[Spark Core] Spark 核心组件
0. 说明
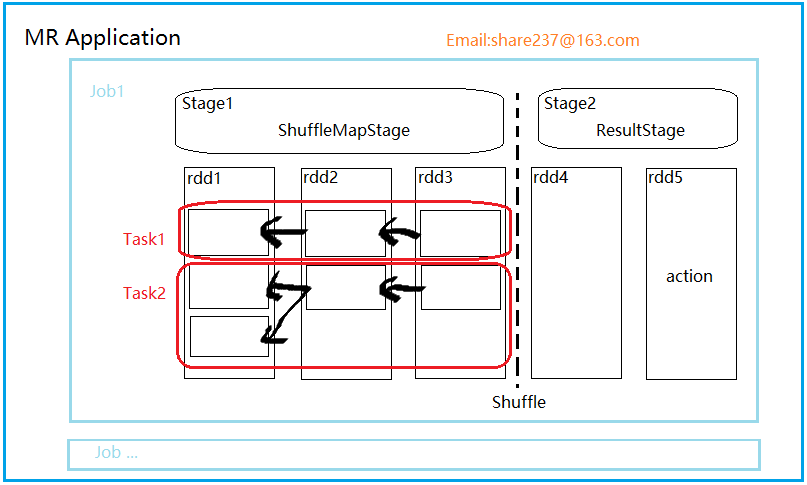
【Spark 核心组件示意图】
1. RDD
resilient distributed dataset , 弹性数据集
轻量级的数据集合,逻辑上的集合。等价于 list
没有携带数据。
2. 依赖
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
3. Stage(阶段)
并行的 task 集合,同一 Stage 的所有任务有着相同的 Shuffle 依赖。
阶段,一组RDD构成的链条。
阶段的划分按照 Shuffle 标记来进行的。
阶段类型有两种,ShuffleMapStage 和ResultStage。
【ShuffleMapStage】
该阶段任务的结果是下一个阶段任务的输入。需要跟踪每个分区所在的节点。
任务执行期间的中间过程,保存task的输出数据供下一个 reduce 进行 fetch(抓取) 。
该阶段可以单独提交。
【 ResultStage】
结果结果直接执行 RDD 的 action 操作。
对一些分区应用计算函数(不一定需要在所有分区进行计算,比如说first())。
最后一个阶段,执行task后的结果回传给driver
4. Task
task 是 Spark 执行单位,有两种类型。
【ShuffelMapTask】
在 ShuffleMapStage 由多个 ShuffleMapTask 组成。
【ResultTask】
ResultStage 由多个 ResultTask 组成,结果任务直接 task 后,将结果回传给 driver。
driver:
5. job
一个 action 就是一个 job
6. Application
一个应用可以包含多个 job
7. Spark Context
Spark 上下文是 Spark 程序的主入口点,表示到 Spark 集群的连接。可以创建 RDD 、累加器和广播变量。
每个 JVM 只能有一个 active 的上下文,如果要创建新的上下文,必须将原来的上下文 stop。
sc.textFile("");
sc.parallelize(1 to 10);
sc.makeRDD(1 to 10) ; //通过parallelize实现。
[Spark Core] Spark 核心组件的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [Spark Core] Spark Client Job 提交三级调度框架
0. 说明 官方文档 Job Scheduling Spark 调度核心组件: DagScheduler TaskScheduler BackendScheduler 1. DagSchedule ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- 【待补充】[Spark Core] Spark 实现标签生成
0. 说明 在 IDEA 中编写 Spark 代码实现将 JSON 数据转换成标签,分别用 Scala & Java 两种代码实现. 1. 准备 1.1 pom.xml <depend ...
- [Spark Core] Spark 在 IDEA 下编程
0. 说明 Spark 在 IDEA 下使用 Scala & Spark 在 IDEA 下使用 Java 编写 WordCount 程序 1. 准备 在项目中新建模块,为模块添加 Maven ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- [Spark Core] Spark Shell 实现 Word Count
0. 说明 在 Spark Shell 实现 Word Count RDD (Resilient Distributed dataset), 弹性分布式数据集. 示意图 1. 实现 1.1 分步实现 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
随机推荐
- 制作openstack使用的Ubuntu镜像
一.环境准备 OS:Ubuntu-14.04 制作镜像版本:Ubuntu-14.04.4-server-amd64.iso 查看是否支持虚拟化(有输出代表支持,否则在BIOS页面中设置即可): egr ...
- Java 使用pipeline对redis进行批量读写
code import redis.clients.jedis.Jedis; import redis.clients.jedis.Pipeline; import java.util.List; p ...
- spring配置文件引入properties文件:<context:property-placeholder>标签使用总结
一.问题描述: 1.有些参数在某些阶段中是常量,比如: (1)在开发阶段我们连接数据库时的连接url.username.password.driverClass等 (2)分布式应用中client端访问 ...
- Android studio删除工程项目
本新手最近学Android都是用的eclipse.其实个人觉得eclipse不错,可能接触Android不久,倒也不觉得它慢还是怎样.对于Google的Android studio也是早有耳闻,前两天 ...
- PCA算法学习(Matlab实现)
PCA(主成分分析)算法,主要用于数据降维,保留了数据集中对方差贡献最大的若干个特征来达到简化数据集的目的. 实现数据降维的步骤: 1.将原始数据中的每一个样本用向量表示,把所有样本组合起来构成一个矩 ...
- java锁的简化
java使用单独的锁对象的代码展示 private Lock bankLock = new ReentrantLock(); //因为sufficientFunds是锁创建的条件所以称其为条件对象也叫 ...
- java环境配置及原理详解
java环境配置及原理详解 1.java跨平台的本质 我们谈到java,总是提到跨平台这个词.那么java语言是怎么实现跨平台的呢? 我们编写的java代码不是直接让windows系统读取解析,而是在 ...
- oracle 11g 分区表创建(自动按年、月、日分区)
前言:工作中有一张表一年会增长100多万的数据,量虽然不大,可是表字段多,所以一年下来也会达到 1G,而且只增不改,故考虑使用分区表来提高查询性能,提高维护性. oracle 11g 支持自动分区,不 ...
- Java的类加载过程
一个Java文件从编码完成到最终执行,一般主要包括两个过程:编译与运行.编译即将Java文件通过Javac命令生成.class文件的过程,运行就是将.class文件交给JVM进行执行. 类加载过程即是 ...
- 【 js 基础 】【 源码学习 】backbone 源码阅读(三)
最近看完了 backbone.js 的源码,这里对于源码的细节就不再赘述了,大家可以 star 我的源码阅读项目(https://github.com/JiayiLi/source-code-stud ...