B-/B+树 MySQL索引结构
索引
索引的简介
简单来说,索引是一种数据结构 其目的在于提高查询效率 可以简单理解为“排好序的快速查找结构”
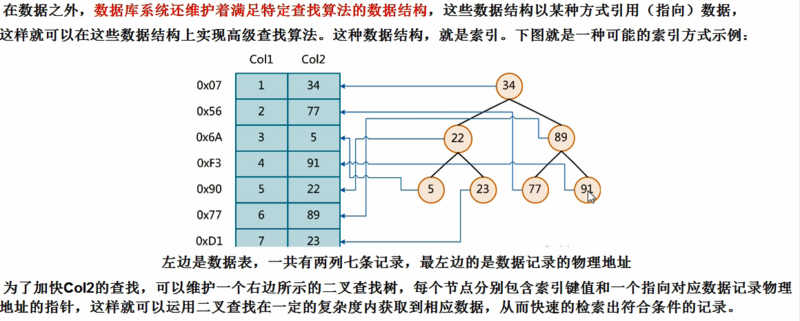
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在中磁盘上
我们一般所说的索引,如果没有特殊说明的话,就是指B+树结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引。 一般java开发知道这些基本够用了
索引的优势
类似大学图书馆建数目索引,提高数据检索效率,降低数据库的io成本
通过索引对数据进行排序,降低数据排序成本,降低了cpu的
劣势
索引实际上也是一张表,保存了主键和索引字段,并指向实体表的记录,所以索引列也要空间
虽然索引大大提高了查询速度,但是会降低更新表的速度,如对表进行insert,update和delete。因为更新表时,mysql不仅要保存数据,还要保存一下索引文件每次添加了索引列的字段
索引只是提高效率的一个因素,如果你的mysql有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
索引的使用
单值索引
唯一索引
复合索引
基本语法
show index from TableName;(查看表的索引)
eg:show index from city;
create [unique] index indexname(索引名称) on TableName(字段名);
eg:create index idx_city_name on city(cname);
eg:create index idx_city_idnamepid on city(id,name,pid);
drop index indexname on TableName;
eg:drop index idx_city_name on city;
使用ALERT命令
ALERT TABLE tbl_name ADD PRIMARY KEY(column_list);该语句添加一个主键,这意味着索引值必须是唯一的,且不能为null;
ALERT TABLE tbl_name ADD UNIQUE index_name(column_list);这条语句创建索引的值必须是唯一的(除了null外,null可能会出现多次)
ALERT TABLE tbl_name ADD INDEX index_name(colmun_list);添加普通索引,索引值可出现多次
ALERT TABLE tbl_name ADD FULLTEXT index_name(column_list);该语句指定了索引为FULLTEXt,用于全文索引
mysql索引结构
BTree索引
Hash索引
full-text索引
R-Tree索引
检索原理

哪些情况下需要创建索引
a.主键自动建立唯一索引
b.频繁作为查询条件的字段应该创建索引
c.查询中与其它表关联的字段,外键关系建立索引
d.频繁更新的字段不适合建立索引(因为每次更新不仅仅是更新数据还要更新索引,加重io负担)
e.where条件里用不到的字段不创建索引
f.单键/组合索引的选择问题(在高并发下倾向创建组合索引)
g.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
h.查询中统计或分组的字段
哪些情况下不需要创建索引
a.表记录太少
b.经常增删改查的表(读少写多)
c.数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引,注意,如果某个数据列包含许多重复内容,为它建立索引就没有太大的实际效果
B-树
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树
它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图.

B-树有如下特点:
所有键值分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
在关键字全集内做一次查找,性能逼近二分查找;
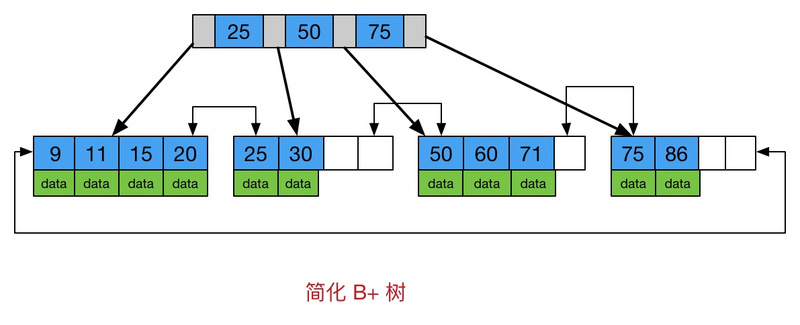
B+ 树
B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:
所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
为所有叶子结点增加了一个链指针
简化 B+树 如下图
为什么使用B-/B+ Tree
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。MySQL 是基于磁盘的数据库系统,索引往往以索引文件的形式存储的磁盘上,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
局部性原理与磁盘预读
由于磁盘的存取速度与内存之间鸿沟,为了提高效率,要尽量减少磁盘I/O.磁盘往往不是严格按需读取,而是每次都会预读,磁盘读取完需要的数据,会顺序向后读一定长度的数据放入内存。而这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用
程序运行期间所需要的数据通常比较集中
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改).linux 默认页大小为4K
B-/+Tree索引的性能分析
实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。
假设 B-Tree 的高度为 h,B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
为什么使用 B+树
B+树更适合外部存储,由于内节点无 data 域,一个结点可以存储更多的内结点,每个节点能索引的范围更大更精确,也意味着 B+树单次磁盘IO的信息量大于B-树,I/O效率更高。
Mysql是一种关系型数据库,区间访问是常见的一种情况,B+树叶节点增加的链指针,加强了区间访问性,可使用在范围区间查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
原文链接:https://segmentfault.com/a/1190000004690721
B-/B+树 MySQL索引结构的更多相关文章
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- MySQL 索引结构 hash 有序数组
MySQL 索引结构 hash 有序数组 除了最常见的树形索引结构,Hash索引也有它的独到之处. Hash算法 Hash本身是一种函数,又被称为散列函数. 它的思路很简单:将key放在数组里,用 ...
- 一天五道Java面试题----第七天(mysql索引结构,各自的优劣--------->事务的基本特性和隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1 .mysql索引结构,各自的优劣 2 .索引的设计原则 3 .mysql锁的类型有哪些 4 .mysql执行计划怎么看 ...
- Mysql索引结构及常见索引的区别
一.Mysql索引主要有两种结构:B+Tree索引和Hash索引 Hash索引 mysql中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是M ...
- MySQL索引结构--由 B-/B+树看
B-树 B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点.下图是 B-树的简化图. B-树有 ...
- mysql系列十、mysql索引结构的实现B+树/B-树原理
一.MySQL索引原理 1.索引背景 生活中随处可见索引的例子,如火车站的车次表.图书的目录等.它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的 ...
- MySQL索引结构之B+树索引(面)
首先要明白索引(index)是在存储引擎(storage engine)层面实现的,而不是server层面.不是所有的存储引擎都支持所有的索引类型.即使多个存储引擎支持某一索引类型,它们的实现和行为也 ...
- 2020-05-18:MYSQL为什么用B+树做索引结构?平时过程中怎么加的索引?
福哥答案2020-05-18:此答案来自群员:因为4.0成型那个年代,B树体系大量用于文件存储系统,甚至当年的Longhorn的winFS都是基于b树做索引,开源而且好用的也就这么个体系了.B+树的磁 ...
随机推荐
- 吴恩达深度学习:2.9逻辑回归梯度下降法(Logistic Regression Gradient descent)
1.回顾logistic回归,下式中a是逻辑回归的输出,y是样本的真值标签值 . (1)现在写出该样本的偏导数流程图.假设这个样本只有两个特征x1和x2, 为了计算z,我们需要输入参数w1.w2和b还 ...
- Qt是什么?Qt简介(非常全面)
http://c.biancheng.net/view/1792.html Qt(官方发音 [kju:t],音同 cute)是一个跨平台的 C++ 开发库,主要用来开发图形用户界面(Graphical ...
- Linux知识点拾遗-磁盘UUID
查看磁盘UUID 方法1 ls -l /dev/disk/by-uuid example: [root@dplinux ~]# ll /dev/disk/by-uuid/ total 0 lrwxrw ...
- ssh修改超时自动登出时间的方法
echo $TMOUT 查看当前服务器登出时间,如果没有输出表示不会登出 1.修改:vim ~/.bash_profile 2.设置TMOUT值 TMOUT=600 #表示10分钟之后自动登出 TMO ...
- 前端每日实战:12# 视频演示如何用纯 CSS 创作一种文字断开的交互特效
效果预览 按下右侧的"点击预览"按钮在当前页面预览,点击链接全屏预览. https://codepen.io/zhang-ou/pen/LmjNgL 可交互视频教程 此视频是可以交 ...
- Django【第7篇】:Django之ORM跨表操作(聚合查询,分组查询,F和Q查询等)
django之跨表查询及添加记录 一:创建表 书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many); ...
- MySQL--缓存的使用注意
几个参数 query_cache_type:为ON时开启,为OFF关闭,为DEMAND时则只有查询语句中有sql cache时才使用缓存 query_cache_size: 缓存的内存空间 query ...
- Debian10+OpenMediaVault(OMV)安装
前言:测试打造NAS平台,以下是步骤. 安装Debian10 注:请下载amd64,不要下载i836平台,因为OMV外挂插件不支持I836所以不建议用i836,如只使用官方插件可以无视 安装前-安装, ...
- nyoj 952 : 最大四边形 (计算几何)
题目链接 任意四边形均可看作是两个三角形拼接得到的(即使是凹四边形),故 可以O(n^2)枚举所有的线段,然后对每条线段O(n)枚举线段端点外的其他点,用来更新以此线段构成的三角形的有向面积的最大值m ...
- springboot自定义异常数据
一.源码分析 自定义异常数据之前我们先看看一下源码 上述代码意思是如果你没有提供就使用springboot提供的类 这是springboot提供的异常属性类,我们想要自 ...