SQL Server WITH ROLLUP、WITH CUBE、GROUPING语句的应用
CUBE:CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
GROUPING:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
先创建一个临时表:
create table #temp
(
姓名 varchar(50) not null,
课程 varchar(50) null,
分数 int null
) insert into #temp
select '小红','SQL','' union
select '小红','C#','' union
select '小明','SQL','' union
select '小明','C#','' union
select '小李','SQL','' union
select '小李','C#',null select * from #temp

WITH CUBE:
select 姓名,课程,sum(分数)
from #temp
group by 姓名,课程
with cube
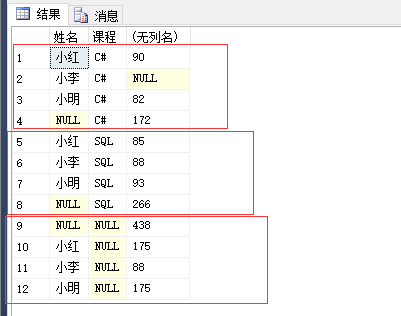
先以姓名分组和课程组合,再以姓名和课程分组进行组合。
PS:分类依据并不是根据select 中的顺序,而是根据group by中的顺序。
下面换个顺序看看结果:
select 姓名,课程,sum(分数)
from #temp
group by 课程,姓名
with cube

先以课程分组和姓名组合,再以课程和姓名分组进行组合。
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
WITH ROLLUP:
select 姓名,课程,sum(分数)
from #temp
group by 姓名,课程
with rollup
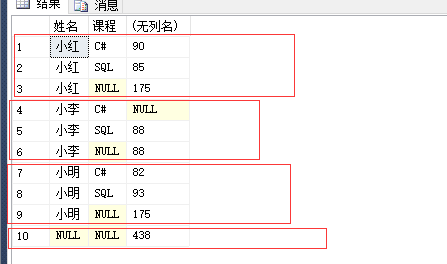
select 姓名,课程,sum(分数)
from #temp
group by 课程,姓名
with rollup
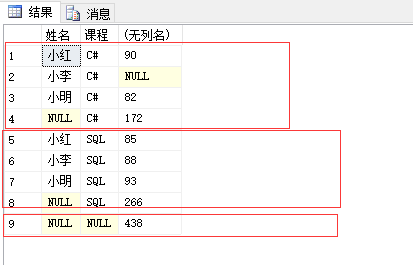
ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
那么这个某一层次结构是什么呢?看一下上面的数据,当以姓名先分组时,分成了三组(不计最后一行合计),当以课程先分组时,分成了两组(不计最后一行合计)。
这个某一层次结构我猜想应该跟 group by 的分组顺序有关。
GROUPING:
grouping 与 with rollup 的结合(与with cube的结合是一样的)
select 姓名,课程,sum(分数),GROUPING(姓名)
from #temp
group by 姓名,课程
with rollup
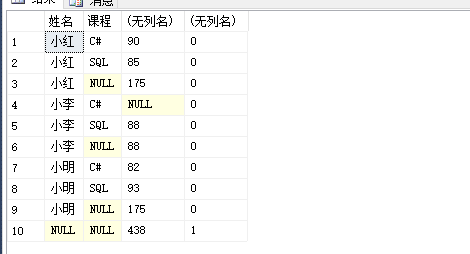
当 grouping 指定列为【姓名】时,只有最后一行是 with rollup 所添加的。
select 姓名,课程,sum(分数),GROUPING(课程)
from #temp
group by 姓名,课程
with rollup

当 grouping 指定列为【课程】时,第三行、第六行、第九行和最后一行是 with rollup 所添加的。
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
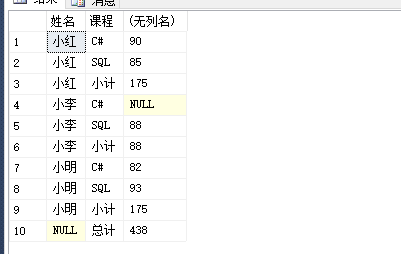
select 姓名,
case when GROUPING(姓名)=1
then '总计'
else
case when GROUPING(课程)=1
then '小计'
else 课程 end
end 课程,
sum(分数)
from #temp
group by 姓名,课程
with rollup
SQL Server WITH ROLLUP、WITH CUBE、GROUPING语句的应用的更多相关文章
- SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff CREATE TABLE [dbo].[Staff]( ,) NOT NULL, ) NULL, ) NULL, ) NULL, [Money] [int] NULL, [Cr ...
- SQL SERVER全面优化-------写出好语句是习惯
前几篇文章已经从整体提供了诊断数据库的各个方面问题的基本思路...也许对你很有用,也许你觉得离自己太远.那么今天我们从语句的一些优化写法及一些简单优化方法做一个介绍.这对于很多开发人员来说还是很有用的 ...
- SQL Server(三):Select语句
1.最基本的Select语句: Select [Top n [With Ties]] <*|Column_Name [As <Alias>][, ...n]> From & ...
- SQL Server 查询、搜索命令、语句
--查询所有表 SELECT NAME,* FROM SYSOBJECTS WHERE XTYPE='U' order by SYSOBJECTS.name --查询所有存储过程 select * f ...
- SQL Server 找出值得优化的语句
方法 1. sys.dm_exec_qurey_stats 返回 SQL Server 中缓存查询计划的聚合性能统计信息. 缓存计划中的每个查询语句在该视图中对应一行, 并且行的生存期与计划本身相关联 ...
- 不同数据库oracle mysql SQL Server DB2 infomix sybase分页查询语句
在不同数据库中的使用的分页查询语句: 当前页:currentpage 页大小:pagesize 1. Oracle数据库 select * from (select A.*,rownum rn fro ...
- 如何在SQL Server 2008下轻松调试T-SQL语句和存储过程
一.回顾早期的SQL SERVER版本:早在SQL Server 2000时代,查询分析器的功能还很简陋,远不如VS那么强大.到SQL Server 2005时代,代码高亮.SQL优化等功能逐渐加强, ...
- 从零开始学习SQL SERVER(2)--- 基本操作及语句
声明:仅为本人随笔及经验之谈,有错误敬请指出. # 后的文字为注释 Microsoft SQL Server Management Studio 中的SQL命令 添加数据库 1 CREATE DATA ...
- sql server抓取表结构的语句
sql server 2008抓取方法: --------------------------------------- SELECT 表名 = Case When A.colorder ...
随机推荐
- sdut 2154:Shopping(第一届山东省省赛原题,水题)
Shopping Time Limit: 1000MS Memory limit: 65536K 题目描述 Saya and Kudo go shopping together.You can ass ...
- Huber-Markov先验模型相关
随机概率重建-MAP算法 随机概率重建:利用贝叶斯理论作为框架,理想图像的先验知识作为约束条件进行图像重建.常用的随机概率超分辨率重建包括最大后验概率估计法(MAP)和极大似然估计法(ML). MAP ...
- ifcfg-<interface-name> 文件配置详解
TYPE=Ethernet #网卡类型DEVICE=<name> <name>表示物理设备的名字I ...
- VC中的学习点滴
1. __stdcall 和 __cdecl __cdecl 是C Declaration的缩写(declaration,声明),表示C语言默认的函数调用方法:所有参数从右到左依次入栈,由调用者负责 ...
- Thinkphp中如何书写按照指定字段同步更新的ORM
群友提出一个问题,如何在更新某个字段的时候同步另一个字段数据过来,即 update table set column1 =column2 where xxx 写原生SQL当然可行,不过既然有ORM那就 ...
- iOS开发之--svn工具Cornerstone上传忽略.a文件的处理方法
工程文件上传到svn中,.a文件会自动屏蔽(应该叫屏蔽,反正就是上传不上去) 用Cornerstone工具,解决这个问题 1.打开Cornerstone左上角,点Cornerstone->Pre ...
- onTouch事件分发
事件机制 我们知道view中有onTouch,onClick, 1.并且onTouch优先于onClick执行, 2.onTouch有返回值,为true时onClick并不再执行了 因为一切VIew都 ...
- poj_2479 动态规划
题目大意 给定一列数,从中选择两个不相交的连续子段,求这两个连续子段和的最大值. 题目分析 典型的M子段和的问题,使用动态规划的方法来解决. f[i][j] 表示将A[1...i] 划分为j个不相交连 ...
- TClientDataSet数据源设置
TClientDataSet数据源设置 TClientDataSet数据源设置
- zookeeper未授权访问漏洞
1.什么是zookeeper? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交 ...