knn算法手写字识别案例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
from sklearn.neighbors import KNeighborsClassifier def build_data(dir_name):
"""
构建数据
:param dir_name: 指定传入文件夹名称
:return: 构建好的数据
"""
# 获取文件名列表
file_name_list = os.listdir(dir_name + "/")
print("获取到的文件名列表:\n", file_name_list)
# 进行读取文件 data = np.zeros(shape=(len(file_name_list), 1025)) # 循环读取文件
for file_index, file_name in enumerate(file_name_list):
# file_index 文本名称所对应的下标
# file_name 文本名称
# 加载数据
file_data = np.loadtxt(dir_name + "/" + file_name, dtype=np.str) # 构建一个列表
arr = []
for file_data_index, file_data_content in enumerate(file_data):
# print(file_data_content)
# print("*"*80)
# 将 每一个元素转化为一个int 类型的列表
arr_sigle_list = [int(tmp) for tmp in file_data_content]
# print(arr)
# 把每个元素添加到列表中
arr.append(arr_sigle_list) # print(arr)
# 将一个样本转化为数组
arr_single_sample = np.array(arr)
# print(arr_single_sample)
# np.savetxt("./hh.txt",arr_single_sample,fmt="%d")
# 将二维数组展开为一维---特征值
arr_single_sample = arr_single_sample.ravel()
# print(arr_single_sample)
# 目标值
label = int(file_name[0])
# print(res)
# print(arr_single_sample.shape)
# 将一个 完整的样本拼接起来,组成完整的样本
arr_single_sample = np.concatenate((arr_single_sample, [label]), axis=0) # print(arr_single_sample)
# print(arr_single_sample.shape) data[file_index, :] = arr_single_sample # print(data)
return data def save_data(file_name, data):
"""
保存文件
:param file_name: 保存的文件名称
:param data: 保存的数组
:return: None
"""
if not os.path.exists("./data/"):
os.makedirs("./data/") np.save("./data/" + file_name, data) def load_data(file_name):
"""
加载数据
:param file_name:文件路径+ 名称
:return: 数据
"""
data = np.load(file_name, allow_pickle=True) return data def distance(v1, v2):
"""
计算距离
:param v1: 点1
:param v2: 点2
:return: 距离
"""
dist = np.sqrt(np.sum(np.power((v1 - v2), 2))) return dist def knn_owns(train, test, k):
"""
自定knn算法实现手写字识别
:param train: 训练集数据
:param test: 测试集数据
:param k: 邻居个数
:return: 准确率
"""
# 设置计数器
true_num = 0
# 获取训练集的特征值 目标值
train_x = train.iloc[:, :-1].values
train_y = train.iloc[:, -1].values
# 获取测试集的特征值 目标值
test_x = test.iloc[:, :-1].values
test_y = test.iloc[:, -1].values
# 计算每一个测试样本特征与每一个训练样本特征的距离
for i in range(test.shape[0]): # 循环每一个 测试样本
for j in range(train.shape[0]):
# 计算距离
dist = distance(test_x[i,:],train_x[j,:])
train.loc[j,'dist'] = dist res = train.sort_values(by='dist') mode = res.iloc[:,-2][:k].mode()[0] if mode == test_y[i]:
true_num += 1
# print(test_y) score = true_num / test.shape[0] print(score) return score # train_data = build_data("./trainingDigits")
# test_data = build_data("./testDigits")
#
# save_data("train_data",train_data)
# save_data("test_data",test_data) # 加载数据
train = load_data("./data/train_data.npy")
test = load_data("./data/test_data.npy") train = pd.DataFrame(train)
test = pd.DataFrame(test) # print(train)
# print("*"*80)
# print(test)
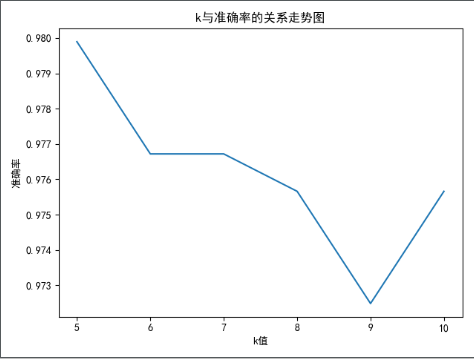
k_list = [5,6,7,8,9,10]
score_list = []
for k in k_list:
# score = knn_owns(train, test, k)
# score_list.append(score)
knn = KNeighborsClassifier(n_neighbors=k)
#训练数据
knn.fit(train.iloc[:,:-1].values,train.iloc[:,-1].values)
# 进行预测
y_predict = knn.predict(test.iloc[:,:-1].values) # 可以获取准确率
score = knn.score(test.iloc[:,:-1].values,test.iloc[:,-1].values) score_list.append(score)
print(score_list) #进行结果可视化
# 1、创建画布
plt.figure()
# 默认不支持中文,需要配置RC 参数
plt.rcParams['font.sans-serif']='SimHei'
# 设置字体之后不支持负号,需要去设置RC参数更改编码
plt.rcParams['axes.unicode_minus']=False
# 2、绘图
x = np.array(k_list)
y = np.array(score_list) plt.plot(x,y) plt.title("k与准确率的关系走势图")
plt.xlabel("k值")
plt.ylabel("准确率")
plt.savefig("./k值对准确率的影响.png")
# 3、展示 plt.show()
knn算法手写字识别案例的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 用TensorFlow教你手写字识别
博主原文链接:用TensorFlow教你做手写字识别(准确率94.09%) 如需转载,请备注出处及链接,谢谢. 2012 年,Alex Krizhevsky, Geoff Hinton, and Il ...
- k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别. 基本概念 k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的 ...
- 机器学习实战kNN之手写识别
kNN算法算是机器学习入门级绝佳的素材.书上是这样诠释的:“存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都有标签,即我们知道样本集中每一条数据与所属分类的对应关系.输入没有标签的新数据 ...
- python 实现 KNN 分类器——手写识别
1 算法概述 1.1 优劣 优点:进度高,对异常值不敏感,无数据输入假定 缺点:计算复杂度高,空间复杂度高 应用:主要用于文本分类,相似推荐 适用数据范围:数值型和标称型 1.2 算法伪代码 (1)计 ...
- tensorflow卷积神经网络与手写字识别
1.知识点 """ 基础知识: 1.神经网络(neural networks)的基本组成包括输入层.隐藏层.输出层.而卷积神经网络的特点在于隐藏层分为卷积层和池化层(po ...
- k-近邻算法-手写识别系统
手写数字是32x32的黑白图像.为了能使用KNN分类器,我们需要把32x32的二进制图像转换为1x1024 1. 将图像转化为向量 from numpy import * # 导入科学计算包numpy ...
- tensorflow神经网络与单层手写字识别
1.知识点 """ 1.基础知识: 1.神经网络结构:1.输入层 2.隐含层 3.全连接层(类别个数=全连接层神经元个数)+softmax函数 4.输出层 2.逻辑回归: ...
- 基于PyTorch实现MNIST手写字识别
本篇不涉及模型原理,只是分享下代码.想要了解模型原理的可以去看网上很多大牛的博客. 目前代码实现了CNN和LSTM两个网络,整个代码分为四部分: Config:项目中涉及的参数: CNN:卷积神经网络 ...
随机推荐
- 360CTF Re wp
这比赛唯一的一道Re
- iOS App中 使用 OpenSSL 库
转自:http://blog.csdn.net/kmyhy/article/details/6534067 在你的 iOS App中 使用 OpenSSL 库 ——译自x2on的“Tutorial: ...
- 一条sql引发的“血案”
前几天有一个项目要上线,需要对表的一个字段进行扩充,项目经理让我准备脚本,于是我准备了如下的脚本: )); )); )); 结果上线的时候,ord_log1和ord_log2表中有30万数据,在执行的 ...
- 88-基于FMC接口的2路CameraLink Base输入子卡模块
基于FMC接口的2路CameraLink Base输入子卡模块 1.板卡概述 FMC连接器是一种高速多pin的互连器件,广泛应用于板卡对接的设备中,特别是在xilinx公司的所有开发板中都使用.该Ca ...
- u盘被占用,无法弹出解决办法
方法1.把鼠标放到电脑屏幕最底部的中央,点击右键,点击 任务管理器 方法2.按:CTRL+ALT+ENTER(回车) 打开任务管理器,点击 进入性能后点击下方的:资源管理器 回到桌面,查看 ...
- Ubuntu系统安装两个tomcat
1:创建两个tomcat 2:在/etc下有个 profile 然后vim 编辑它 在 最下面加上这句话.这是两个tomcat的路径 #开启多个tomcat export CATALINA_BASE ...
- swan.onPageNotFound
解释: 监听小程序要打开的页面不存在事件.该事件与 App.onPageNotFound 的回调时机一致. 方法参数: Function callback小程序要打开的页面不存在的事件回调函数. ca ...
- java扫描仪上传文件
问题: 项目中有一个功能,原来是用ckfinder做的,可以选择本地图片上传至服务器,然后将服务器的图片显示在浏览器中,并可以将图片地址保存到数据库:现在客户觉得麻烦,提出连接扫描仪扫描后直接上传至服 ...
- ubuntu18.04-安装最新cmake
https://www.linuxidc.com/Linux/2018-09/154165.htm
- [USACO10MAR]伟大的奶牛聚集Great Cow Gat… ($dfs$,树的遍历)
题目链接 Solution 辣鸡题...因为一个函数名看了我贼久. 思路很简单,可以先随便指定一个根,然后考虑换根的变化. 每一次把根从 \(x\) 换成 \(x\) 的一个子节点 \(y\),记录一 ...