Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较
DisCrete Versus Real AdaBoost
关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4581651.html
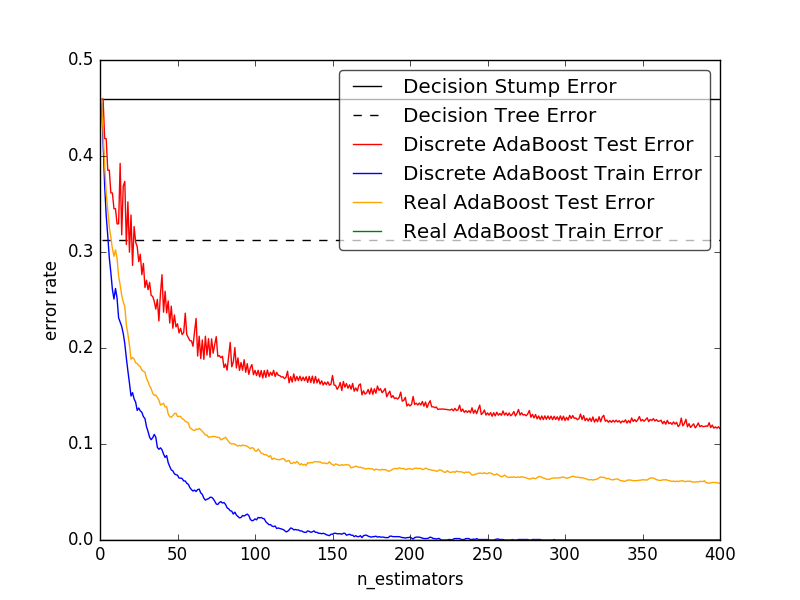
本例是Sklearn网站上的关于决策树桩、决策树、和分别使用AdaBoost—SAMME和AdaBoost—SAMME.R的AdaBoost算法在分类上的错误率。这个例子基于Sklearn.datasets里面的make_Hastie_10_2数据库。取了12000个数据,其他前2000个作为训练集,后面10000个作为了测试集。
原网站链接:here
代码如下:
#- *- encoding:utf-8 -*-
"""
Sklearn adaBoost @Dylan
2016/9/1
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import zero_one_loss
from sklearn.ensemble import AdaBoostClassifier
import time
a=time.time() n_estimators=400
learning_rate=1
X,y=datasets.make_hastie_10_2(n_samples=12000,random_state=1)
X_test,y_test=X[2000:],y[2000:]
X_train,y_train=X[:2000],y[:2000] dt_stump=DecisionTreeClassifier(max_depth=1,min_samples_leaf=1)
dt_stump.fit(X_train,y_train)
dt_stump_err=1.0-dt_stump.score(X_test,y_test) dt=DecisionTreeClassifier(max_depth=9,min_samples_leaf=1)
dt.fit(X_train,y_train)
dt_err=1.0-dt.score(X_test,y_test) ada_discrete=AdaBoostClassifier(base_estimator=dt_stump,learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME')
ada_discrete.fit(X_train,y_train) ada_real=AdaBoostClassifier(base_estimator=dt_stump,learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME.R')
ada_real.fit(X_train,y_train) fig=plt.figure()
ax=fig.add_subplot(111)
ax.plot([1,n_estimators],[dt_stump_err]*2,'k-',label='Decision Stump Error')
ax.plot([1,n_estimators],[dt_err]*2,'k--',label='Decision Tree Error') ada_discrete_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_test)):
ada_discrete_err[i]=zero_one_loss(y_pred,y_test) ######zero_one_loss
ada_discrete_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train) ada_real_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_test)):
ada_real_err[i]=zero_one_loss(y_pred,y_test)
ada_real_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train) ax.plot(np.arange(n_estimators)+1,ada_discrete_err,label='Discrete AdaBoost Test Error',color='red')
ax.plot(np.arange(n_estimators)+1,ada_discrete_err_train,label='Discrete AdaBoost Train Error',color='blue')
ax.plot(np.arange(n_estimators)+1,ada_real_err,label='Real AdaBoost Test Error',color='orange')
ax.plot(np.arange(n_estimators)+1,ada_real_err_train,label='Real AdaBoost Train Error',color='green') ax.set_ylim((0.0,0.5))
ax.set_xlabel('n_estimators')
ax.set_ylabel('error rate') leg=ax.legend(loc='upper right',fancybox=True)
leg.get_frame().set_alpha(0.7)
b=time.time()
print('total running time of this example is :',b-a)
plt.show()
输出结果
1.运行时间:
total running time of this example is : 6.1493518352508545
2.对比图:
Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较的更多相关文章
- 机器学习技法之Aggregation方法总结:Blending、Learning(Bagging、AdaBoost、Decision Tree)及其aggregation of aggregation
本文主要基于台大林轩田老师的机器学习技法课程中关于使用融合(aggregation)方法获得更好性能的g的一个总结.包含从静态的融合方法blending(已经有了一堆的g,通过uniform:voti ...
- Sklearn库例子——决策树分类
Sklearn上关于决策树算法使用的介绍:http://scikit-learn.org/stable/modules/tree.html 1.关于决策树:决策树是一个非参数的监督式学习方法,主要用于 ...
- python常用库 - NumPy 和 sklearn入门
Numpy 和 scikit-learn 都是python常用的第三方库.numpy库可以用来存储和处理大型矩阵,并且在一定程度上弥补了python在运算效率上的不足,正是因为numpy的存在使得py ...
- Lua 中的string库(字符串函数库)总结
(字符串函数库)总结 投稿:junjie 字体:[增加 减小] 类型:转载 时间:2014-11-20我要评论 这篇文章主要介绍了Lua中的string库(字符串函数库)总结,本文讲解了string库 ...
- iOS开发中静态库之".framework静态库"的制作及使用篇
iOS开发中静态库之".framework静态库"的制作及使用篇 .framework静态库支持OC和swift .a静态库如何制作可参照上一篇: iOS开发中静态库之" ...
- Tools下的mdscongiguer 文件中 43行 oracle 配置 发现需要连接库 -lclntsh libclntsh.so 库是个什么东西呢?
Tools下的mdscongiguer 文件中 43行 oracle 配置 发现需要连接库 -lclntsh libclntsh.so 库是个什么东西呢? 分想一个知乎网 ...
- 在Linux中创建静态库.a和动态库.so
转自:http://www.cnblogs.com/laojie4321/archive/2012/03/28/2421056.html 在Linux中创建静态库.a和动态库.so 我们通常把一些公用 ...
- prop-types:该第三方库对组件的props中的变量进行类型检测
利用prop-types第三方库对组件的props中的变量进行类型检测
- maven2中snapshot快照库和release发布库的应用
在之前的文章中介绍了maven2中snapshot快照库和release发布库的区别和作用,我今天这里要介绍的是如何在项目中应用snapshot和release库,应用snapshot和release ...
随机推荐
- 2016 - 1- 14 UI阶段学习补充 transform属性详解
UIView的transform属性 transform是view的一个重要属性,它在矩阵层面上改变view的显⽰状态,能实现view的缩放.旋转.平移等功能.transform是CGAffineTr ...
- 2016-1-10 手势解锁demo的实现
一:实现自定义view,在.h,.m文件中代码如下: #import <UIKit/UIKit.h> @class ZLLockView; @protocol ZLLockViewDele ...
- UIkit框架之UIbutton的使用
1.UIbutton的继承关系:UIcontroller:UIview:UIresponder:NSObject: 2.添加按钮的步骤: (1)创建按钮的时候首先设置类型 (2)添加标题或者图片,设置 ...
- device framework(设备框架)
Table A-1 Device frameworks Name First available Prefixes Description Accelerate.framework 4.0 cbla ...
- Android Toast效果
Android Toast效果是一种提醒方式,在程序中使用一些短小的信息通知用户,过一会儿会自动消失,实现如下: FirstActivity.java package org.elvalad.acti ...
- (工作经验总结一二)队列--多个main的原因
1,项目创建最好有一个自己的继承于UIViewController的类,并且其他控制器继承这个控制器,灵活性较大,例如: 要给项目每个页面添加截图或用户操作轨迹记录等,这样就省去了到每个页面添加的麻烦 ...
- 20145210实验五《Java网络编程》
20145210实验五<Java网络编程> 实验内容 1.运行下载的TCP代码,结对进行,一人服务器,一人客户端: 2.利用加解密代码包,编译运行代码,一人加密,一人解密: 3.集成代码, ...
- 12-1 上午mysql 基本语句
create table test( code varchar(20) primary key, name varchar(20)); 关键字primary key 主键非空 not nullfore ...
- 我的第一个unity3d Shader, 很简单,基本就是拷贝
Shader "Castle/ColorMix" { Properties { // 基本贴图 _MainTex ("Texture Image", 2D) = ...
- iOS-Block两个界面传值
先说一下思路: 首先,创建两个视图控制器,在第一个视图控制器中创建一个Label和一个Button,其中Label是为了显示第二个视图控制器传过来的字符串, Button是为了push到第二个界面. ...