Python 正则表达式中级

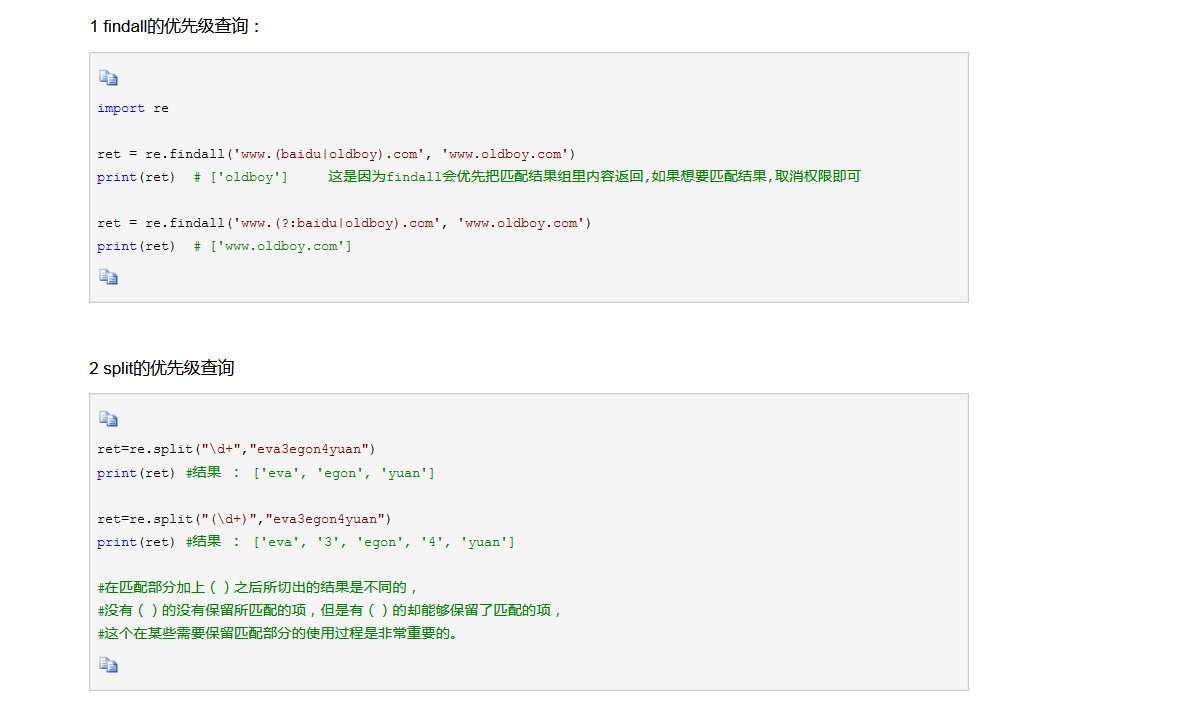
首先是?: 在括号中用?:用在findall和split之中,去除括号优先级。
如果不用只输出括号内匹配的值

r 的作用是转义python里面换行符等,像是\n 不用加\来转义
1.子表达式
子表达式的概念特别好理解。其实它就是将几个字符的组合形式看做一个大的“字符”。不好理解?举个栗子:我们要匹配类似IP地址这种形式的字符(暂且不考虑数值范围的合理性,这个留作学完之后的思考题吧)。形如192.168.1.1这样的地址我们怎么写表达式呢?
答案一 \d+.?\d+.?\d+.?\d+不好,一个是太繁琐,另一个是连位数都控制不了
答案二 \d+{1,3}.?\d+{1,3}.?\d+{1,3}.?\d+{1,3}一般般,复杂但是起码能把位数控制在合理范围
答案三 (\d+{1,3}\.){3}\d+{1,3}\.利用子表达式,将123.这种数字加小数点看做一个整体字符,对其规定重复匹配的次数,既简洁,效果又好。所以只要你将几个字符组合用圆括号括起来,那么你就可以把一个圆括号内的内容当做一个字符,外面可以加我们之前讲过的所有元字符来控制匹配。
2.向前向后查找
现在,我们终于来到了向前向后查找这一块。为什么说终于来到这了呢?还记得我们在初级篇最开始的例子吗?
假如你在写一个爬虫,你得到了一个网页的HTML源码。其中有一段html
<html><body><h1>hello world</h1></body></html>
你想要把这个hello world提取出来
import re
key = r"<html><body><h1>hello world</h1></body></html>"#这段是你要匹配的文本
p1 = r"(?<=<h1>).+?(?=</h1>)"#这是我们写的正则表达式规则,你现在可以不理解啥意思
pattern1 = re.compile(p1)#我们在编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print matcher1.group(0)#打印出来这个正则表达式
p1 = r"(?<=<h1>).+?(?=<h1>)"看到(?<=<h1>) 和 (?=<h1>)了吗?第一个?<=表示在被匹配字符前必须得有<h1>,后面的?=表示被匹配字符后必须有<h1>
简单来说,就是你要匹配的字符是XX,但必须满足形式是AXXB这样的字符串,那么你就可以这样写正则表达式
p = r"(?<=A)XX(?=B)"匹配到的字符串就是XX。并且,向前查找向后查找不需要必须同时出现。如果你愿意,可以只写满足一个条件。
所以你也不需要记住哪个是向前查找,哪个是向后查找。只要记住?<=后面跟着的是前缀要求,?=后面跟的是后缀要求。
本质上来说,向前查找和向后查找其实是匹配整个字符串,即AXXB,但返回时仅仅返回一个XX。也就是说,如果你愿意,完全可以避开向前向后查找的方式,直接匹配带有前后缀的字符串,然后做字符串切片处理。
3.回溯引用
不同于前面的向前向后查找,这一条有时候你未必绕的过去。在有些情况下,你还必须得用到回溯引用,所以你如果想拥有在实际应用中使用正则表达式,回溯引用是你应该了解和掌握的。
我们还是从最开始的例子来说。
你原本要匹配<h1></h1>之间的内容,现在你知道HTML有多级标题,你想把每一级的标题内容都提取出来。你也许会这样写:
p = r"<h[1-6]>.*?</h[1-6]>"这样一来,你就可以将HTML页面内所有的标题内容全部匹配出来。即<h1></h1>到<h6></h6>的内容都可以被提取出来。但是我们之前说过,写正则表达式困难的不是匹配到想要的内容,而是尽可能的不匹配到不想要的内容。在这个例子中,很有可能你就会被下面这样的用例玩坏。
比方说
<h1>hello world</h3>发现后面的</h3>了吗?我们不管是怎么写出来这样的标题的,但实实在在的是我们的正则表达式同样会把这里面的hello world匹配出来。这时候就是回溯引用的重要作用。下面就是一个示例:
import re
key = r"<h1>hello world</h3>"
p1 = r"<h([1-6])>.*?</h\1>"
pattern1 = re.compile(p1)
m1 = re.search(pattern1,key)
print m1.group(0)#这里是会报错的,因为匹配不到,你如果将源字符串改成</h1>
结尾就能看出效果看到\1了吗?原本那个位置应该是[1-6],但是我们写的是\1,我们之前说过,转义符\干的活就是把特殊的字符转成一般的字符,把一般的字符转成特殊字符。普普通通的数字1被转移成什么了呢?在这里1表示第一个子表达式,也就是说,它是动态的,是随着前面第一个子表达式的匹配到的东西而变化的。比方说前面的子表达式内是[1-6],在实际字符串中找到了1,那么后面的\1就是1,如果前面的子表达式在实际字符串中找到了2,那么后面的\1就是2。
类似的,\2,\3,....就代表第二个第三个子表达式。
所以回溯引用是正则表达式内的一个“动态”的正则表达式,让你根据实际的情况变化进行匹配。
中级篇就到这里,其实正则表达式还有很多细节还没有写出来,也有很多元字符我没有交代,但掌握了纲要,懂得原理之后剩下的就类似于查表构造这种活了。
建议看到这的朋友看看《正则表达式必知必会》,初级篇和这篇中有几个例子也是取材于此。
python group()
正则表达式中,group()用来提出分组截获的字符串,()用来分组

import re
a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
究其因
1. 正则表达式中的三组括号把匹配结果分成三组
- group() 同group(0)就是匹配正则表达式整体结果
- group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
2. 没有匹配成功的,re.search()返回None
3. 当然郑则表达式中没有括号,group(1)肯定不对了。
Python 正则表达式中级的更多相关文章
- python 正则表达式 中级
1.子表达式 将几个字符的组合形式看做一个大的字符,例如匹配IP地址,形如 127.0.0.1 答案一:p1='\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}' pattern1 ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- 转载 Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- Python 正则表达式入门(初级篇)
Python 正则表达式入门(初级篇) 本文主要为没有使用正则表达式经验的新手入门所写. 转载请写明出处 引子 首先说 正则表达式是什么? 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达 ...
- python正则表达式入门篇
文章来源于:https://www.cnblogs.com/chuxiuhong/p/5885073.html Python 正则表达式入门(初级篇) 本文主要为没有使用正则表达式经验的新手入门所写. ...
- Python正则表达式中的re.S
title: Python正则表达式中的re.S date: 2014-12-21 09:55:54 categories: [Python] tags: [正则表达式,python] --- 在Py ...
- python正则表达式re
Python正则表达式: re 正则表达式的元字符有. ^ $ * ? { [ ] | ( ).表示任意字符[]用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字符集,对于字符集中的字符可 ...
- Python正则表达式详解
我用双手成就你的梦想 python正则表达式 ^ 匹配开始 $ 匹配行尾 . 匹配出换行符以外的任何单个字符,使用-m选项允许其匹配换行符也是如此 [...] 匹配括号内任何当个字符(也有或的意思) ...
- 比较详细Python正则表达式操作指南(re使用)
比较详细Python正则表达式操作指南(re使用) Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式.Python 1.5之前版本则是通过 regex 模块提供 E ...
随机推荐
- ① 设计模式的艺术-07.适配器(Adapter)模式
什么是适配器模式? 将一个类的接口转换成客户希望的另外一个接口.Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作. 模式中的角色 目标接口(Target):客户所期待的接口 ...
- 【BZOJ】1798: [Ahoi2009]Seq 维护序列seq 线段树多标记(区间加+区间乘)
[题意]给定序列,支持区间加和区间乘,查询区间和取模.n<=10^5. [算法]线段树 [题解]线段树多重标记要考虑标记与标记之间的相互影响. 对于sum*b+a,+c直接加上即可. *c后就是 ...
- [POI 2008&洛谷P3467]PLA-Postering 题解(单调栈)
[POI 2008&洛谷P3467]PLA-Postering Description Byteburg市东边的建筑都是以旧结构形式建造的:建筑互相紧挨着,之间没有空间.它们共同形成了一条长长 ...
- HttpUtility.UrlEncode与Server.UrlEncode()转码区别
在对URL进行编码时,该用哪一个?这两都使用上有什么区别吗?测试: string file="文件上(传)篇.doc";string Server_UrlEncode=Server ...
- SMB MS17-010 利用(CVE-2017-0144 )
exploit-db : https://www.exploit-db.com/exploits/42315/ 该漏洞的影响版本很广泛:Microsoft Windows Windows 7/8.1/ ...
- Supply
Supplier创建一个Supply Supply有tap或emit方法. 可以这样理解: Supplier创建一个工厂 Supply 用tap创建流水线 emit向流水线上传送加工品进行加厂 my ...
- 使用ctypes在Python中调用C++动态库
使用ctypes在Python中调用C++动态库 入门操作 使用ctypes库可以直接调用C语言编写的动态库,而如果是调用C++编写的动态库,需要使用extern关键字对动态库的函数进行声明: #in ...
- (转)USB的描述符及各种描述符之间的依赖关系
全文链接:http://justmei.blog.163.com/blog/static/11609985320102421659260/?latestBlog 1 推荐 [原创] USB入门系列之七 ...
- B2旅游签证记
先去https://ceac.state.gov/ceac/,选择DS-160表格,在线申请登记个人信息 ,选择大事馆“CHINA BEIJING”和验证码,点 Start an Applicatio ...
- ireport报表制作, 通过节点、产品类型来判断,当该节点审核通过之后,报表相对应的审核意见及签名 显示相对应的内容
1.代码① (与本内容相关的代码:7~36) 以下类似 $P{P_XXXX} :均为页面端的传入参数 select so.sale_order_no as sale_order_ ...