103 - kube-scheduler源码分析 - 调度算法-寻找predicates和priorities

scheduler的主要逻辑是predicate和priority,前者回答哪些节点可以运行pod的问题,后者回答哪个节点更合适运行pod的问题。今天我们的任务是:从主函数出发,寻找predicates和priorities的入口!
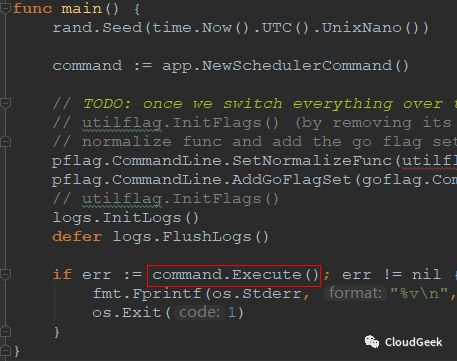
前面我们提到过Execute()其实是运行了这个Run方法,在cmd/kube-scheduler/app/server.go的337行。
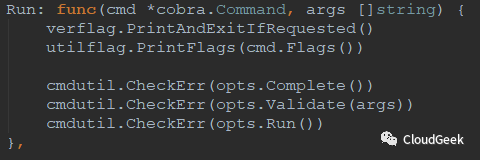
顺着opts.Run()往里跟:
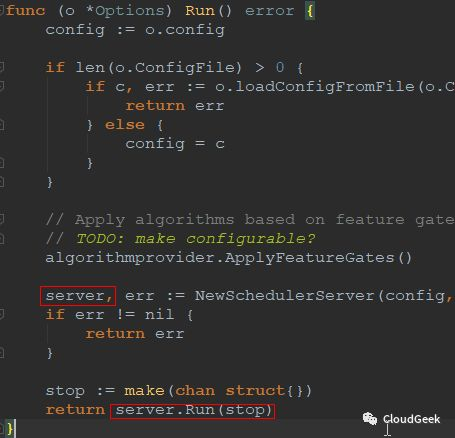
可以很清楚看到opts.Run()的逻辑,初始化一个server,然后执行server.Run()方法。这里的server类型是*SchedulerServer,这个类型的官方解释是:
SchedulerServer represents all the parameters required to start the kubernetes scheduler server. 也就是说运行scheduler server所需的所有参数集合:
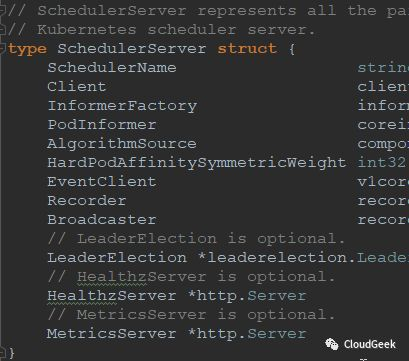
我们顺着主干往下走,看一下server.Run()方法的定义:
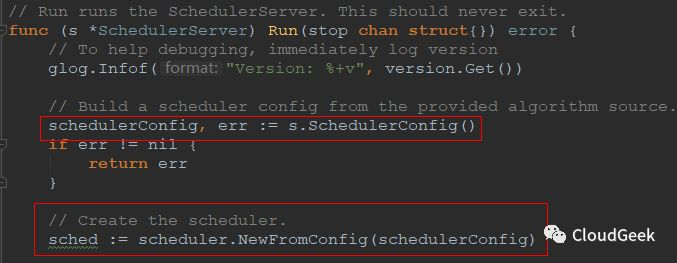
如上图,我们需要关注一下函数开头的注释,这个Run是要运行SchedulerServer,永远不退出!也就是说到这里就启动了一个server,开始无怨无悔永不停息地处理pod的scheduler流程!接着通过一个方法SchedulerConfig()获取到一个对象叫做schedulerConfig,我们也看一下这个对象的定义:Config is an implementation of the Scheduler's configured input data.
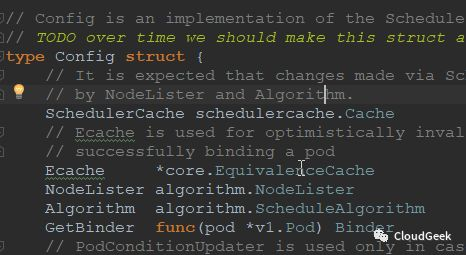
最后一个sched的创建代表着scheduler的daemon程序准备差不多了!sched的类型如下:

从注释中我们可以得到很多信息,Scheduler监视者未调度的pods,尝试寻找合适的node,把pod和node的绑定关系告诉api server!Run函数继续往后看可以找到(server.go的602行):
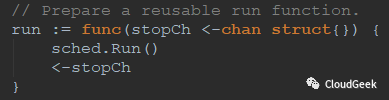
可以看到准备好了一个sched.Run(),但是没有立刻执行,626行有一个run(stop),就不贴截图了,我们直接跟到sched.Run()这个方法看一下里面写了啥:
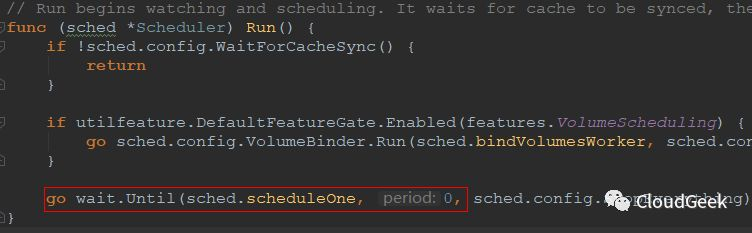
这个Run()方法开始watching and scheduling,最后面的红框需要注意几点,这是新开一个goroutine执行,然后立刻返回的。新开的goroutine是干嘛呢?每隔0秒就执行一次sched.scheduleOne方法!这里的0秒可能需要理解一下,我们看一下wait.Until()方法的定义:
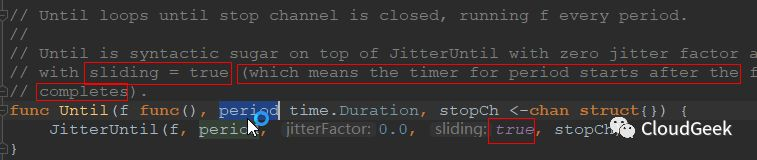
ok,其实是当f这个函数被调用完成后过0秒开始下一次调用,说白了就是前赴后继中间不休息!后面我们当然继续看scheduleOne()方法做了啥:
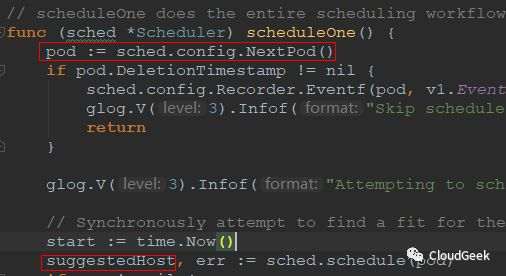
可以看到scheduleOne()方法能够处理一个pod完整的schedulering工作流。第一步是获取一个pod,这个pod的获取方法是这样定义的:

这里我们关注一下这个方法首先是阻塞的,也就是不返回一个结果就一直卡住。接着看一下suggestedHost是什么:
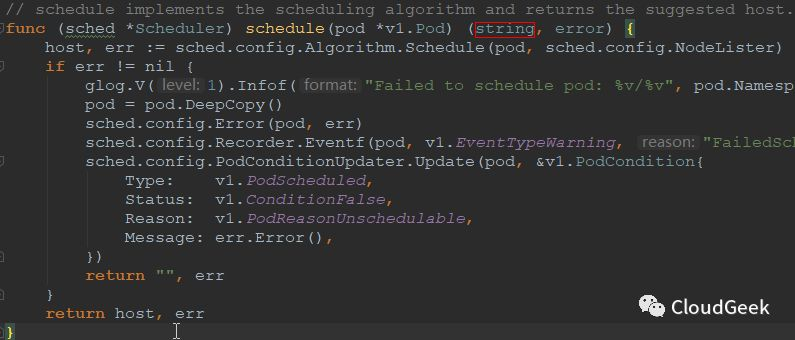
可以看到,这个类型是string,string不就意味着这就是最后的结果吗?不然怎么着也是一个[]string是吧???所以这里的suggestedHost也就是最后调度算法所给出建议跑pod的host!!!ok,我们的路没有偏离主线,继续看schedule方法的逻辑(上图中可以看到host是通过方法:sched.config.Algorithm.Schedule()获取的,我们直接看Schedule()方法):
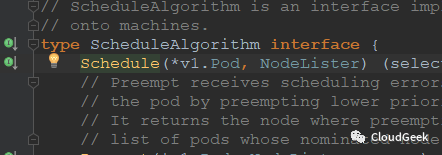
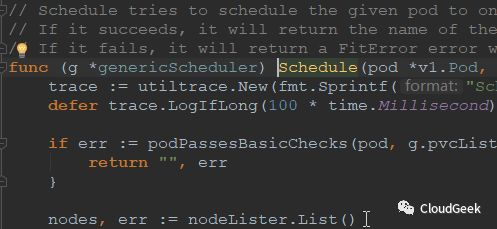
这个方法的参数是pod信息和node信息(获取node信息的接口),返回值是string类型,也就是根据pod信息和nodes信息看pod能够跑在哪个node上,然后返回这个node的名字!

上图从generic_scheduler.go的134行开始,这个msg信息很有意思,"Computing predicates",后面的findNodesThatFit()函数返回filteredNodes,也就是predicates过程的结果,返回的filteredNodes也就是可以运行pod的node集合!往下看150行处:
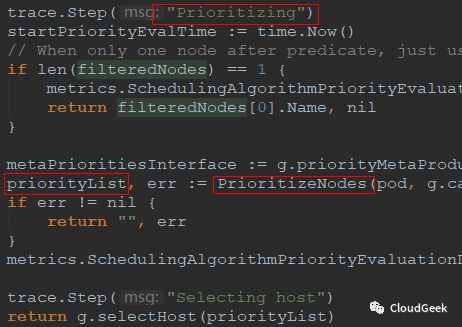
可以看到priorities过程在这里,PrioritizeNodes()函数返回一个priorityList,这个priorityList是schedulerapi.HostPriorityList类型,也就是[]HostPriority类型,HostPriority类型的定义如下:
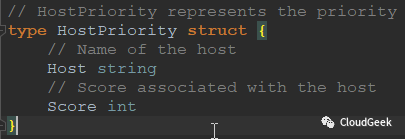
可以看到,这个类型其实存的数据就是一个节点的名字和分数信息,也就是说PrioritizeNodes()函数完成了所有可以跑pod的node的分数计算!结尾的selectHost()方法就很简单是,选择一个分高的host返回:
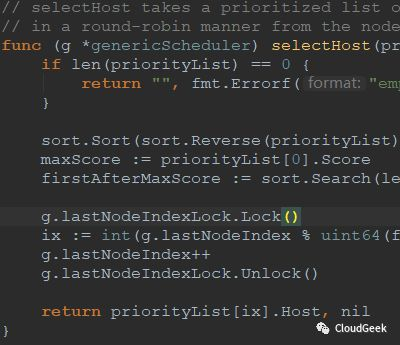
ok,总算跟完了,到这里我们就完成了整个调度过程的略读,下次开始我们可以看具体的predicates和priorities算法了!
103 - kube-scheduler源码分析 - 调度算法-寻找predicates和priorities的更多相关文章
- scheduler源码分析——preempt抢占
前言 之前探讨scheduler的调度流程时,提及过preempt抢占机制,它发生在预选调度失败的时候,当时由于篇幅限制就没有展开细说. 回顾一下抢占流程的主要逻辑在DefaultPreemption ...
- scheduler源码分析——调度流程
前言 当api-server处理完一个pod的创建请求后,此时可以通过kubectl把pod get出来,但是pod的状态是Pending.在这个Pod能运行在节点上之前,它还需要经过schedule ...
- Hadoop学习之--Capaycity Scheduler源码分析
Capacity Scheduler调度策略当一个新的job是否允许添加到队列中进行初始化,判断当前队列和用户是否已经达到了初始化数目的上限,下面就从代码层面详细介绍整个的判断逻辑.Capaycity ...
- scrapy-redis(调度器Scheduler源码分析)
settings里面的配置:'''当下面配置了这个(scrapy-redis)时候,下面的调度器已经配置在scrapy-redis里面了'''##########连接配置######## REDIS_ ...
- Storm源码分析--Nimbus-data
nimbus-datastorm-core/backtype/storm/nimbus.clj (defn nimbus-data [conf inimbus] (let [forced-schedu ...
- apiserver源码分析——启动流程
前言 apiserver是k8s控制面的一个组件,在众多组件中唯一一个对接etcd,对外暴露http服务的形式为k8s中各种资源提供增删改查等服务.它是RESTful风格,每个资源的URI都会形如 / ...
- apiserver源码分析——处理请求
前言 上一篇说道k8s-apiserver如何启动,本篇则介绍apiserver启动后,接收到客户端请求的处理流程.如下图所示 认证与授权一般系统都会使用到,认证是鉴别访问apiserver的请求方是 ...
- Quartz源码——scheduler.start()启动源码分析(二)
scheduler.start()是Quartz的启动方式!下面进行分析,方便自己查看! 我都是分析的jobStore 方式为jdbc的SimpleTrigger!RAM的方式类似分析方式! Quar ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
随机推荐
- BZOJ_2039_[2009国家集训队]employ人员雇佣_ 最小割
BZOJ_2039_[2009国家集训队]employ人员雇佣_ 最小割 Description 作为一个富有经营头脑的富翁,小L决定从本国最优秀的经理中雇佣一些来经营自己的公司.这些经理相互之间合作 ...
- 分布式缓存技术redis学习系列
分布式缓存技术redis学习系列(一)--redis简介以及linux上的安装以及操作redis问题整理 分布式缓存技术redis学习系列(二)--详细讲解redis数据结构(内存模型)以及常用命令 ...
- js面试题1
1.介绍js的基本数据类型 Undefined.Null.Boolean.Number.String 2.js有哪些内置对象? 数据封装类对象:Object.Array.Boolean.Number ...
- SpringCloud分布式微服务搭建(一)
本例子主要使用了eureka集群作为注册中心来保证高可用,客户端来做ribbon服务提供者的负载均衡. 负载均衡有两种,第一种是nginx,F5这种集中式的LB,对所有的访问按照某种策略分发. 第二种 ...
- js实现 页面加载 完成 后顺序 执行
function addLoadEvent(func){ var oldonLoad = window.onload; if(typeof window.onload != 'function'){ ...
- springcloud和springboot是什么关系?
[学习笔记] 4)springcloud和springboot是什么关系? 马克-to-win@马克java社区:springboot可以快速开发单个微服务.springcloud是一个基于sprin ...
- 浅谈CSS3 box-sizing 属性 有趣的盒模型
盒模型的组成大家肯定都懂,由里向外content,padding,border,margin. 盒模型是有两种标准的,一个是标准模型,一个是IE模型. 从上面两图不难看出在标准模型中,盒模型的宽高只是 ...
- GridView 的简单应用
gridView 是android一个控件主要是显示列似与九宫格这样的效果.废话不多说直接上代码. 首先是需要一个适配器来确定每一个里面的布局,在里面我自定义了一个点击事件,当点击图片布局的时候触发, ...
- Android-----Intent中通过startActivity(Intent intent )显式启动新的Activity
Intent:即意图,一般是用来启动新的Activity,按照启动方式分为两类:显式Intent 和 隐式Intent 显示Intent就是直接以“类名称”来指定要启动哪一个Activity:Inte ...
- ionic cordova build android error: commamd failed with exit code eacces
问题: 电脑的gradle版本为Gradle 5.0,然而 因为 添加的android 平台为6.3.0 gradle 是 4.1版本 电脑已存在 gradle的情况下,add platform 成功 ...