python 爬虫学习之路
2016-6-18
--今天实现了第一个用urllib2实现的爬虫程序。
--过程中发现
req = urllib2.Request(url,headers = headers)
总是报错: 主要原因在于 url 地址错误。
例如:http://www.neihan8.com/wenzi/index_1.html
这个网址打开的是404网页错误。
但是 http://www.neihan8.com/wenzi/index_2.html 这个网页却可以了。
源代码如下:
#-*- coding:utf-8 -*-
import urllib2
class Spider:
'''
内涵段子吧。。。
'''
def load_page(self,page):
'''
发送内涵段子url
'''
url = 'http://www.neihan8.com/wenzi/index_'+ str(page) +'.html'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36"}
req = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(req)
html = response.read()
return html
#main
''' '''
if __name__ == '__main__':
mySpider = Spider()
the_page = mySpider.load_page(2)
print the_page
综上,我们可以在代码中加一个判断 url 是否打开正常的代码,这个需要学习。
-----------------------------------------------------------华丽丽的分割线-------------------------------------------------------------------------------------------------
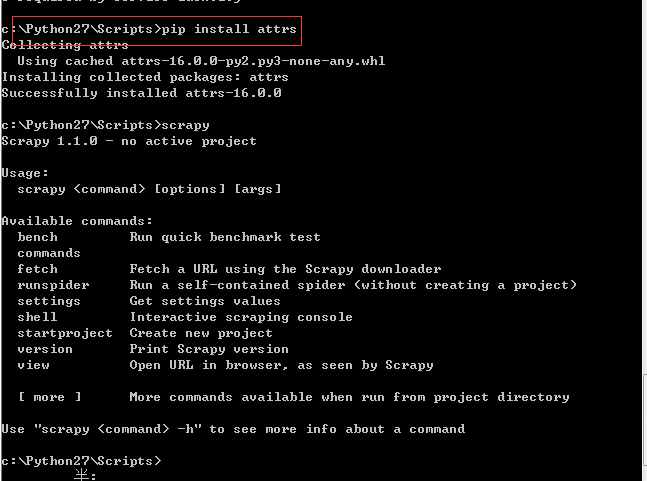
安装Scrapy

--安装scrapy 都要快被安装死了
首先会发现提示 一下问题:
1.版本问题,就是说 Scrapy 所依赖的模块版本太低。'>=1.00' 表明你要使用大于1.0的版本
2.
说明 你有一个包 attrs 没有安装。
那就使用 pip install attrs 安装即可
安装完之后终于正常了。。。。
Python教程:pywin32下载安装
下载链接http://sourceforge.net/projects/pywin32/files/pywin32/Build%20218/pywin32-218.win32-py2.7.exe/download
-------------------------开启爬虫之路----------------------------------------------
首先先说明当中可能遇到的问题:
1.String or binary data would be truncated.解决方法
步骤:在执行插入语句时,会提示上面的error。
原因:是因为数据库中定义的字段长度比较小,在插入或者更新的时候,用一个比这个字段长度大的值去操作,就会引起这个错误。
2.
python向数据库插入中文乱码问题
第一步:数据库那边总得把字段类型设置为utf8之类类的吧。
python 爬虫学习之路的更多相关文章
- python爬虫学习之路-遇错笔记-1
当在运行爬虫时同时开启了Fidder解析工具时(此爬虫并不是用于爬取手机端那内容,而是爬去电脑访问的网页时),访问目标站点会遇到以下错误: File "C:\Users\litao\AppD ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
随机推荐
- vue组件-子组件向父组件传递数据-自定义事件
自定义事件 我们知道,父组件是使用 props 传递数据给子组件,但如果子组件要把数据传递回去,应该怎样做?那就是自定义事件!
- Netty入门(三)构成部分
该节主要讲解 Netty 的构成部分. 一.Channel 它代表一个用于连接到实体如硬件设备.文件.网络套接字或程序组件,能够执行一个或多个不同的 I/O 操作的开放连接.可以比作传入和传出数据的传 ...
- UPF Usage
在 multi-voltage design 中,当涉及到多个power supply 时,需要 upf 文件来描述power细节,现将 upf 中的基本概念和使用方法记录如下: upf 中的基本概念 ...
- C++之数据类型
C++语言是广泛使用的程序设计语言之一,因其特有的优势在计算机应用领域占有重要一席. C++中的数据类型 C++中的数据类型分为两大类:基本数据类型和非基本数据类型,如图1.1所示. 图1.1 C++ ...
- haproxy [WARNING] 312/111530 (17395) : config : 'option forwardfor' ignored for frontend 'harbor_login' as it requires HTTP mode.
1.经过调查, 2down voteaccepted x-forwarded-for is an HTTP header field, so has nothing to do with the tr ...
- vxlan 简单理解 vs calico 网络模型
1.vxlan(virtual Extensible LAN)虚拟可扩展局域网,是一种overlay的网络技术,使用MAC in UDP的方法进 行封装,共50字节的封装报文头. 2.VTEP为虚拟机 ...
- Taints和Tolerations -- 污点- 容忍
1.taint 定义在node上,排斥pod 2.toleration定义在pod中,容忍pod 3.可以在命令行为Node节点添加Taints: kubectl taint nodes node1 ...
- SonarQube-Centos环境设置为系统服务
1.准备工作 官方文档:https://docs.sonarqube.org/latest/setup/operate-server/ 2.配置 /sonar.sh /usr/bin/sonar cd ...
- Python3入门(八)——面向对象OOP
一.概述 老生常谈了,万物皆对象.Python作为一门面向对象的语言,也不例外 直接看一个简单的类定义和实例化类的示例: class Student: pass stu = Student() // ...
- 利用Cydia Substrate进行Android HOOK
Cydia Substrate是一个代码修改平台.它可以修改任何主进程的代码,不管是用Java还是C/C++(native代码)编写的.而Xposed只支持HOOK app_process中的java ...