(七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型
当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的:
1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
2)画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
3)人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
评估模型
首先,引入一个概念,非对称性分类。考虑癌症预测问题,y=1 代表癌症,y=0 代表没有癌症,对于一个数据集,我们建立logistic 回归模型,经过以上建模的步骤,得到一个优化的模型,错误率仅为1%,这貌似是一个很好的结果,但考虑数据集若仅有0.05%的正例(y=1),那么我们直接预测所有y=0,我们得到的模型的错误率仅为0.5%,这便是非对称分类的问题,这样的问题仅考虑错误率是有风险的。
下面引入一种标准的衡量方法:Precision/Recall(精确度和召回率),这种度量最早出现在信息检索问题中的,如下:
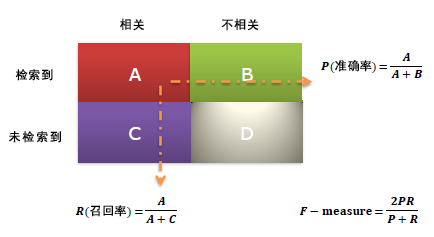
在机器学习的模型中,也可以用这种评估方法,具体如下:

其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
现在需要考虑权衡Precision/Recall:
以logistic 回归为例:
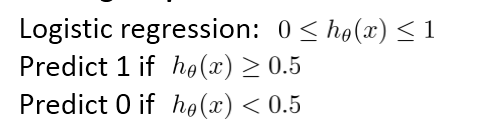
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,FP变小,FN增大,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,FP变大,FN变小,这又会导致高召回率,低精确度(Higher recall, lower precision);

以上的描述可以用如下的PR曲线来描述,一般准确率提高,召回率会下降:
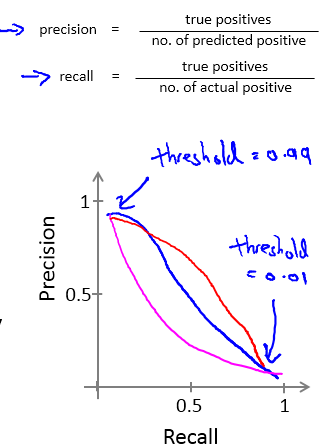
关于如何权衡准确率与召回率:
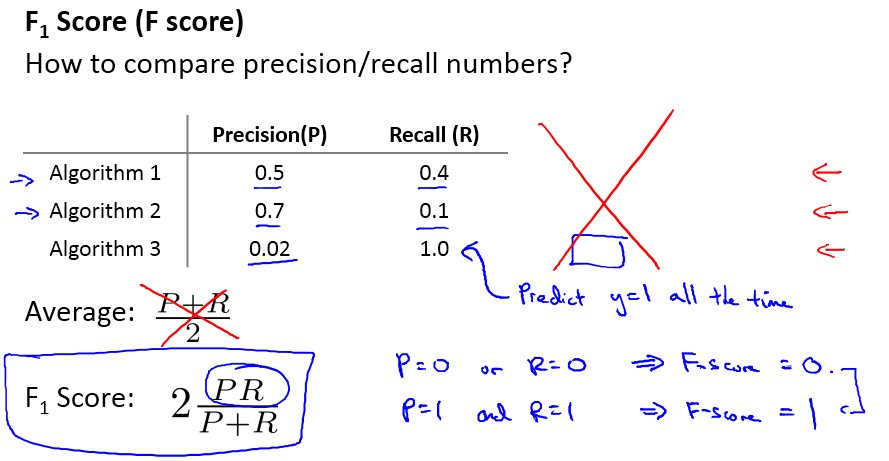
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F1来衡量。
(七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值的更多相关文章
- CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型 当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的: 1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试: 2)画学习曲线以决定是否更多 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- Stanford机器学习---第六讲. 怎样选择机器学习方法、系统
原文:http://blog.csdn.net/abcjennifer/article/details/7797502 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Android群英传》读书笔记 (3) 第六章 Android绘图机制与处理技巧 + 第七章 Android动画机制与使用技巧
第六章 Android绘图机制与处理技巧 1.屏幕尺寸信息屏幕大小:屏幕对角线长度,单位“寸”:分辨率:手机屏幕像素点个数,例如720x1280分辨率:PPI(Pixels Per Inch):即DP ...
- 关于”机器学习方法“,"深度学习方法"系列
"机器学习/深度学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是让很多其它的人了解机器学习的概念,理解其原理,学会应用.如今网上各种技术类文章非常 ...
- R语言进行机器学习方法及实例(一)
版权声明:本文为博主原创文章,转载请注明出处 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有 ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 基于CRF工具的机器学习方法命名实体识别的过
[转自百度文库] 基于CRF工具的机器学习方法命名实体识别的过程 | 浏览:226 | 更新:2014-04-11 09:32 这里只讲基本过程,不涉及具体实现,我也是初学者,想给其他初学者一些帮助, ...
随机推荐
- 单选项框RadioGroup的综合应用
大家好,我们今天这一节要介绍的是RadioGroup 的组事件.RadioGroup 可将各自不同的RadioButton ,设限于同一个Radio 按钮组,同一个RadioGroup 组里的按钮,只 ...
- Android调用天气预报的WebService简单例子
下面例子改自网上例子:http://express.ruanko.com/ruanko-express_34/technologyexchange5.html 不过网上这个例子有些没有说明,有些情况不 ...
- HBase保存的各个字段意义解释
/×××××××××××××××××××××××××××××××××××××××××/ Author:xxx0624 HomePage:http://www.cnblogs.com/xxx0624/ ...
- Lucene基于IKAnalyzer配置的词典扩充
在web项目的src目录下创建IKAnalyzer.cfg.xml文件,内容如下 <?xml version="1.0" encoding="UTF-8" ...
- 离开csdn来到blog园
csdn里没有限制阅读访问的功能,所以我选择来到cnblog 但是不得不说,cnblog做的界面很丑,我个人很不喜欢,但是没办法
- Linux客户/服务器程序设计范式2——并发服务器(进程池)
引言 让服务器在启动阶段调用fork创建一个子进程池,通过子进程来处理客户端请求.子进程与父进程之间使用socketpair进行通信(为了方便使用sendmsg与recvmsg,如果使用匿名管道,则无 ...
- 开始使用Mac OS X——写给Mac新人
本文转自博客园:http://www.cnblogs.com/chijianqiang/archive/2011/08/03/2126593.html 写这篇文档的原因有两个,一.身边使用Mac的朋友 ...
- hadoop 2.0 native
1.安装protobuf,参照http://wiki.apache.org/hadoop/HowToContribute 安装java模块 在java目录mvn install 2.配置protobu ...
- 李洪强iOS面试总结之- FMDB
n什么是FMDB pFMDB是iOS平台的SQLite数据库框架 pFMDB以OC的方式封装了SQLite的C语言API p nFMDB的优点 p使用起来更加面向对象,省去了很多麻烦.冗余的C语言代码 ...
- 两个奇葩的C/C++问题
今天为大家介绍几个奇葩的C/C++问题. 1 大家看看下面的输出结果是什么呢? #include <stdio.h> #include <stdlib.h> void ma ...