Solr单机环境搭建及部署
一、定义
官网的定义:
Solr是基于Lucene构建的流行,快速,开放源代码的企业搜索平台。它具有高度的可靠性,可伸缩性和容错能力,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配置等。 Solr支持许多世界上最大的互联网站点的搜索和导航功能。
简单的理解solr就是一款搜索框架,通常用实现查询功能,比如电商网站的商品检索。
二、环境搭建
本文基于以下开源组件版本搭建,约定下载后组件和解压缩的文件都放置在/opt目录下:
solr-8.2.0
apache-tomcat-8.5.47
首先下载solr-8.2.0.tgz,可以使用wget命令:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/8.2.0/solr-8.2.0.tgz
解压缩:
tar -zxvf solr-8.2.0.tgz -C .
解压后,/opt目录下会多一个solr-8.2.0目录
下载apache-tomcat-8.5.47:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.47/bin/apache-tomcat-8.5.47.tar.gz
解压缩:
tar -zxvf apache-tomcat-8.5.47.tar.gz
为了将solr部署到tomcat服务器,不使用solr自带的jetty,首先在/opt目录下创建一个目录用于部署solr服务,名称无限制,这里取名solr了。
mkdir solr
复制一份tomcat到/opt/solr目录下,重命名为tomcat8
cp -r apache-tomcat-8.5.47 solr/tomcat8
solr本质是一个web服务,我们将它复制到tomcat8下:
cp -r solr-8.2.0/server/solr-webapp/webapp solr/tomcat8/webapps/solr
复制solr-8.2.0/server/lib/ext下的部分jar到solr目录中,为了简便可以完全复制所有的,然后忽略掉disruptor-3.4.2.jar
cp solr-8.2.0/server/lib/ext/* solr/tomcat8/webapps/solr/WEB-INF/lib/
复制solr-8.2.0/server/lib下以metrics开头的jar到solr目录:
cp solr-8.2.0/server/lib/metrics* solr/tomcat8/webapps/solr/WEB-INF/lib/
上面这两项注意是复制到solr服务的lib目录下,不是复制到tomcat8/lib下。
复制solr-8.2.0/server/resources下的log4j*.xml文件到solr
首先在solr创建classes目录:
mkdir solr/tomcat8/webapps/solr/WEB-INF/classes
复制日志配置文件:
cp solr-8.2.0/server/resources/log4j2*.xml solr/tomcat8/webapps/solr/WEB-INF/classes/
将solr-8.2.0/server/solr目录复制到solr/目录下,并重命名为solrhome:
cp -r solr-8.2.0/server/solr solr/solrhome
修改日志路径
vim solr/tomcat8/webapps/solr/WEB-INF/classes/log4j2.xml
指定fileName和filePattern的路径:
<RollingRandomAccessFile
name="MainLogFile"
fileName="/opt/solr/solrhome/log/solr.log"
filePattern="/opt/solr/solrhome/log/solr.log.%i" >
<PatternLayout>
....
关联solr及solrhome
修改solr里的web.xml文件
vim solr/tomcat8/webapps/solr/WEB-INF/web.xml
web.xml中<web-app></web-app>标签内添加如下配置,指定sorlhome路径
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/opt/solr/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
注释掉下方的下列配置:
<!--
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
最后启动tomcat,访问服务器的solr服务:
sh solr/tomcat8/bin/start.sh
访问地址:
localhost:8080/solr/index.html
三、配置IK分词器
首先从IK分词器下载与solr版本匹配的jar包,并放置在solr服务的lib目录下,
cp ik-analyzer-8.2.0.jar solr/tomcat8/webapps/solr/WEB-INF/lib/
在solr/solrhome/下创建目录test_core,拷贝配置文件到test_core中:
cp -r solr/solrhome/configsets/sample_techproducts_configs/conf/ solr/solrhome/test_core/
修改conf中的solr.xml文件,修改jar路径:
<lib dir="${solr.install.dir:../}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-ltr-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-velocity-\d.*\.jar" />
修改managed-schema文件,添加ik分词器配置:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
重启solr服务,打开管理界面,添加test_core:
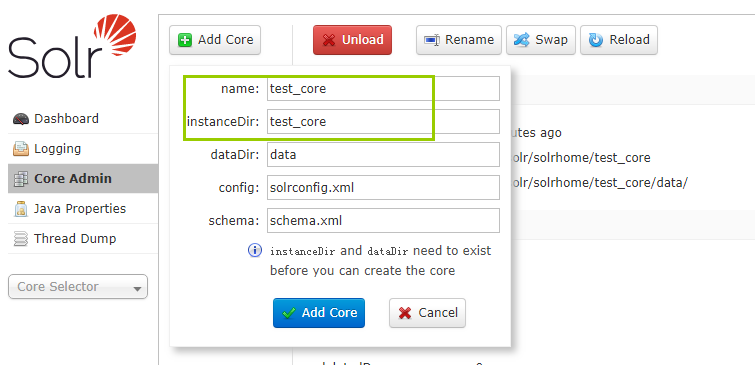
打开管理界面,分词示例:

Solr单机环境搭建及部署的更多相关文章
- Kafka 0.7.2 单机环境搭建
Kafka 0.7.2 单机环境搭建当下载完Kafka后,进行解压,其目录结构如下: bin config contrib core DISCLAIMER examples lib lib_manag ...
- Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建
Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建 由于公司里的Solr调试都是用远程jpda进行的,但是家里只有一台电脑所以不能jpda进行调试,这是因为jpda的端口冲突.所以 ...
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- 2-1 RHEL6.5 环境搭建与部署
第二部分:Linux常见服务管理 2-1 RHEL6.5 环境搭建与部署 第二部分主要讲解的是开源服务搭建 学习方法与注意事项: 1. 端正态度,开始学习 2. 认真完成作业和实验(并详细记录) 3. ...
- kafka单机环境搭建及其基本使用
最近在搞kettle整合kafka producer插件,于是自己搭建了一套单机的kafka环境,以便用于测试.现整理如下的笔记,发上来和大家分享.后续还会有kafka的研究笔记,依然会与大家分享! ...
- solr单机环境配置并包含外部单机zookeeper
首先和之前一样下载solr-5.3.1.tgz,然后执行下面命令释放文件并放置在/usr/目录下: $ .tgz $ /usr/ $ cd /usr/solr- 这个时候先不用启动solr,因为单机模 ...
- Mac系统STF自动化环境搭建及部署踩坑记录
因为公司需要寻找一个免root的自动化测试方案,所以以前做的老方案需要被替代.一阵搜寻找到了这个框架,但是部署起来很是折腾,搞了一下午终于搞定,顺便记录一下过程,有需要的自取. 转载请注明出处:htt ...
- HBase单机环境搭建
在搭建HBase单机环境之前,首先你要保证你已经搭建好Java环境: $ java -version java version "1.8.0_51" Java(TM) SE Run ...
随机推荐
- JS案例经验1
一 可以通过设置在一个div中的多个div的定位属性为absolute,从而使得这几个元素重叠.他们都脱离了标准流. 二 对于absolute的left和right属性,当left和right同时出现 ...
- ubuntu 配置 tftp 服务器
一. 安装 tftp 1.1. 安装 tftp 所需的软件. a. 安装 tftp-hpa,tftpd-hpa,前者是客户端,后者是服务程序, 在终端下输入 sudo apt-get install ...
- 题解 AT1877 【回文分割】
题意:给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串. 返回 s 所有可能的分割方案. 示例: 输入:aab 输出:3 解释:aba 思路: 记录字符串中每个字符出现的次数si 如果 ...
- MyBatis一个对多个主键(索引)生成实体类的处理
原数据库表: 生成实体类,多出了一个xxKey.java
- vue 圆形进度条组件解析
项目简介 本组件是vue下的圆形进度条动画组件 自由可定制,几乎全部参数均可设置 源码简单清晰 面向人群 急于使用vue圆形进度条动画组件的同学.直接下载文件,拷贝代码即可运行. 喜欢看源码,希望了解 ...
- python中session的使用
- 剑指offer-旋转数组的最小数字-数组-python
题目描述 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转.输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素.例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转 ...
- String.IsNullOrEmpty官方示例
// This example demonstrates the String.IsNullOrEmpty() method using System; class Sample { public s ...
- mysql分组查询及其测试用例
语法: select 查询列表 from 表 [where 筛选条件] group by 分组的字段 [order by 排序的字段]; 特点: 1.和分组函数一同查询的字段必须是group by后出 ...
- 对数据集做标准化处理的几种方法——基于R语言
数据集——iris(R语言自带鸢尾花包) 一.scale函数 scale函数默认的是对制定数据做均值为0,标准差为1的标准化.它的两个参数center和scale: 1)center和scale默认为 ...