Big Data(七)MapReduce计算框架
二、计算向数据移动如何实现?
Hadoop1.x(已经淘汰):
hdfs暴露数据的位置
1)资源管理
2)任务调度
角色:JobTracker&TaskTracker
JobTracker: 资源管理、任务调度(主)
TaskTracker:任务管理、资源汇报(从)
Client:
1.会根据每次计算数据,咨询NN的元数据(block)。算:split 得到一个切片的清单 map的数量就有了
2.split是逻辑的,block是物理的,block身上有(offset,locatios),split和block是有映射 关系的。
结果:split包含偏移量,以及split对应的map任务应该移动到哪些节点(locations)
可以支持计算向数据移动了~!
生成计算程序未来运行时的文件
3.未来的移动应该相对可靠
cli会将jar,split清单,配置xml,上传到hdfs的目录中(上传的数据,副本数为10)
4.cli会调用JobTracker,通知要启动一个计算程序了,并且告知文件都放在了hdfs的哪个地方
JobTracker收到启动程序后:
1.从hdfs中取回【split清单】 2.根据自己收到的TT汇报的资源,最终确定每个split对应的map应该去到哪一个节点 3.未来TT再心跳的时候会取回分配自己的任务信息
TaskTracker
1.在心跳取回任务后 2.从hdfs下载jar,xml到本机 3.最终启动任务描述中的Map/Reduce Task(最终,代码在某个节点被启动,是通过cli上传,TT下载)
问题:
JobTracker3个问题:
1.单点故障
2.压力过大
3.集成了资源管理和任务调度,两者耦合
弊端:未来新的计算框架不能复用资源管理
1.重复造轮子
2.因为各自实现资源管理,因为他们不熟在同一批硬件上,因为隔离,所以不能感知
所以造成资源争抢
思路:(因果关系导向学习)
计算向数据移动 哪些节点可以去? 确定了节点对方怎么知道,一个失败了应该在什么节点重试 来个JobTracker搞定了2件事。但是,后来,问题暴露了
Hadoop2.x yarn的出现
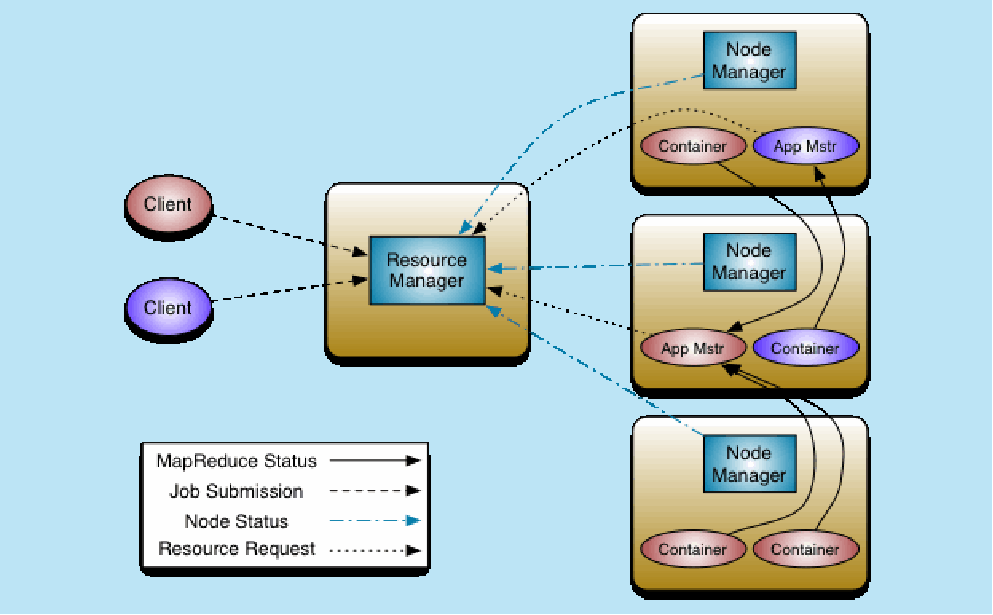
yarn架构图
查看架构图的方法:
1.确定实主从架构还是无主架构
2.查看如何调度进程
Hadoop2.x yarn:
模型:
container 容器 不是docker
虚的
对象:属性:cpu,mem,io量
物理的:JVM->操作系统进程(1,NN会有线程监控container资源情况,超额,NM直接kill掉
1.NM会有线程监控container资源情况,超额,NM直接kill掉
2.cgroup内核级技术:在启动jvm进程,由kernel约束死
架构: 架构/框架
ResourceManger 主
负责整体资源的管理
NodeManager 从
向RS汇报心跳,提交自己的资源情况
MR运行 MapReduce on yarn
1.MR-cli(切片清单/配置/jar/上传到HDFS)
访问RM中申请AppMaster
2.RM选择一台不忙的节点通知NM启动一个Container,在里面反射一个MRAppMaster
3.启动MRMaster,从hdfs下载切片清单,向RM申请资源
4.由RM根据自己掌握的资源情况得到一个确定清单,通知NM来启动container
5.container启动后会反向注册到已经启动的MRAppMaster进程
6.MRAppMaster(曾经的JobTracker阉割版不带资源管理)最终将任务Task发送container(消息)
7.container会反射相应的Task类作为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
结论:
问题:
1.单点故障(曾经是全局的,JT挂了,整个计算层没有了调度)
yarn:每一个APP由一个自己的AppMaster调度(计算 程序级别)、
2.压力过大
yarn中每个计算程序自由AppMaster,每个AppMaster只负责自己计算程序的任务调度,轻量了
AppMaster在不同节点中启动的,默认有了负载的光环
3.继集成了【资源管理和任务调度】,两者耦合
因为Yarn只是资源管理,不负责具体的任务调度
是公立的,只要计算框架继承yarn的AppMaster,大家都可以使用一个统一视图的资源层!!
总结感悟:
从1.x到2.x
JT,TT是MR的常服务
2.x之后没有了这些服务
相对的:MR的cli,调度,任务,这些都是临时服务了。
Big Data(七)MapReduce计算框架的更多相关文章
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- MR 01 - MapReduce 计算框架入门
目录 1 - 什么是 MapReduce 2 - MapReduce 的设计思想 2.1 如何海量数据:分而治之 2.2 方便开发使用:隐藏系统层细节 2.3 构建抽象模型:Map 和 Reduce ...
- Big Data(七)MapReduce计算框架(PPT截图)
一.为什么叫MapReduce? Map是以一条记录为单位映射 Reduce是分组计算
- MapReduce计算框架的核心编程思想
@ 目录 概念 MapReduce中常用的组件 概念 Job(作业) : 一个MapReduce程序称为一个Job. MRAppMaster(MR任务的主节点): 一个Job在运行时,会先启动一个进程 ...
- mapreduce计算框架
一. MapReduce执行过程 分片: (1)对输入文件进行逻辑分片,划分split(split大小等于hdfs的block大小) (2)每个split分片文件会发往不同的Mapper节点进行分散处 ...
- Hadoop中MapReduce计算框架以及HDFS可以干点啥
我准备学习用hadoop来实现下面的过程: 词频统计 存储海量的视频数据 倒排索引 数据去重 数据排序 聚类分析 ============= 先写这么多
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
随机推荐
- deepClone deepCompare
一.深度复制 // 深度复制 function deepClone(datas) { if (typeof datas !== 'object' || datas === null) return d ...
- Emacs常用命令快速参考
原文地址 Emacs常用命令的汇总,来自Emacs参考卡片 注意:以下命令中标注的按键,大写的C代表Control,在键盘上通常是Ctrl键,而M代表Meta,在键盘上通常是Alt键,S则代表Shif ...
- windows7解决无法桌面远程
正常设置远程连接一般需要下面几个设置: 1).查询并记录远程计算机的IP,开始——运行——输入cmd,回车,在cmd界面输入ipconfig/all 回车查看IPv4地址 2).被远程的电脑设置一个用 ...
- python 元组和数组
参考:https://stackoverflow.com/questions/1708510/list-vs-tuple-when-to-use-each tuple(元组):不可变,不能添加.删除. ...
- jdbc简单连接oracle数据库
package com.shangsheng; import java.sql.*; public class UserOracle { public static void main(String[ ...
- W3C验证工具
HTML验证工具:http://validator.w3.org/ CSS验证工具:http://jigsaw.w3.org/css-validator/
- 深入理解Istio核心组件之Pilot
Istio作为当前服务网格(Service Mesh)领域的事实标准,流量治理(Traffic Management)是其最为基础也最为重要的功能.本文将结合源码对Istio流量治理的实现主体——组件 ...
- 【HANA系列】SAP HANA SQL/MDX及TCP/IP端口介绍
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA SQL/MDX ...
- LeetCode.933-最近通话次数(Number of Recent Calls)
这是悦乐书的第357次更新,第384篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第219题(顺位题号是933).写一个类RecentCounter来计算最近的请求. 它 ...
- JSON中文处理类实例
$array = array( 'Name'=>'络恩', 'Age'=>24); $post=my_json_encode($array); // 这个函数是判断版本,如果是搞版本的则直 ...