[Spark Core] Spark 核心组件
0. 说明
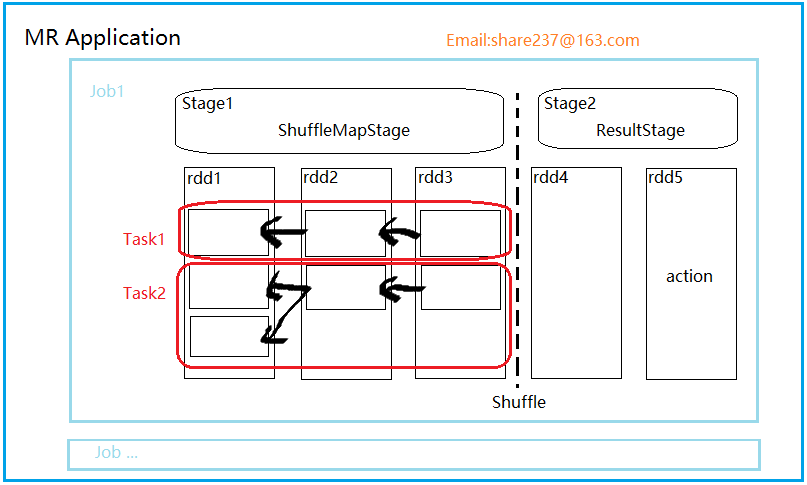
【Spark 核心组件示意图】
1. RDD
resilient distributed dataset , 弹性数据集
轻量级的数据集合,逻辑上的集合。等价于 list
没有携带数据。
2. 依赖
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
3. Stage(阶段)
并行的 task 集合,同一 Stage 的所有任务有着相同的 Shuffle 依赖。
阶段,一组RDD构成的链条。
阶段的划分按照 Shuffle 标记来进行的。
阶段类型有两种,ShuffleMapStage 和ResultStage。
【ShuffleMapStage】
该阶段任务的结果是下一个阶段任务的输入。需要跟踪每个分区所在的节点。
任务执行期间的中间过程,保存task的输出数据供下一个 reduce 进行 fetch(抓取) 。
该阶段可以单独提交。
【 ResultStage】
结果结果直接执行 RDD 的 action 操作。
对一些分区应用计算函数(不一定需要在所有分区进行计算,比如说first())。
最后一个阶段,执行task后的结果回传给driver
4. Task
task 是 Spark 执行单位,有两种类型。
【ShuffelMapTask】
在 ShuffleMapStage 由多个 ShuffleMapTask 组成。
【ResultTask】
ResultStage 由多个 ResultTask 组成,结果任务直接 task 后,将结果回传给 driver。
driver:
5. job
一个 action 就是一个 job
6. Application
一个应用可以包含多个 job
7. Spark Context
Spark 上下文是 Spark 程序的主入口点,表示到 Spark 集群的连接。可以创建 RDD 、累加器和广播变量。
每个 JVM 只能有一个 active 的上下文,如果要创建新的上下文,必须将原来的上下文 stop。
sc.textFile("");
sc.parallelize(1 to 10);
sc.makeRDD(1 to 10) ; //通过parallelize实现。
[Spark Core] Spark 核心组件的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [Spark Core] Spark Client Job 提交三级调度框架
0. 说明 官方文档 Job Scheduling Spark 调度核心组件: DagScheduler TaskScheduler BackendScheduler 1. DagSchedule ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- 【待补充】[Spark Core] Spark 实现标签生成
0. 说明 在 IDEA 中编写 Spark 代码实现将 JSON 数据转换成标签,分别用 Scala & Java 两种代码实现. 1. 准备 1.1 pom.xml <depend ...
- [Spark Core] Spark 在 IDEA 下编程
0. 说明 Spark 在 IDEA 下使用 Scala & Spark 在 IDEA 下使用 Java 编写 WordCount 程序 1. 准备 在项目中新建模块,为模块添加 Maven ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- [Spark Core] Spark Shell 实现 Word Count
0. 说明 在 Spark Shell 实现 Word Count RDD (Resilient Distributed dataset), 弹性分布式数据集. 示意图 1. 实现 1.1 分步实现 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
随机推荐
- [NOI 2016]循环之美
Description 题库链接 给出十进制下的 \(n,m,k\) ,求 \(\frac{i}{j},i\in[1,n],j\in[1,m]\) 在 \(k\) 进制下不同的纯循环小数个数. 纯循环 ...
- Java中异常发生时代码执行流程
异常与错误: 异常: 在Java中程序的错误主要是语法错误和语义错误,一个程序在编译和运行时出现的错误我们统一称之为异常,它是VM(虚拟机)通知你的一种方式,通过这种方式,VM让你知道,你(开发人员) ...
- 深入出不来nodejs源码-events模块
这一节内容超级简单,纯JS,就当给自己放个假了,V8引擎和node的C++代码看得有点脑阔疼. 学过DOM的应该都知道一个API,叫addeventlistener,即事件绑定.这个东西贯穿了整个JS ...
- MVC应用程序显示Flash(swf)视频
前段时间, Insus.NET有实现<MVC使用Flash来显示图片>http://www.cnblogs.com/insus/p/3598941.html 在演示中,它也可以显示Flas ...
- Commonjs、AMD、CMD
CommonJS 该规范的核心思想是允许模块通过 require 方法来同步加载所要依赖的其他模块,然后通过 exports 或 module.exports 来导出需要暴露的接口 require(& ...
- golang中的接口实现(一)
golang中的接口实现 // 定义一个接口 type People interface { getAge() int // 定义抽象方法1 getName() string // 定义抽象方法2 } ...
- 临时表 on commit delete rows 与 on commit preserve rows 的区别
-- 事务级临时表:提交时删除数据 create global temporary table tmp_table1 ( x number ) on commit delete ...
- 非常可乐(杭电hdu1495)bfs
非常可乐 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- 并发修改异常(ConcurrentModificationException)
并发修改异常(ConcurrentModificationException) 这个异常,使用集合的时候应该很常见,这个异常产生的原因是因为java中不允许直接修改集合的结构. 先贴上个有趣的例子,给 ...
- POJ2478(SummerTrainingDay04-E 欧拉函数)
Farey Sequence Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 16927 Accepted: 6764 D ...