数据同步canal客户端
1、增量订阅、消费设计
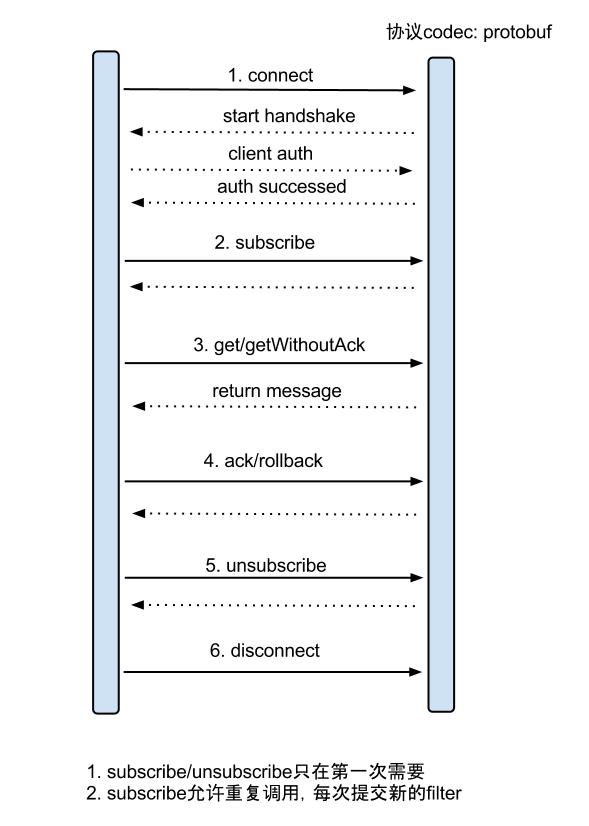
get/ack/rollback协议介绍:
① Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto
② void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
③ void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
2、数据对象格式:EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组] Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
3、client使用例子
3.1 创建Connector
a. 创建SimpleCanalConnector (直连ip,不支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");
b. 创建ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");
c. 创建ClusterCanalConnector (基于固定canal server的地址,支持固定的server ip的failover机制,不支持client的failover机制
CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
如上可见,创建client connector的时候需要指定destination,即对应于一个instance,一个数据库。所以canal client和数据库是一一对应的关系。
3.2 get/ack/rollback使用
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(canal_ip, 11111), destination, canal_username, canal_password); try { // 连接canal,获取数据
connector.connect();
connector.subscribe();
connector.rollback();
log.info("数据同步工程启动成功,开始获取数据");
while (true) { // 获取指定数量的数据
Message message = connector.getWithoutAck(1000); // 数据批号
long batchId = message.getId(); // 获取该批次数据的数量
int size = message.getEntries().size(); // 无数据
if (batchId == -1 || size == 0) { // 等待1秒后重新获取
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.error(e);
Thread.currentThread().interrupt();
} // 提交确认
connector.ack(batchId); // 数据存在,执行方法
} else {
try { // 处理数据
HandleData.handleEntry(message.getEntries()); // 提交确认
connector.ack(batchId);
} catch (KafkaException e) {
log.error(e); // 处理失败, 回滚数据
connector.rollback(batchId);
} catch (Exception e1) {
log.error(e1); // 提交确认
connector.ack(batchId);
}
}
}
} catch (Exception e) { log.error(e);
} finally { // 断开连接
connector.disconnect();
}
处理数据的方法封装到HandleData类中,且看handleEntry如何处理
// 获取日志行
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
log.error(e);
} // 获取执行事件类型
EventType eventType = rowChage.getEventType(); // 日志打印,数据明细
log.info(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry
.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader()
.getSchemaName(), entry.getHeader().getTableName(), eventType)); // 获取表名
String tableName = entry.getHeader().getTableName(); // 遍历日志行,执行任务
for (RowData rowData : rowChage.getRowDatasList()) {
Map<String, Object> data; // 删除操作
if (eventType == EventType.DELETE) { // 解析数据
data = DataUtils.parseData(tableName, "delete", rowData.getBeforeColumnsList()); // 插入操作
} else if (eventType == EventType.INSERT) { // 解析数据
data = DataUtils.parseData(tableName, "insert", rowData.getAfterColumnsList()); // 更新操作
} else { // 解析数据
data = DataUtils.parseData(tableName, "update", rowData.getAfterColumnsList());
} // 数据解析成功
if (data != null && data.size() > 0) { // 内容转接json格式发送
JSONObject json = JSONObject.fromObject(data);
try {
Productor.send("canal_" + tableName = "_topic", json.toString(), tableName + "|" + data.get("canal_kafka_key"));
} catch (Exception e) {
throw new KafkaException("kafka发送异常:" + e);
} log.info("数据成功发送kafka");
}
}
Entry数据被解析成Map格式数据,然后转为json字符串,发到kafka。为什么要借用消息中间件kafka呢,不用kafka可以吗?当然可以,直接写数据同步的逻辑没有问题。但是如果一个数据用到多个业务场景,势必导致一个类中有多套同步逻辑,对于后期的维护很不利,多套业务掺杂在一起势必会互相影响。合理的做法应该是业务隔离,每套业务都能接受到数据变更的消息,然后做自己需要的同步,这样就需要在数据接受和数据处理形成1对n的关系。消息中间件的消息接受和消费模型正好可以完成这个功能。
一个canal client的消息分发给多个kafka消费者消费。每个kafka消费者代表一种业务场景,架构清晰、利于维护,同时一个kafka消费者可以消费多个canal client的topic。
上面的解析数据逻辑比较简单,将list解析成map
Map<String, Object> result = new HashMap<String, Object>();
try {
int index = 0;
for (Column column : columns) {
String value = column.getIsNull() ? null : column.getValue(); // kafka在消息为10K时吞吐量达到最大
if (value != null && value.length() > 10240) {
value = value.substring(0, 10240);
}
if (index == 0) {
result.put("canal_kafka_key", value);
}
result.put(column.getName(), value);
index++;
}
result.put("operate_type", "delete"||"insert"||"update");
} catch (Exception e) {
log.error(e);
}
if (logStr.lastIndexOf(",") == logStr.length() - 1) {
logStr = logStr.substring(0, logStr.length() - 1);
}
return result;
数据同步canal客户端的更多相关文章
- 数据同步canal服务端介绍
1.下载安装包 canal&github的地址,最权威的学习canal相关知识的地方 https://github.com/alibaba/canal 在下面的wiki列表中找到AdminGu ...
- 数据同步canal服务端HA配置
canal服务端HA模式,本人并未使用过,为保证文章的完整性,从以下地址摘抄该部分内容,待以后验证及使用 https://github.com/alibaba/canal/wiki/AdminGuid ...
- 数据同步canal服务端配置mysql多主
canal服务端HA模式,本人并未使用过,为保证文章的完整性,从以下地址摘抄该部分内容,待以后验证及使用 https://github.com/alibaba/canal/wiki/AdminGuid ...
- CentOS7下rsync服务端与Windows下cwRsync客户端实现数据同步配置方法
最近需求想定期备份服务器d盘的数据到Linux服务器上面,做个笔记顺便写下遇到的问题 以前整过一个win下的cwrsync(客户端)+rsync(服务端:存储)的bat脚本 和整过一个Linux下的r ...
- Linux-非结构化数据同步-Linux下Rsync+Rsync实现非结构化增量差异数据的同步2
说明: 操作系统:CentOS 5.X 源服务器:192.168.21.129 目标服务器:192.168.21.127,192.168.21.128 目的:把源服务器上/home/www.osyun ...
- canal数据同步 客户端代码实现
1.引入相关依赖 <dependencies> <dependency> <groupId>org.springframework.boot</groupId ...
- canal数据同步目录
我们公司对于数据同步有以下需求 1.多个mysql库中有一些基础表需要数据统一,mysql跨库同步 2.mysql热数据加载到redis 3.全文检索需要mysql同步到es 4.数据变更是附属的其它 ...
- 阿里Canal框架(数据同步中间件)初步实践
最近在工作中需要处理一些大数据量同步的场景,正好运用到了canal这款数据库中间件,因此特意花了点时间来进行该中间件的的学习和总结. 背景介绍 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存 ...
- 基于canal的client-adapter数据同步必读指南
本文将介绍canal项目中client-adapter的使用,以及落地生产中需要考虑的可靠性.高可用与监控报警.(基于canal 1.1.4版本) canal作为mysql的实时数据订阅组件,实现了对 ...
随机推荐
- 【14】代理模式(Proxy Pattern)
一.引言 在软件开发过程中,有些对象有时候会由于网络或其他的障碍,以至于不能够或者不能直接访问到这些对象,如果直接访问对象给系统带来不必要的复杂性.这时候可以在客户端和目标对象之间增加一层中间层,让代 ...
- AOP 应用 性能
AOP 我的感觉是做些日志什么的比较好,比如在每个controller的api前后搞一下,或者做些metric.今天在spring里用了下AOP并简单的测了一下性能. 使用 业务类 public cl ...
- 【 js 基础 】【 源码学习 】 深浅拷贝
underscore的源码中,有很多地方用到了 Array.prototype.slice() 方法,但是并没有传参,实际上只是为了返回数组的副本,例如 underscore 中 clone 的方法: ...
- 关于子元素的margin-top对父级容器无效
如果不想看那么长,看下面这句话就好了. 刚开始我没看到这个总结时一直是使用自己摸索出来paddin-top解决,发现该方式并不好.亲测给父级加一个overflow不为visiable的属性就直接解决了 ...
- BZOJ5289: [Hnoi2018]排列
传送门 第一步转化,令 \(q[p[i]]=i\),那么题目变成: 有一些 \(q[a[i]]<q[i]\) 的限制,\(q\) 必须为排列,求 \(max(\sum_{i=1}^{n}w[i] ...
- 【读书笔记】iOS-网络-测试与操纵网络流量
一,观测网络流量. 观测网络流量的行为叫做嗅探或数据包分析. 1,嗅探硬件. 从iOS模拟器捕获数据包不需要做特别的硬件或网络配置.如果需要捕获这些数据包,那么可以使用嗅探软件来监听回送设备或是用于连 ...
- import、export使用介绍
import.export使用介绍 ES6提供的import.export方法, 使组件化开发模式迈向新高度.本文来介绍import.export的语法及使用方法. 根据 export 的导出方式,可 ...
- AngularJS学习之 angular-file-upload控件使用方法
1.官方链接 https://github.com/nervgh/angular-file-upload 2.安装到项目中 bower install angular-file-upload(安装完成 ...
- 如何在Vue中建立全局引用或者全局命令
1 一般在vue中,有很多vue组件,这些组件每个都是一个文件.都可能需要引用到相同模块(或者插件).我们不想每个文件都import 一次模块. 如果是基于vue.js编写的插件我们可以用 Vue.u ...
- ArcGIS Server + ArcGIS Portal 10.5
1.安装IE11 2. 域名需要在C:\Windows\System32\drivers\etc\host文件中添加 127.0.0.1 机器名.域名 win2008.smartmap.com 19 ...