[Latex] 所有字体embedded: Type3 PDF文档处理 / True Type转换为Type 1
目录:
[正文] Adobe Acrobat打印解决字体嵌入问题
[Appendix I] Type3转TRUE Type/Type 1
[Appendix II] TRUE Type转Type 1 (并embedded)
================================
准备提交给ACM与IEEE的论文时,我们手头的文档除了有明确具体字体类型的Type1和TrueType字体外,还经常会出现Type3字体,这种字体现在在杂志印刷过程中是不予接受的。
Type 3 字体是矢量外框字体,很多网站所称Type 3是点阵字体其实是错误的。不同于 Type 1,PostScript Type 3 字体不支援 Hinting,该技术优化了小字型的字形状,意味着 PostScript Type 1 在低解析度的雷射印表机或是荧幕上的品质表现略胜一筹。[1][2]
Latex不能精确识别的字体也会被归类到Type 3。这种字体在印刷刊物中有可能出现印刷错误,编译为.dvi文件时也有几率发生错误。Type 3基本上已经被淘汰,在正式文档中是需要尽量规避的。
实际上重新打印就能解决。
Adobe Acrobat打印解决字体嵌入问题
1. 定位问题:
下载Adobe Acrobat进行查看以及后续的嵌入 (注意!不是Abobe Reader!)
Adobe Acrobat 9.0的无需激活破解版比较好找,以下是云盘链接:
https://pan.baidu.com/s/12XD5YfaxCmB9L2cvVLugXA
http://pan.baidu.com/share/link?uk=1579679242&shareid=2902479474
https://www.panc.cc/s/[Acrobat.9.].APRO9_Win_ESD1_CS
安装后,用Adobe Acrobat打开pdf,然后打开 文件-> 属性,会看到没有嵌入的字体
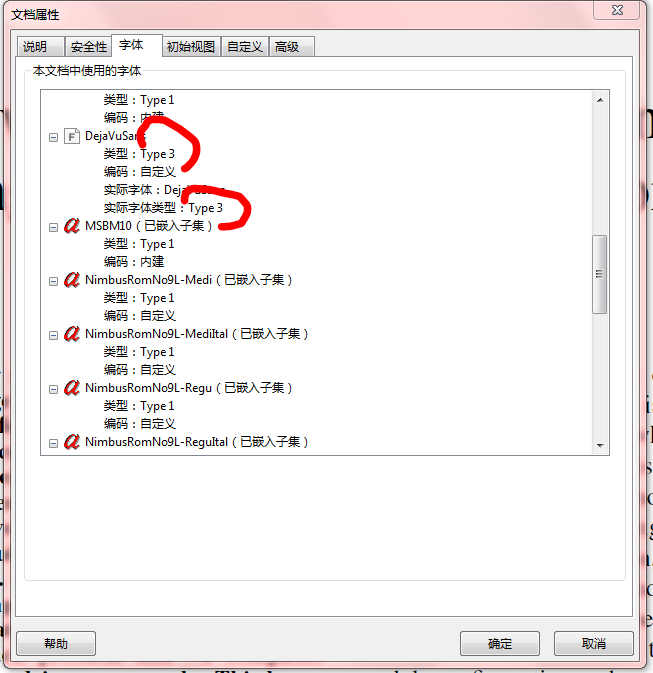
2. 嵌入字体
文件-> 打印 -> 打印机选adobe pdf -> 点选旁边的属性
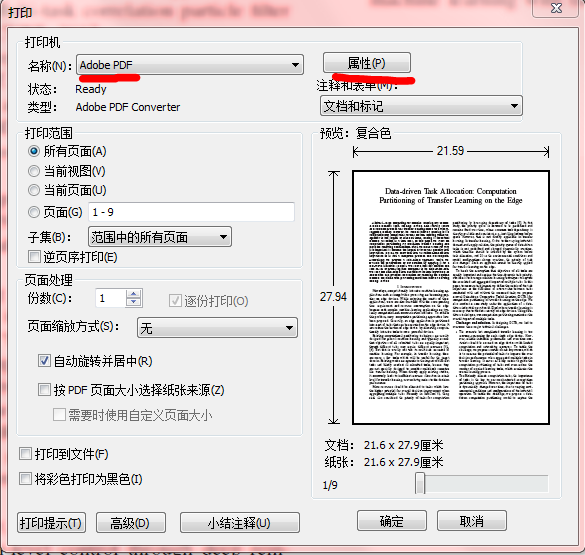
在 adobe pdf设置 选项卡里,第一行找到 默认设置,点出下拉菜单,选高质量打印,点击OK
另:顺便查看下页面大小(有些论文要求必须是Letter而不是A4),是否添加文档信息(双盲会议有些会要求pdf中不能包含任何文档信息,以防泄露作者身份)
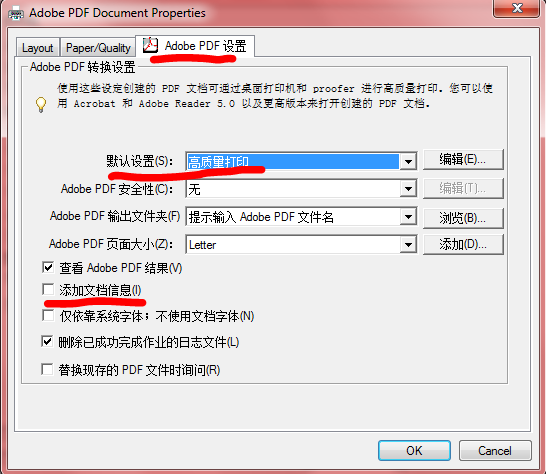
打印,所有type 3和true type都将被转换为type 1,问题解决
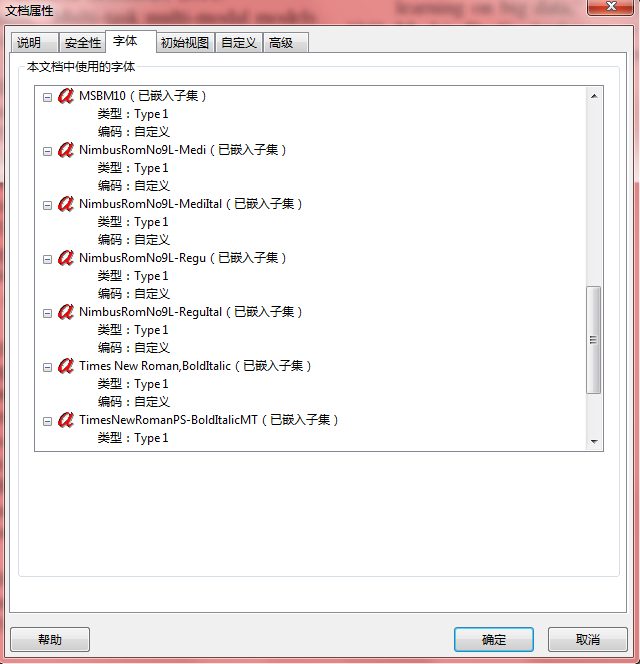
================================
下面是一些以前的老办法,相比更加麻烦也不一定能起作用,仅供必要(如以上做法失效)时参考
Appendix I
一、Type3 文件的识别
1、整体识别
1)阅读器
用adobe/foxit 等reader打开pdf文件,"文件 -> 属性" 打开属性对话框,找到“字体”项目,可以看到pdf所包含的字体信息。通常如果有type3,会直接显示在最前面。
2)Linux下使用命令
要检查PDF文件中包含了,或者使用了什么字体,你可以使用命令行工具:pdffonts。它是一个PDF字体分析工具。pdffonts是Poppler PDF工具集包中的一个部分。
a) 直接使用命令 [5]
pdffonts可以列出PDF文档中使用的所有字体。
pdffonts的基本用法: pdffonts paper.pdf
pdffonts工具显示了各个已使用的字体的各种信息,如字体名称/类型等等。看输出是否含有type3字体。
b) linux下安装命令支持包
要安装Poppler到Debian,Ubuntu或Linux Mint:
- $ sudo apt-get install poppler-utils
- $ sudo yum install poppler-utils
pdffonts可以列出PDF文档中使用的所有字体。pdffonts的基本用法如下。
- $ pdffonts doc.pdf
2、问题定位
1)Windows
先注释全文,编译latex,查看生成pdf内字体类型,通常是type1。
然后逐章解开注释,编译latex,查看生成pdf内字体类型,直到出现type3。
再于没问题的上一章和有问题的这一章之间逐步注释并编译查看,直到定位到type3所在。
2)Linux
如果一个PDF文档有多页,你可以使用“-f”(首页)和“-l”(末页)选项来限制字体扫描页面范围。例如,如果你想要找出某个文档中的5-10页中使用了哪种字体,运行该命令 $ pdffonts -f 5-l 10 doc.pdf
二、Type3 文件的处理
1)整体处理
a)先考虑官方的建议,在文件头部加入以下命令(T1包含在cm-super宏包中 [4])并重新编译 [5]:
\usepackage[T1]{fontenc}
\usepackage{aecompl}
笔者的离线latex不支持这两种包,会出现错误。
b)安装cm-super宏包
Tex -> MikTex -> MikTex Package Manager -> 在name中寻找所需的包并安装
问题依旧的话,应该是插图中含有type3字体。 比如用Python或Matlab画图,默认的似乎就是输出成type3 [5],那么往下看2)。
2)对已有图片的处理
Python和Matlab生成的图片字体,默认输出就是Type3。有几种可能的处理方法:
a) eps2eps [3][5]
eps2eps命令是包含在texlive发行版中的小工具,它能把一个eps图片中字体全部曲线化,转换后的eps再转成pdf时,不带任何字体信息。
所以我们可以将出问题的图片(如果是eps格式)用eps2eps转换一遍。
用法:Accessories -> Command Prompt 打开命令行,接着 eps2eps your.eps output.eps
但是,有人指出这样图片会变得不清晰;笔者这里是出现图片会被部分截取的情况。
b) epstopdf, pdftops [5]
先转成pdf再转回eps, 比如对fig.eps, Accessories -> Command Prompt 打开命令行, 然后使用命令:
epstopdf fig.eps fig.pdf
pdftops -eps -r 400 fig.pdf fig.eps
笔者这边是出现pdftops命令不兼容的情况。
c) convert-to-eps website
将问题图片上传至http://image.online-convert.com/convert-to-eps,下载下来也是eps,但字体也会被曲线化,从而使得图片不再是type3。注意图片会增大到数MB。
这个比较好使,多次解决了笔者的问题。
但其中有一次图片实在太多,并且我们使用有编译时间限制的在线latex,从而出现了超时问题。详细解决方法和讨论传送门:http://www.cnblogs.com/zeedmood/p/8991821.html
三、Python的处理
比如用python画图,默认就是输出成type3 [5]
修改 ~/.matplotlib/matplotlibrc
加入(或者修改)如下两行
ps.fonttype : 42 # Output Type 3 (Type3) or Type 42 (TrueType)
pdf.fonttype : 42 # Output Type 3 (Type3) or Type 42 (TrueType)
四、Adobe Acrobat
Adobe Acrobat另存为的优化pdf格式,也可以用于去除Type 3 ,但最好设置下分辨率,避免图的质量过分下降。可以改成以下设置:

Reference
[1] PostScript fonts https://en.wikipedia.org/wiki/PostScript_fonts#Type_3
[2] 请问Type3字体有什么特别? http://www.cnprint.org/bbs/thread/165/180556/
[3] origin作图,避免里面有Type 3 字体 http://www.cnblogs.com/pankejia/p/3476432.html
[4] How to generate pdf without any Type3 fonts? http://tex.stackexchange.com/questions/18687/how-to-generate-pdf-without-any-type3-fonts
[5] 提交MNRAS的pdf文件中type3字体问题 http://asc.2dark.org/node/188
================================================================
Appendix II: True Type转换为Type 1
某些会议(如 INFOCOM等使用EDAS系统的)还会要求将TRUE Type转换为Type 1 或者要求全部字体都需要embedded。
The paper PDF file cannot be accepted: Publishers require that PDF fonts are embedded so that documents can be printed everywhere; one or more of your document fonts are not embedded

首先,定位问题:
下载Adobe Acrobat进行查看以及后续的嵌入 (注意!不是Abobe Reader!)
Adobe Acrobat 9.0的无需激活破解版比较好找,以下是云盘链接:
http://pan.baidu.com/share/link?uk=1579679242&shareid=2902479474
https://www.panc.cc/s/[Acrobat.9.].APRO9_Win_ESD1_CS
安装后,用Adobe Acrobat打开pdf,然后打开 文件-> 属性,会看到没有嵌入的字体

打开另存为->保存为pdf(优化)->设置

可以再次确认是没有字体嵌入的
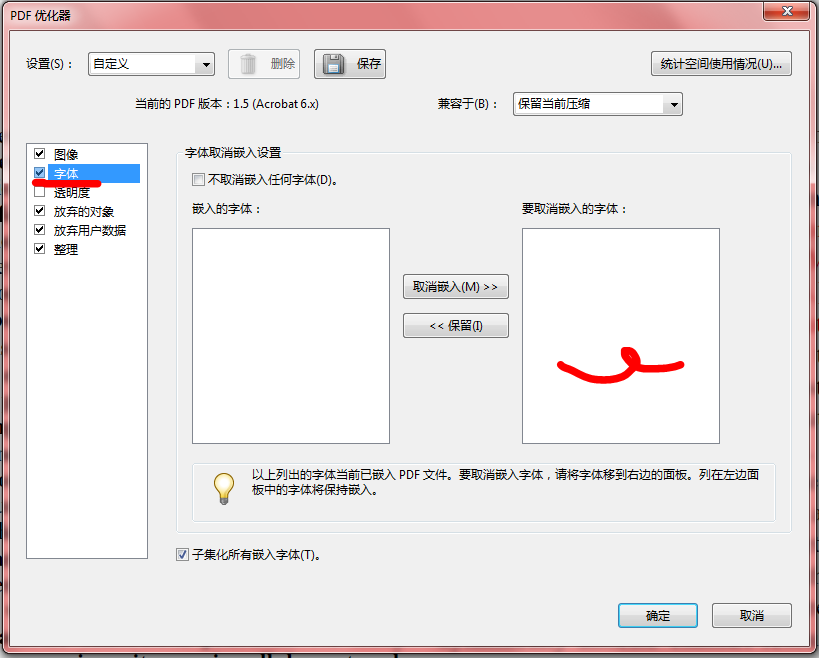
解决方法:
(1)True Type图片将矢量图转换为位图,去除文字
有些软件的矢量图,如Visio,其生成的图片pdf就经常有True Type文字;
一个简单的方法,就是定位到有True Type的图片后(通常是矢量图),将其转换为位图(如JPG、BMP),如果文章中格式有需要可以再转换回pdf(当然,这样依然是位图)。为了保证放大后的清晰度,尽量选择不要压缩
Visio保存成JPG或者BMP就不是矢量图了,没有内嵌文字,自然也不会有True Type。JPG转PDF可以用这个网站:http://jpg2pdf.com/
这个方法优点是简单粗暴,而且每个图基本都比较清晰
缺点是需要一个图一个图弄,而且图中的文字无法搜索到
(2)使用Adobe Acrobat的打印功能,将True Type转为Type 1
优点是一次通杀,不需要逐个去改;通常矢量图也能保留
缺点是有些原本就是位图的图片,被打印后容易出现不清晰的情况
用Adobe Acrobat中打印,在高级-> PostScript选项中点开其 “将TRUE Type转Type 1” 功能即可
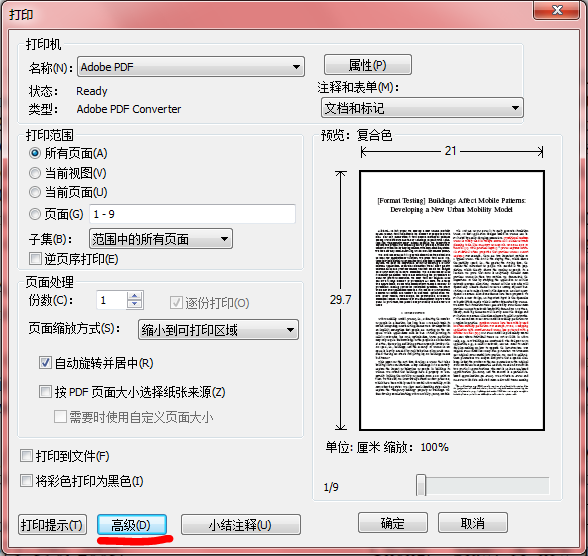

可以看到新文档已经没有TRUE Type类型了

打开另存为->保存为pdf(优化)->设置

可以再次确认字体已经嵌入了

[Latex] 所有字体embedded: Type3 PDF文档处理 / True Type转换为Type 1的更多相关文章
- PDF 补丁丁 0.4.2.1013 测试版发布:修复替换PDF文档字体等问题
新的测试版修复了若干问题,建议下载了旧测试版的用户更新.修复的问题列表: 替换PDF文档字体可能将字体宽度变成0. 书签编辑器在加载XML书签时不显示对应文档的预览. 自动生成书签功能复制文本筛选器后 ...
- C# 在PDF文档中应用多种不同字体
在PDF文档中,可绘制不同字体样式.不同语言的文字,可通过使用Standard字体.TrueType字体.CJK字体或者自定义(私有)等字体类型.下面通过C#程序代码来展示如何实现使用以上类型的字体来 ...
- PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示解决方法
问题:PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示! FlexPaper 与 PDF2SWF 结合是解决在线阅读PDF格式文件的问题的,多页的PDF文件转换可以正常显示,只有一页 ...
- 【PDF】java使用Itext生成pdf文档--详解
[API接口] 一.Itext简介 API地址:javadoc/index.html:如 D:/MyJAR/原JAR包/PDF/itext-5.5.3/itextpdf-5.5.3-javadoc/ ...
- 操作PDF文档功能的相关开源项目探索——iTextSharp 和PDFBox
原文 操作PDF文档功能的相关开源项目探索——iTextSharp 和PDFBox 很久没自己写写心得日志与大家分享了,一方面是自己有点忙,一方面是自己有点懒,没有及时总结.因为实践是经验的来源,总结 ...
- 自动把动态的jsp页面(或静态html)生成PDF文档,并且上传至服务器
置顶2017年11月06日 14:41:04 阅读数:2311 这几天,任务中有一个难点是把一个打印页面自动给生成PDF文档,并且上传至服务器,然而公司框架只有手动上传文档,打印时可以保存为PDF在本 ...
- IText实现对PDF文档属性的基本设置
一.Itext简介 iText是著名的开放源码的站点sourceforge一个项目,是用于生成PDF文档的一个java类库.通过iText不仅可以生成PDF或rtf的文档,而且可以将XML.Html文 ...
- Servlet输出PDF文档方法
概述 Java Servlet 编程可以很方便地将 HTML 文件发送到客户端的 Web 浏览器.然而许多站点还允许访问非 HTML 格式的文档,包括 Adobe PDF.Microsoft Word ...
- 利用iTextSharp组件给PDF文档添加图片水印,文字水印
最近在做关于PDF文档添加水印的功能,折腾了好久,终于好了.以下做个记录: 首先会用到iTextSharp组件,大家可以去官网下载,同时我也会在本文中附加进来. 代码中添加引用为: using S ...
随机推荐
- 转:ASP.NET MVC 多语言实现技巧 最简、最易维护和最快速开发
说说传统做法的缺点 1.做过多语言的都知道这玩意儿太花时间 2.多语言架构一般使用资源文件.XML或者存储数据库来实现.这样就在一定程序上降低了性能 3.页面的可读性变差,需要和资源文件进行来回切换 ...
- StringBuffer&StringBuilder类
0. 说明 1. 总体说明 当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类. 和 String 类不同的是,StringBuffer 和 String ...
- windows的一些好用命令-自己总结:
在win+R运行框中: cmd:进入命令行界面 msconfig:可以查看“系统配置” msinfo32:查看系统信息 services.msc打开"服务&q ...
- 代理工具--mitmproxy
#代理工具 mitmproxy 指令:mitmproxy -b ip -p port(代理ip设置为:ip,端口设置为:port) 拦截request: 输入字母“i”(代表Intercept fil ...
- DevExpress05、TileControl、AlertControl
TileControl控件 该控件是根据Windows 8的用户界面设计的,可以轻松地把各个控制块集成到窗体上. 1. IndertBetweenGroups属性 控制两个Group之间的间距: ...
- Tushare test
查看版本 import tushare print(tushare.__version__) 1.2.12 初步的调用方法为: import tushare as ts ts.get_hist_dat ...
- 异步IO的概念
同步IO是阻塞IO: 异步IO分为两种:1.主动查询是否有数据:2.被动监听是否有数据状态. https://www.cnblogs.com/euphie/p/6376508.html
- Android检查手机上是否安装了第三方软件的方法------本文以百度地图为例
package com.example.myapi.thirdbaidumap; import java.net.URISyntaxException; import java.util.ArrayL ...
- Python3.2-re模块之常用正则记录
python的re模块是个很好的模块,这里简单记录下自己编写的几个有用的正则: 1:邮箱匹配: gReMailbox = re.compile(r'([\w\.\-+]+@[\w\-]+(?:\.[\ ...
- 如何高效的通过BP算法来训练CNN
< Neural Networks Tricks of the Trade.2nd>这本书是收录了1998-2012年在NN上面的一些技巧.原理.算法性文章,对于初学者或者是正在学习NN的 ...