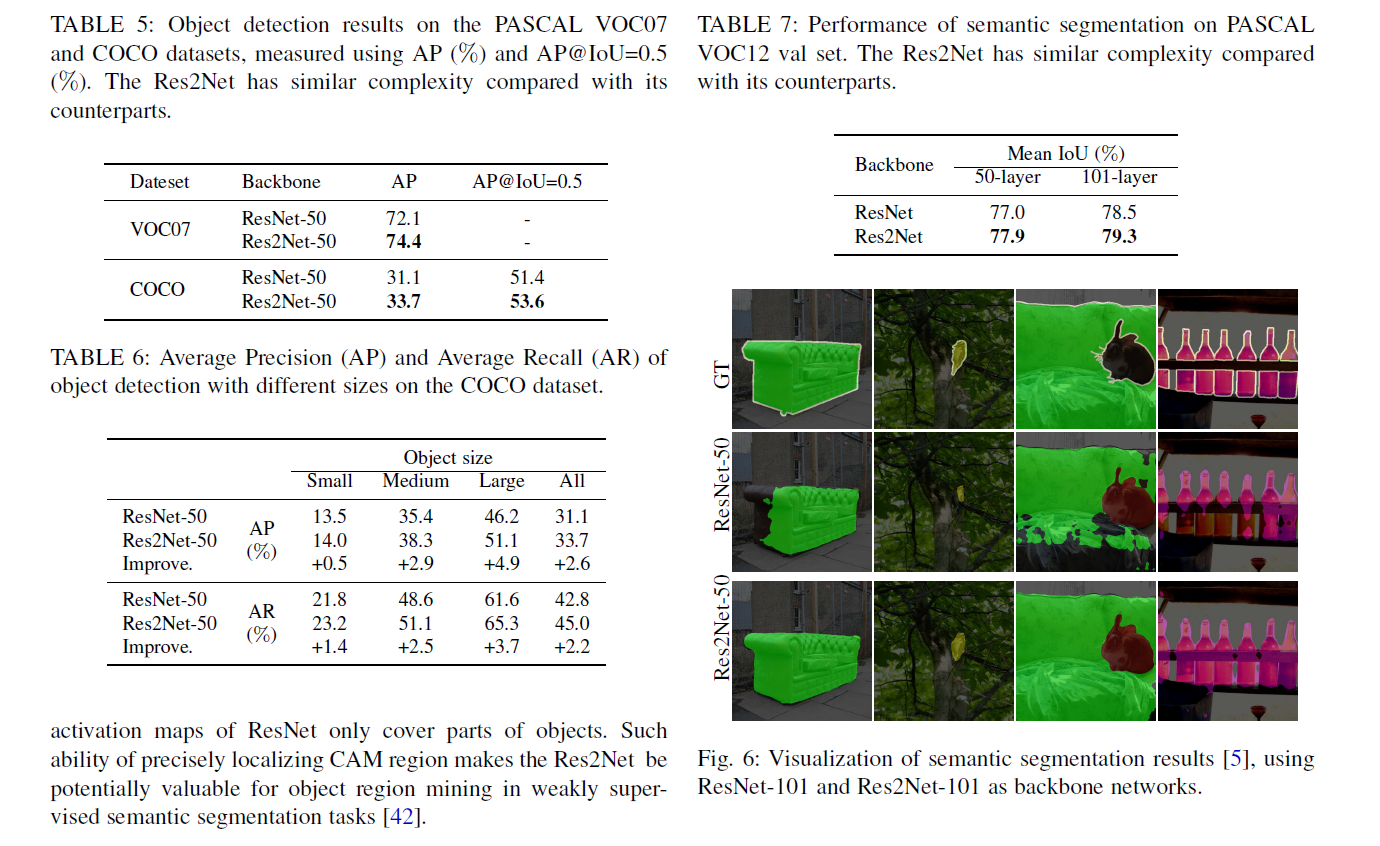
实验




Reference
[1] S. Belongie, J. Malik, and J. Puzicha. Shape matching and object recognition using shape contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(4):509–522, 2002.
[2] A. Borji, M.-M. Cheng, H. Jiang, and J. Li. Salient object detection: A benchmark. IEEE Transactions on Image Processing, 24(12):5706–5722, 2015.
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille.Deeplab: Semantic image segmentation with deep convolutional nets,atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4):834–848, 2018.
论文阅读笔记五十九:Res2Net: A New Multi-scale Backbone Architecture(CVPR2019)的更多相关文章
- 论文阅读笔记五十六:(ExtremeNet)Bottom-up Object Detection by Grouping Extreme and Center Points(CVPR2019)
论文原址:https://arxiv.org/abs/1901.08043 github: https://github.com/xingyizhou/ExtremeNet 摘要 本文利用一个关键点检 ...
- 论文阅读笔记(十九)【ITIP2017】:Super-Resolution Person Re-Identification With Semi-Coupled Low-Rank Discriminant Dictionary Learning
Introduction (1)问题描述: super resolution(SP)问题:Gallery是 high resolution(HR),Probe是 low resolution(LR). ...
- 论文阅读笔记五十五:DenseBox: Unifying Landmark Localization with End to End Object Detection(CVPR2015)
论文原址:https://arxiv.org/abs/1509.04874 github:https://github.com/CaptainEven/DenseBox 摘要 本文先提出了一个问题:如 ...
- 论文阅读笔记五十四:Gradient Harmonized Single-stage Detector(CVPR2019)
论文原址:https://arxiv.org/pdf/1811.05181.pdf github:https://github.com/libuyu/GHM_Detection 摘要 尽管单阶段的检测 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记五十:CornerNet: Detecting Objects as Paired Keypoints(ECCV2018)
论文原址:https://arxiv.org/pdf/1808.01244.pdf github:https://github.com/princeton-vl/CornerNet 摘要 本文提出了目 ...
- 论文阅读笔记四十九:ScratchDet: Training Single-Shot Object Detectors from Scratch(CVPR2019)
论文原址:https://arxiv.org/abs/1810.08425 github:https://github.com/KimSoybean/ScratchDet 摘要 当前较为流行的检测算法 ...
- 论文阅读笔记三十九:Accurate Single Stage Detector Using Recurrent Rolling Convolution(RRC CVPR2017)
论文源址:https://arxiv.org/abs/1704.05776 开源代码:https://github.com/xiaohaoChen/rrc_detection 摘要 大多数目标检测及定 ...
- 论文阅读笔记二十九:SSD: Single Shot MultiBox Detector(ECCV2016)
论文源址:https://arxiv.org/abs/1512.02325 tensorflow代码:https://github.com/balancap/SSD-Tensorflow 摘要 SSD ...
随机推荐
- bzoj4520 K远点对
题目链接 思路 这个"\(K\)远"点对一直理解成了距离第\(K\)大的点对\(233\). 要求第\(K\)远,那么我们只要想办法求出来最远的\(K\)个点对就可以了. 用一个大 ...
- SSM配置动态数据源
多数据源配置主要涉及自定义类(DataSource注解类.DataSourceAspect切面类,动态数据源接口实现类.以及数据源字符串线程保存类),pom.xml文件.applicationCont ...
- 当usbnet打印 kevent * may have been dropped(转)
http://patchwork.ozlabs.org/patch/815639/ Every once in a while when my system is under a bit of str ...
- 1+x 证书 Web 前端开发 MySQL 知识点梳理
官方QQ群 1+x 证书 Web 前端开发 MySQL 知识点梳理 http://blog.zh66.club/index.php/archives/199/
- select下拉框option的样式修改
select原样式: 进行样式修改后的样式: 附上修改代码: //select外面必须包裹一个div,用来覆盖select原有的样式<div class="option"&g ...
- git使用cherry-pick和revert抢救错误代码提交
大多数的新手在新接触git时都会出现这样的问题.代码写完了,提交到dev分支进行测试.一高兴忘记切回来,继续在dev分支开发,写完之后提交时猛的发现,我靠,我怎么在dev上面写代码,此时内心必然是一阵 ...
- vuex 源码分析(六) 辅助函数 详解
对于state.getter.mutation.action来说,如果每次使用的时候都用this.$store.state.this.$store.getter等引用,会比较麻烦,代码也重复和冗余,我 ...
- Vue.js 源码分析(二十二) 指令篇 v-model指令详解
Vue.js提供了v-model指令用于双向数据绑定,比如在输入框上使用时,输入的内容会事实映射到绑定的数据上,绑定的数据又可以显示在页面里,数据显示的过程是自动完成的. v-model本质上不过是语 ...
- redis之通信协议
Redis 协议将传输的结构数据分为 5 种最小单元类型,单元结束时统一加上回车换行符号\r\n. 1.单行字符串 以 + 符号开头. 2.多行字符串 以 $ 符号开头,后跟字符串长度. 3.整数值 ...
- 使用 jQuery.TypeAhead 让文本框自动完成 (二)(访问远程数据)
项目地址:https://github.com/twitter/typeahead.js 直接贴代码了: @section headSection { <script type="te ...