NLP︱句子级、词语级以及句子-词语之间相似性(相关名称:文档特征、词特征、词权重)
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
关于相似性以及文档特征、词特征有太多种说法。弄得好乱,而且没有一个清晰逻辑与归类,包括一些经典书籍里面也分得概念模糊,所以擅自分一分。

——————————————————————————————————————————————
一、单词的表示方式
1、词向量
词向量是现行较为多的方式,另外一篇博客已经写了四种词向量的表达方式,两两之间也有递进关系,BOW可升级到LDA;hash可升级到word2vec,继续升级doc2vec。参考:自然语言处理︱简述四大类文本分析中的“词向量”(文本词特征提取)
2、TF
词频有两类:在本文档的词频以及单词在所有文档的词频。
3、TFIDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息搜索和信息挖掘的常用加权技术。在搜索、文献分类和其他相关领域有广泛的应用。
TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)的主要思想是:如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
使用TF*IDF可以计算某个关键字在某篇文章里面的重要性,因而识别这篇文章的主要含义,实现计算机读懂文章的功能。
4、ATC,Okapi,LTU
这三种权重方案都是TF-IDF的变种,引入了其它的因素。ATC引入了所有文档中的词语的最大频率,同时使用了欧几里德距离作为文档长度归一化考虑。Okapi和LTU使用了类似的方式来考虑文档长度(文档长度越长,那么相对来说,词语的频率也越高,所以,需要对于长文档给出一定的惩罚,但又不能惩罚太厉害,因此:dl/avg_dl),但它们采用了不同的方式来处理词语的频率。LTU使用的是log(fij),而Okapi使用的是fij/(fij + 2)。

(图片来源:文档中词语权重方案一览)
——————————————————————————————————————————————
二、词语与词语间
1、点间互信息(PMI)

 (从中可以看到这个值代表着,x在y出现情况的概率,同时也y在x出现情况下的概率)
(从中可以看到这个值代表着,x在y出现情况的概率,同时也y在x出现情况下的概率)当X,Y关联大时,MI(X,Y)大于0;当X与Y关系弱时,MI(X,Y)等于0;当MI(X,Y)小于0时,X与Y称为“互补关系”(参考于博客:关键词与关键词之间的相关度计算)
2、★PMI延伸版:情感倾向SO-PMI

MI的应用与延伸(来源于:Mutual Information 互信息的应用):
(1)互信息(Mutual Information,MI)在文本自动分类中的应用,体现了词和某类文本的相关性
(2)新词发现的思路如下:对训练集中的文本进行字频的统计,并且统计相邻的字之间的互信息,当互信息的值达到某一个阀值的时候,我们可以认为这两个字是一个词,三字,四字,N字的词可以在这基础上进行扩展
(3)计算 检索的关键字与检索结果的相关性,而这种计算又可以转换为 检索的关键字与检索结果的词的相关性计算。此时还是可以使用互信息(Mutual Information,MI)来进行计算,但是计算的数量要增加不少
(4)互信息(Mutual Information,MI) 的缺点是 前期预处理的计算量比较大,计算结果会形成一个 big table,当然只要适当调整阀值还是可以接受的。
3、★MI进化版——左右信息熵★
(参考于:基于互信息和左右信息熵的短语提取识别)
熵这个术语表示随机变量不确定性的量度。具体表述如下: 一般地, 设X 是取有限个值的随机变量( 或者说X 是有限个离散事件的概率场) , X 取值x 的概率为P ( x ) , 则X 的熵定义为:

左右熵是指多字词表达的左边界的熵和右边界的熵。左右熵的公式如下:

具体计算方法是,以左熵为例,对一个串左边所有可能的词以及词频,计算信息熵,然后求和。
上面的结果中很多熵是0,说明它只有一种接续。
——————————————————————————————————————————————
三、词语与句子间
1、DF(Document Frequency)/IDF
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性,DF的定义如下:
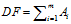
DF的动机是,如果某些特征词在文档中经常出现,那么这个词就可能很重要。而对于在文档中出现很少(如仅在语料中出现1次)特征词,携带了很少的信息量,甚至是"噪声",这些特征词,对分类器学习影响也是很小。
DF特征选择方法属于无监督的学习算法(也有将其改成有监督的算法,但是大部分情况都作为无监督算法使用),仅考虑了频率因素而没有考虑类别因素,因此,DF算法的将会引入一些没有意义的词。如中文的"的"、"是", "个"等,常常具有很高的DF得分,但是,对分类并没有多大的意义。
2、MI(Mutual Information)
互信息法用于衡量特征词与文档类别直接的信息量,互信息法的定义如下:
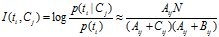
继续推导MI的定义公式:
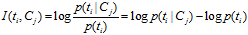
从上面的公式上看出:如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3、IG(Information Gain)
信息增益法,通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
信息增益的定义如下:
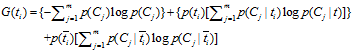
依据IG的定义,每个特征词ti的IG得分前面一部分: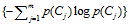 计算值是一样,可以省略。因此,IG的计算公式如下:
计算值是一样,可以省略。因此,IG的计算公式如下:
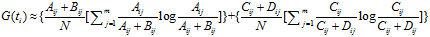
IG与MI存在关系:
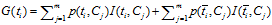
因此,IG方式实际上就是互信息 与互信息
与互信息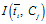 加权。
加权。
4、CHI(Chi-square)
CHI特征选择算法利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的,如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。CHI的定义如下:
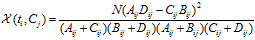
对于一个给定的语料而言,文档的总数N以及Cj类文档的数量,非Cj类文档的数量,他们都是一个定值,因此CHI的计算公式可以简化为:

CHI特征选择方法,综合考虑文档频率与类别比例两个因素
要选择一种度量,来有效地选择出特征词向量。基于论文《A comparative study on feature selection in text categorization》,我们选择基于卡方统计量(chi-square statistic, CHI)技术来实现选择,这里根据计算公式:
其中,公式中各个参数的含义,说明如下:

- N:训练数据集文档总数
- A:在一个类别中,包含某个词的文档的数量
- B:在一个类别中,排除该类别,其他类别包含某个词的文档的数量
- C:在一个类别中,不包含某个词的文档的数量
- D:在一个类别中,不包含某个词也不在该类别中的文档的数量
要想进一步了解,可以参考这篇论文。
使用卡方统计量,为每个类别下的每个词都进行计算得到一个CHI值,然后对这个类别下的所有的词基于CHI值进行排序,选择出最大的topN个词(很显然使用堆排序算法更合适);最后将多个类别下选择的多组topN个词进行合并,得到最终的特征向量。
(参考于:使用libsvm实现文本分类)
5、WLLR(Weighted Log Likelihood Ration)
WLLR特征选择方法的定义如下:
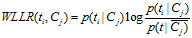
计算公式如下:
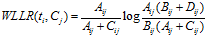
6、WFO(Weighted Frequency and Odds)
最后一个介绍的算法,是由苏大李寿山老师提出的算法。通过以上的五种算法的分析,李寿山老师认为,"好"的特征应该有以下特点:
- 好的特征应该有较高的文档频率
- 好的特征应该有较高的文档类别比例
WFO的算法定义如下:
如果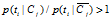 :
:
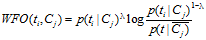
否则:
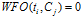
不同的语料,一般来说文档词频与文档的类别比例起的作用应该是不一样的,WFO方法可以通过调整参数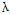 ,找出一个较好的特征选择依据。
,找出一个较好的特征选择依据。
——————————————————————————————————————————————
四、句子与句子间
句子之间的相似性,一般用词向量组成句向量。
根据词向量组成句向量的方式:
如果是一词一列向量,一般用简单相加(相加被证明是最科学)来求得;
一个词一值的就是用词权重组合成向量的方式;
谷歌的句向量sen2vec可以直接将句子变为一列向量。
详情看:自然语言处理︱简述四大类文本分析中的“词向量”(文本词特征提取)
——————————————————————————————————————————————
五、一些案例摘要
1、利用点间互信息+滑动窗口 组成短语
怎样确定两个词是否是固定的搭配呢?我们通过计算两个词间的归一化逐点互信息(NPMI)来确定两个词的搭配关系。逐点互信息(PMI),经常用在自然语言处理中,用于衡量两个事件的紧密程度。
归一化逐点互信息(NPMI)是逐点互信息的归一化形式,将逐点互信息的值归一化到-1到1之间。
如果两个词在一定距离范围内共同出现,则认为这两个词共现。筛选出NPMI高的两个词作为固定搭配,然后将这组固定搭配作为一个组合特征添加到分词程序中。如“回答”和“问题”是一组固定的搭配,如果在标注“回答”的时候,就会找后面一段距离范围内是否有“问题”,如果存在那么该特征被激活。

归一化逐点互信息(npmi)的计算公式

逐点互信息(pmi)的计算公式
滑动窗口
可以看出,如果我们提取固定搭配不限制距离,会使后面偶然出现某个词的概率增大,降低该统计的稳定性。在具体实现中,我们限定了成为固定搭配的词对在原文中的距离必须小于一个常数。具体来看,可以采用倒排索引,通过词找到其所在的位置,进而判断其位置是否在可接受的区间。这个简单的实现有个比较大的问题,即在特定构造的文本中,判断两个词是否为固定搭配有可能需要遍历位置数组,每次查询就有O(n)的时间复杂度了,并且可以使用二分查找进一步降低复杂度为O(logn)。
其实这个词对检索问题有一个更高效的算法实现。我们采用滑动窗口的方法进行统计:在枚举词的同时维护一张词表,保存在当前位置前后一段距离中出现的可能成词的字符序列;当枚举词的位置向后移动时,窗口也随之移动。
这样在遍历到 “回答” 的时候,就可以通过查表确定后面是否有 “问题” 了,同样在遇到后面的 “问题” 也可以通过查表确定前面是否有 “回答”。当枚举下一个词的时候,词表也相应地进行调整。采用哈希表的方式查询词表,这样计算一个固定搭配型时间复杂度就可以是O(1)了。
通过引入上述的上下文的信息,分词与词性标注的准确率有近1%的提升,而对算法的时间复杂度没有改变。我们也在不断迭代升级以保证引擎能够越来越准确,改善其通用性和易用性。

来源于BostonNLP:BosonNLP分词技术解密
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
NLP︱句子级、词语级以及句子-词语之间相似性(相关名称:文档特征、词特征、词权重)的更多相关文章
- 2018.12/6 js键盘事件 DOM:0级2级
DOM0级事件元素绑定多个click最后只执行最后一个click. DOM2级事件元素绑定多个click,都要执行 注意当绑定的多个事件名,函数名,事件发生阶段三者完全一样时,才执行最后一个 div. ...
- [Unity3D]巧妙利用父级子级实现Camera场景平面漫游
本文系作者原创,转载请注明出处 入门级的笔者想了一上午才搞懂那个欧拉角的Camera旋转..=.= 在调试场景的时候,每次都本能的按下W想前进,但是这是不可能的(呵呵) 于是便心血来潮想顺便添加个Ke ...
- Linux线程的实现 & LinuxThread vs. NPTL & 用户级内核级线程 & 线程与信号处理
另,线程的资源占用可见:http://www.cnblogs.com/charlesblc/p/6242111.html 进程 & 线程的很多知识可以看这里:http://www.cnblog ...
- CSS文档流与块级元素和内联元素
CSS文档流与块级元素(block).内联元素(inline),之前翻阅不少书籍,看过不少文章, 看到所多的是零碎的CSS布局基本知识,比较表面.看过O'Reilly的<CSS权威指南>, ...
- delphi 选中的展开0级 子级不展开
TreeView1.Selected.Expand(False); //选中的展开0级 子级不展开 TreeView1.Selected.Expand(True); //全部展开 来自为知笔记(Wiz ...
- CSS文档流与块级元素和内联元素(文档)
CSS文档流与块级元素(block).内联元素(inline),之前翻阅不少书籍,看过不 少文章, 看到所多的是零碎的CSS布局基本知识,比较表面.看过O'Reilly的<CSS权威指 南> ...
- 菜鸟级SQL Server21天自学通(文档+视频)
SQL语言的主要功能就是同各种数据库建立联系,进行沟通.按照ANSI(美国国家标准协会)的规定,SQL被作为关系型数据库管理系统的标准语言.SQL语句可以用来执行各种各样的操作,例如更新数据库中的数据 ...
- 创作gtk源码级vim帮助文档 tags
创作gtk源码级vim帮助文档 tags 缘由 那只有看到源码了.在linux源码上有个网站 http://lxr.linux.no /+trees, 可以很方面的查出相应版本的代码实现,gtk没有. ...
- 列表 ul ol dl 和 块级标签和行及标签之间的转换
1. 无序列表 有序列表 自定义列表 1,无序列表 第一 你不必须有子标签 <li></li> 第二 ul天生自带内外边距 List-style的属性值 circle(空心圆 ...
随机推荐
- CSS继承、层叠和特殊性
1.继承 (1)样式应用于某个特定的HTML标签元素,而且应用于其后代. (2)但某些标签不适用,如border: (3)例子:p{color:red;}设置了颜色 <p class=" ...
- Eclipse导入项目文件夹
Eclipse项目导入出现感叹号解决方法 出现这样的情况怎么办 右击项目名-Bulid path -configure Bulid path 选择Libraries-Remove(移去错的)-Add ...
- Lambda表达式详解 (转)
前言 1.天真热,程序员活着不易,星期天,也要顶着火辣辣的太阳,总结这些东西. 2.夸夸lambda吧:简化了匿名委托的使用,让你让代码更加简洁,优雅.据说它是微软自C#1.0后新增的最重要的功能之一 ...
- python的logging模块
python提供了一个日志处理的模块,那就是logging 导入logging模块使用以下命令: import logging logging模块的用法: 1.简单的将日志打印到屏幕上 import ...
- python中的函数对象与闭包函数
函数对象 在python中,一切皆对象,函数也是对象 在python语言中,声明或定义一个函数时,使用语句: def func_name(arg1,arg2,...): func_suite 当执行流 ...
- ABP官方文档翻译 8.2 SignalR集成
SignalR集成 介绍 安装 服务器端 客户端 建立连接 內建特征 通知 在线客户端 PascalCase与CamelCase对比 你的SignalR代码 介绍 ABP中的Abp.Web.Signa ...
- python---协程 学习笔记
协程 协程又称为微线程,协程是一种用户态的轻量级线程 协程拥有自己的寄存器和栈.协程调度切换的时候,将寄存器上下文和栈都保存到其他地方,在切换回来的时候,恢复到先前保存的寄存器上下文和栈,因此:协程能 ...
- 【Tools】ubuntu16.04升级Python2.7到3.5
最近开始学Python,但我发现我ubuntu16.04上默认的Python是2.7,并不是3,x 于是准备Python升级,记录安装过程给初学者参考一下. 1.先取得管理员权限, 个人习惯先取得管理 ...
- Docker命令行安装Shipyard
1.下载自动部署Shell脚本 curl -sSL https://shipyard-project.com/deploy | bash -s 自动部署脚本中, 包括以下参数: ACTION: 表示可 ...
- centos7下安装vsftpd
安装步骤: 创建ftp目录 cd / mkdir ftpfile 创建指定登陆用户并不让他拥有登陆系统的权限(设置指定登陆shell) useradd ftpuser -d /ftpfile/ -s ...