马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
(1)观察集群配置情况
[root@master ~]# hdfs dfsadmin -report
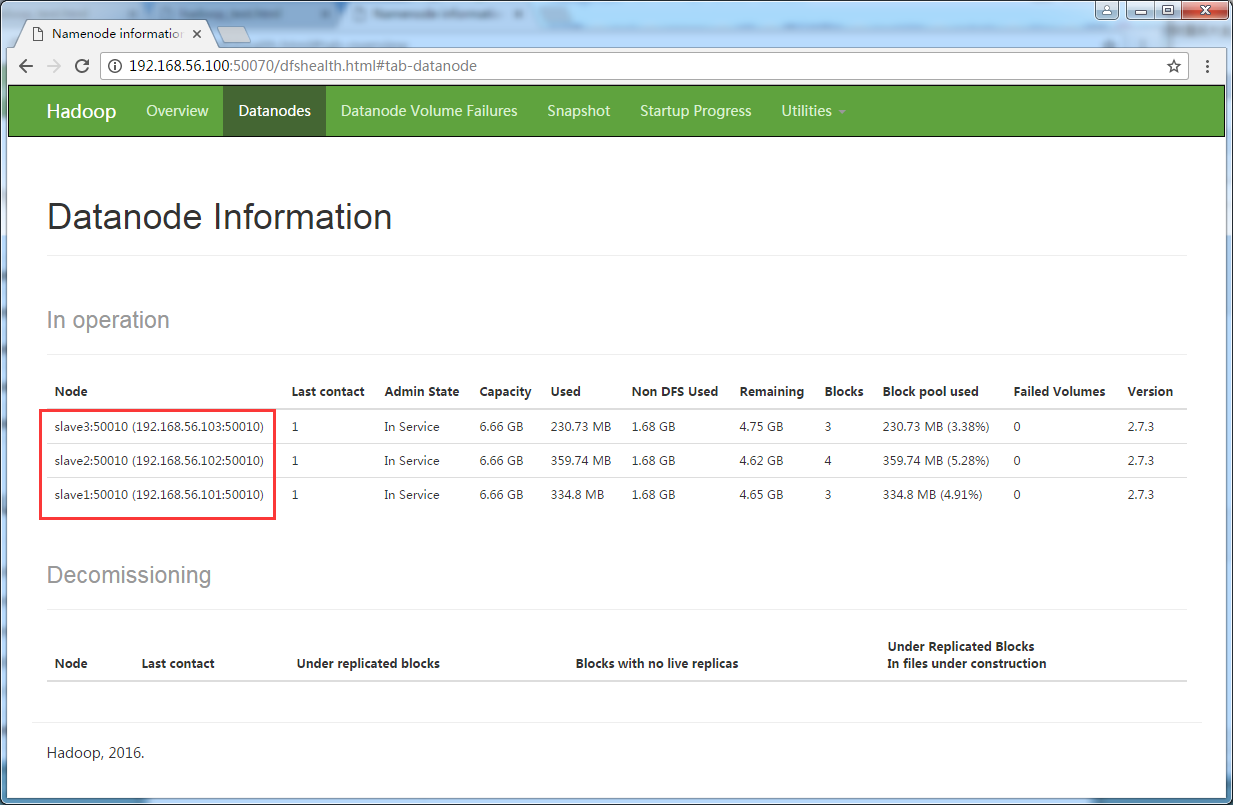
(2)web界面观察集群运行情况
使用netstat命令查看端口监听
[root@master ~]# netstat -ntlp
浏览器地址栏输入:http://192.168.56.100:50070
(3)对集群进行集中管理
a) 修改master上的/usr/local/hadoop/etc/hadoop/slaves文件
[root@master hadoop]# vim slaves
#编辑内容如下
slave1
slave2
slave3
先使用hadoop-daemon.sh stop namenode(datanode)手工关闭集群。
b) 使用start-dfs.sh启动集群
[root@master hadoop]# start-dfs.sh
发现需要输入每个节点的密码,太过于繁琐,于是需要配置免密ssh远程登陆。
在master上用ssh连接一台slave,需要输入密码slave的密码,
[root@master hadoop]# ssh slave1
需要输入密码,输入密码登陆成功后,使用exit指令退回到master。
c) 免密ssh远程登陆
生成rsa算法的公钥和私钥
[root@master hadoop]# ssh-keygen -t rsa (然后四个回车)
进入到/root/.ssh文件夹,可看到生成了id_rsa和id_rsa.pub两个文件。
使用以下指令完成免密ssh登陆
[root@master hadoop]# ssh-copy-id slaveX
更多细节讲解,请查看马士兵hadoop第二课视频讲解:http://pan.baidu.com/s/1qYNNrxa
使用stop-dfs.sh停止集群,然后使用start-dfs.sh启动集群。
[root@master ~]# stop-dfs.sh
[root@master ~]# stop-dfs.sh
(3)修改windows上的hosts文件,通过名字来访问集群web界面
编辑C:\Windows\System32\drivers\etc\hosts
192.168.56.100 master
然后就可以使用http://master:50070代替http://192.168.56.100:50070
(4) 使用hdfs dfs 或者 hadoop fs命令对文件进行增删改查的操作
hadoop fs -ls /
hadoop fs -put file /
hadoop fs -mkdir /dirname
hadoop fs -text /filename
hadoop fs -rm /filename
将hadoop的安装文件put到了hadoop上操作如下
[root@master local]# hadoop -fs put ./hadoop-2.7.3.tar.gz /
通过网页观察文件情况

(5)将dfs-site.xml的replication值设为2
replication参数是分块拷贝份数,hadoop默认为3。
也就是说,一块数据会至少在3台slave上都存在,假如slave节点超过3台了。
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>10000</value>
</property>
</configuration>
为了方便测试,同时需要修改另外一个参数dfs.namenode.heartbeat.recheck-interval,这个值默认为300s,
将其修改成10000,单位是ms,这个参数是定期间隔时间后检查slave的运行情况并更新slave的状态。
可以通过 hadoop-2.7.3\share\doc\hadoop\index.html里面查找这些默认的属性


修改完hdf-size.xml文件后,重启hadoop集群,
stop-dfs.sh #停止hadoop集群
start-dfs.sh #启动hadoop集权
hadoop -fs put ./jdk-8u91-linux-x64.rpm / #将jdk安装包上传到hadoop的根目录
到web页面上去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况
hadoop-daemon.sh stop datanode #在slave3上停掉datanode
等一会时间后(大概10s,前面修改了扫描slave运行情况的间隔时间为10s),刷新web页面
观察到slave3节点挂掉
hadoop-daemon.sh start datanode #在slave3上启动datanode
然后再去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作的更多相关文章
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言 上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令: hdfs dfs -ls xxx hdfs dfs -mkdir -p /xxx/xxx hdfs dfs -cat ...
- Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content) 一.Hadoop客户端配置 二.Java访问HDFS集群 2.1.HDFS的Java访问接口 2.2.Java访问HDFS主要编程步骤 2.3.使用FileSystem A ...
- Hadoop集群-HDFS集群中大数据运维常用的命令总结
Hadoop集群-HDFS集群中大数据运维常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简单涉及到滚动编辑,融合镜像文件,目录的空间配额等运维操作简介.话 ...
- Hadoop学习笔记1 - 使用Java API访问远程hdfs集群
转载请标注原链接 http://www.cnblogs.com/xczyd/p/8570437.html 2018年3月从新司重新起航了.之前在某司过了的蛋疼三个月,也算给自己放了个小假了. 第一个小 ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- hbase+hadoop+hdfs集群搭建 集成spring
序言 最近公司一个汽车项目想用hbase做存储,然后就有了这篇文字,来,来,来, 带你一起征服hbase,并推荐一本书<hbase权威指南> 这是一本极好的hbase入门书籍,我花了一个晚 ...
随机推荐
- postman断言的几种方式(二)
1.检查响应体是否包含字符串 pm.test("Body matches string", function () { pm.expect(pm.response.text()). ...
- javascript沙箱模式
沙箱模式解决了命名空间模式的如下几个缺点: 1.对单个全局变量的依赖变成了应用程序的全局变量依赖.在命名空间模式中,是没有办法使同一个应用程序或库的2个版本运行在同一个页面中.2.对这种以点分割的名字 ...
- 解决Tomcat6解压版在64位windows系统上无法启动服务的问题
解决Tomcat6解压版在64位windows系统上无法启动服务的问题 由于客户环境为64位windows系统,开发环境一直用32位.tomcat使用6.0.20非安装版.部署时发现在 ...
- [转]hisi mmz模块驱动讲解
一.概述 如图所示,在海思平台上将内存分为两个部分:os内存和mmz内存.os内存指:由linux操作系统管理的内存:mmz内存:由mmz驱动模块进行管理供媒体业务单独使用的内存,在驱动加载时可以指定 ...
- linux下brctl配置网桥
原文:http://zhumeng8337797.blog.163.com/blog/static/1007689142011643834429/ 先装好网卡,连上网线,这是废话,不用说了. 然后开始 ...
- pip 18.1: pipenv graph results in ImportError: cannot import name 'get_installed_distributions'
I'm currently using python3 -m pip install pip==10.0.1python3 -m pip install pipenv==2018.5.18 Once ...
- 升级Chrome后无法打开网页
最近升级了网站,发现很多普通网站Chrome 都打不开了.... IE 可以正常打开,很是郁闷,重启电脑都不行. chrome://net-internals/#dns 点击如下按钮 清楚DNS缓 ...
- Reactor模型-单线程版
Reactor模型是典型的事件驱动模型.在网络编程中,所谓的事件当然就是read.write.bind.connect.close等这些动作了.Reactor模型的实现有很多种,下面介绍最基本的三种: ...
- 7z
7zip是一款开源的解压缩软件,不仅自己独有的7z格式,而且支持zip,rar,tar,gzip等众多其他格式,同时7z格式的压缩比例很高,目前很多硬盘版的游戏都采用zip进行打包.下面介绍一下Lin ...
- SqlServer行转列(PIVOT),列转行(UNPIVOT)总结
PIVOT用于将列值旋转为列名(即行转列) 语法: table_source PIVOT( 聚合函数(value_column) FOR pivot_column IN(<column_list ...