CNN基础二:使用预训练网络提取图像特征
上一节中,我们采用了一个自定义的网络结构,从头开始训练猫狗大战分类器,最终在使用图像增强的方式下得到了82%的验证准确率。但是,想要将深度学习应用于小型图像数据集,通常不会贸然采用复杂网络并且从头开始训练(training from scratch),因为训练代价高,且很难避免过拟合问题。相对的,通常会采用一种更高效的方法——使用预训练网络。
预训练网络的使用通常有两种方式,一种是利用预训练网络简单提取图像的特征,之后可能会利用这些特征进行其他操作(比如和文本信息结合以用于image caption,或者简单的进行分类);另一种是对预训练的网络进行裁剪和微调,以适应自己的任务。
第一种方式训练代价极低,因为它就是简单提取个特征,不涉及训练;缺点是保存提取出来的特征需要占用一定空间,且无法使用图像增强(而图像增强对于防止小型数据集的过拟合非常重要)。第二种方式可以使用图像增强,但训练代价也会大幅增加。(当然相对于从头训练来说,使用预训练网络的训练代价肯定要低得多。)
这一节中我们以VGG16提取图像特征为例,展示第一种使用方式。该案例接着上一个例子,使用同样的数据集,利用keras中自带的VGG16模型提取图像特征,然后以这些图像特征为输入,训练一个小型分类器。
import numpy as np
from keras.applications.vgg16 import VGG16
#实例化一个VGG16卷积基
#输入维度根据需要自行指定,这里仍然采用上一个例子的维度,卷积基的输出是(None,4,4,512)
conv_base = VGG16(include_top=False, input_shape=(150,150,3))
#conv_base.summary()
###############单纯用VGG16卷积基直接提取特征,不使用图像增强####################
import os
from keras.preprocessing.image import ImageDataGenerator
#定义提取图像特征的函数
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
#输入:文件路径,样本个数
#返回:指定个数的样本特征,以及对应的标签
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator: #分别为(20,150,150,3) (20,)
features_batch = conv_base.predict(inputs_batch) #(20,4,4,512)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count: #读取了指定样本个数后即退出
break
return features, labels
#分别提取训练集、验证集、测试集的图像特征
train_dir = r'D:\KaggleDatasets\MyDatasets\dogs-vs-cats-small\train'
validation_dir = r'D:\KaggleDatasets\MyDatasets\dogs-vs-cats-small\validation'
test_dir = r'D:\KaggleDatasets\MyDatasets\dogs-vs-cats-small\test'
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
#将各自的图像特征展平,作为后续Dense层的输入
assert train_features.shape == (2000, 4, 4, 512)
assert validation_features.shape == (1000, 4, 4, 512)
assert test_features.shape == (1000, 4, 4, 512)
train_features = train_features.reshape(2000, 4*4*512)
validation_features = validation_features.reshape(1000, 4*4*512)
test_features = test_features.reshape(1000, 4*4*512)
###################定义并训练一个小型分类器#########################
from keras.models import Model
from keras.layers import Input, Dense, Dropout
input = Input(shape=(4*4*512,))
X = Dense(256, activation='relu')(input)
X = Dropout(0.5)(X)
X = Dense(1, activation='sigmoid')(X)
model = Model(inputs=input, outputs=X)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
H = model.fit(train_features, train_labels,
validation_data=(validation_features, validation_labels),
epochs=30, batch_size=64, verbose=1)
#######################训练结果可视化############################
import matplotlib.pyplot as plt
acc = H.history['acc']
val_acc = H.history['val_acc']
loss = H.history['loss']
val_loss = H.history['val_loss']
epoch = range(1, len(loss) + 1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
fig.subplots_adjust(wspace=0.2)
ax[0].plot(epoch, loss, label='Train loss') #注意不要写成labels
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epoch')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epoch')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
plt.show()
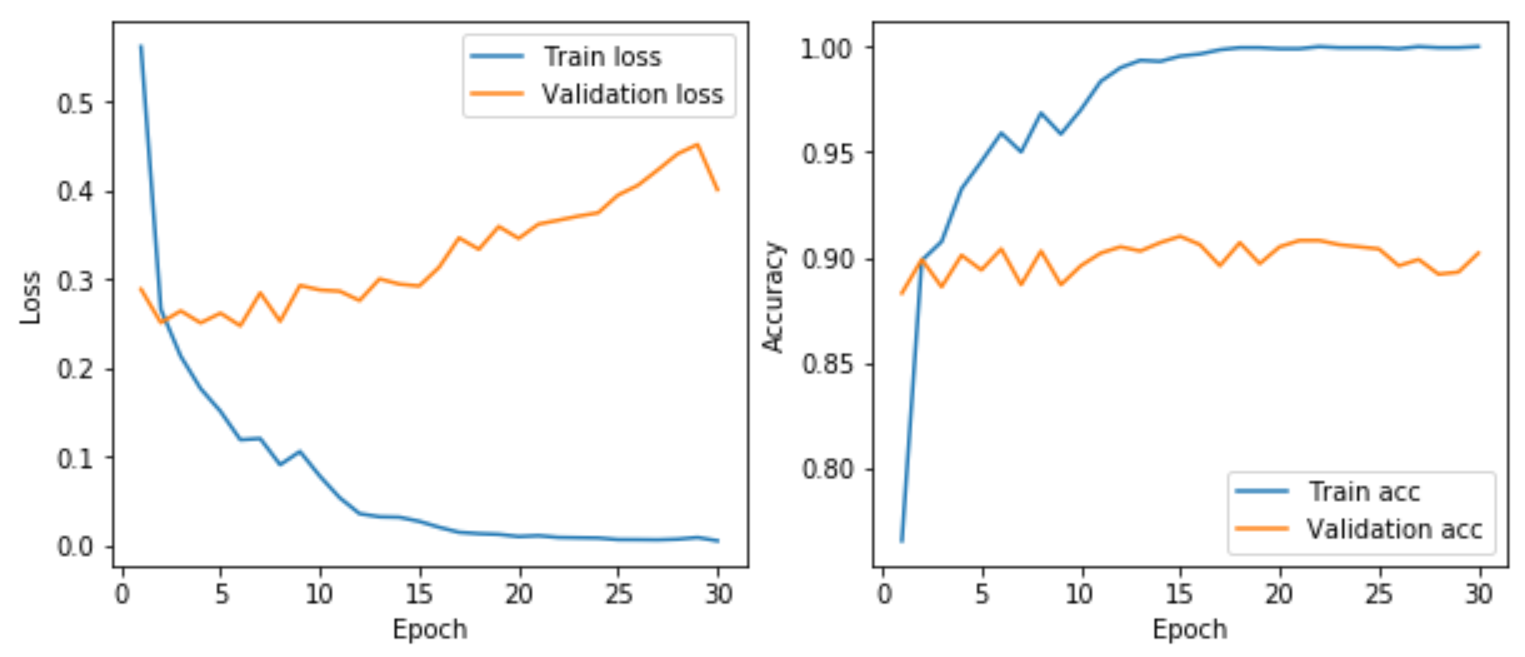
训练结果如下所示。可以看出,相对于上一个从头开始训练的猫狗分类任务,很轻松的就把验证集准确率由82%提高到90%左右,更重要的是,现在还没有使用重量级武器——图像增强。下一节,我们会使用第二种更常用更高效的方式——模型微调。
CNN基础二:使用预训练网络提取图像特征的更多相关文章
- AI:拿来主义——预训练网络(二)
上一篇文章我们聊的是使用预训练网络中的一种方法,特征提取,今天我们讨论另外一种方法,微调模型,这也是迁移学习的一种方法. 微调模型 为什么需要微调模型?我们猜测和之前的实验,我们有这样的共识,数据量越 ...
- 原来CNN是这样提取图像特征的。。。
对于即将到来的人工智能时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的领域,会不会感觉马上就out了?作为机器学习的一个分支,深度学习同样需要计算机获得强大的学 ...
- VGG16提取图像特征 (torch7)
VGG16提取图像特征 (torch7) VGG16 loadcaffe torch7 下载pretrained model,保存到当前目录下 th> caffemodel_url = 'htt ...
- CNN基础三:预训练模型的微调
上一节中,我们利用了预训练的VGG网络卷积基,来简单的提取了图像的特征,并用这些特征作为输入,训练了一个小分类器. 这种方法好处在于简单粗暴,特征提取部分的卷积基不需要训练.但缺点在于,一是别人的模型 ...
- 深度学习tensorflow实战笔记 用预训练好的VGG-16模型提取图像特征
1.首先就要下载模型结构 首先要做的就是下载训练好的模型结构和预训练好的模型,结构地址是:点击打开链接 模型结构如下: 文件test_vgg16.py可以用于提取特征.其中vgg16.npy是需要单独 ...
- AI:拿来主义——预训练网络(一)
我们已经训练过几个神经网络了,识别手写数字,房价预测或者是区分猫和狗,那随之而来就有一个问题,这些训练出的网络怎么用,每个问题我都需要重新去训练网络吗?因为程序员都不太喜欢做重复的事情,因此答案肯定是 ...
- Pytorch如何用预训练模型提取图像特征
方法很简单,你只需要将模型最后的全连接层改成Dropout即可. import torch from torchvision import models # load data x, y = get_ ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
随机推荐
- B-Tree, B+Tree, B*树介绍
[数据结构]B-Tree, B+Tree, B*树介绍 转 [数据结构]B-Tree, B+Tree, B*树介绍 [摘要] 最近在看Mysql的存储引擎中索引的优化,神马是索引,支持啥索引.全是 ...
- 全国5A级旅游景区已达250家
至目前,全国5A级旅游景区已达250家,快来数数你去过多少? 全国5A级旅游景区 西藏(+) 拉萨市大昭寺.拉萨布达拉宫景区.日喀则扎什伦布寺景区.林芝巴松措景区 新增1:日喀则扎什伦布寺景区 扎什伦 ...
- laravel框架手动删除迁移文件后再次创建报错
手动删除laravel框架数据表迁移文件后再次创建报错 如下图: 执行创建操作之后会在autoload_static.php及autoload_classmap.php这两个文件中添加迁移文件的目录. ...
- 转载:Linux下启动和关闭Weblogic(管理服务器+被管服务器)
转载自:http://www.cnblogs.com/nick-huang/p/3834134.html 感谢! Weblogic的管理服务器和被管服务器的启动.关闭,偶尔会用到,却又不常用,导致需 ...
- spring boot 尚桂谷学习笔记05 ---Web
------web 开发登录功能------ 修改login.html文件:注意加粗部分为 msg 字符串不为空时候 才进行显示 <!DOCTYPE html> <!-- saved ...
- C++怎样通过嵌入汇编写一个函数
参考:http://msdn.microsoft.com/en-us/library/h5w10wxs.aspx 普通的函数,Compiler会自动生成prologue和epilogue,但是通过在函 ...
- PAT 2019-3 7-2 Anniversary
Description: Zhejiang University is about to celebrate her 122th anniversary in 2019. To prepare for ...
- 迪杰斯特拉算法(Dijkstra)
模板一: 时间复杂度O(n2) int dijkstra(int s,int m) //s为起点,m为终点 { memset(dist,,sizeof(dist)); //初始化,dist数组用来储存 ...
- maven(二),Linux安装maven3.5.3及配置
Linux系统,ubuntu-16.04.4,安装maven3.5.3 一.创建文件夹 注意Linux用户,这个如果不是root用户,命令前面需要加:sudo //创建一个目录 mkdir /usr/ ...
- java File I/O
File类: 常用方法: boolean exists( ):判断文件或目录是否存在 boolean isFile( ):判断是否是文件 boolean isDirectory( ):判断是否是目录 ...