第二周Python讲课内容--日记
1、初识模块:sys、os
标准模块库存放在lib文件夹里
三方库模块一般存放在packages文件夹里
模块调用方法:import sys/os
sys模块:
sys.path 打印环境变量
sys.argv 打印文件的相对路径
sys.argv[0/1] 0表示打印当前程序名,1表示打印执行文件后面输入的内容如:python sys.py 1 2 3 打印成(1,2,3)列表,以空格分割
os模块:与系统打交道的模块
os.system("dir") 列出系统目录,只能显示
os.popen("dir") 列出目录,能存入变量
os.mkdir 新建目录
创建库模块:
1、文件同级目录下创建存放
2、加绝对路径
3、存放在site-packages目录下
PYC文件:是python编译执行的文件,Py程序执行时会先检查是否有该文件,有就直接执行该 文件,如果源文件修改,Py则会先看是否有pyc文件如果有会检查时间是否最新,不是则会重新编译文件文件,老师这么讲的。 我个人觉得应该是Py没修改源码则会检查是否有pyc文件,有就直接执行,没有在编译,而修改了源的Py会直接重新编译
2、数据类型:
整数型:
int (整型)
32位的机器 上,整数为32位,取值:2**31 和 -2**31-1
64位的机器上,整数为64位,取值:2**63 和 -2**63-1
长整数:
长整 数是一些比较大的整数python3里面没有了
布尔值:
True真 Flose假
0 或 1
3、运算符:
& 按位与运算符
| 按拉或运算符
^ 按位异或运算符
<< 左移动运算符
>> 右移动运算符
示例:
128 64 32 16 8 4 2 1 十进制
1 1 1 1 1 1 1 1 二进制
0 0 0 0 1 1 0 0 12
0 0 0 1 0 1 1 0 22
12 & 22 &运算,相同的真为真,不同的都为假,最终结果:4
0 0 0 0 0 1 0 0 4
12 | 22 | 运算,一个为真或两个都为真就为真,最终结果:30
0 0 0 1 1 1 1 0 30
12 ^ 22 ^ 运算,两个相同为假,不相同为真,最终结果:26
0 0 0 1 1 0 1 0 26
4、映像类型:
name = {“john”:['pipop',12]}
print(name[john])
将打印出[]列表里的数据,john变量的类型为:dict 类型
5、三元运算:
变量a = 值1 if a>b else 值2
如果a大于b输出值a,如果a小于b则输出值2
6、16进制转换:
1 2 3 4 5 6 7 8 9 A B C D E
16进制每个数占4个字节,0000, 如 E 等于 1111
7、编码和解码:
‘hello word!’.encode('UTF-8') 用UTF-8格式进行编码
‘hello word!’.decode(‘UTF-8’) 用UTF-8格式进行解码
8、列表:
names = ["ZhangShan","LiShi","WangWu",LiLiu]
print (names[0],names[2]) 用下标编号输出,ZhangShan和WangWu --------指定输出
print(names[1:3]) 取出LiShi和WangWu ----指定起始下标,获取指定值
print(nnames[-2]) 从后面开始取,取倒数第二个
print(names[-2:0]) 从倒数第二个开始取,直到最后一个,0个以省略如names[-2:0]
添加:
names.append("xiaoming") 默认添加到最后
names.insert(1,xiaoming) 插入到指定位置
修改:
names[2] = "XiaoMing" 修改指定位置数组
删除:
names.remove("XiaoMing") 直接用数组名删除
del names[1] 指定下标,删除数组
names.pop() 指定下标删除,不指定默认删除最后一个
names.clear() 统计有多少个重复的
查找:
names.index("XiaoMing") 取出指定数组名的下标号
print(names.index("XiaoMing")) 直接打印出来
统计重复的:
names.count("XiaoMing") 统计出有多少个重复的
反转:reverse
names.reverse() 反转数组
排序:sort
names.sort() 排序,:#1Aa 特殊-数字-大小写
合并:
names.extend(names2) 把names2合并到names里面来,原数据不删除
9、列表:
复制:
names2 = names.copy() 浅复制,只复制第一层列表,第二层不做完全复制,数据会跟着改变
names3 = list(names) 浅复制,功能同上
(使用案例,同一个数据,多个帐号登陆管理)
完整复制:
引入完整模块:import copy
names2 = copy.deepcopy(names) 完整复制一份,一般不用,太占内存
修改列表中的列表:
names[1][2] = "yes" 修改第一个列表下标为1的数组,2为数组里的列表里下标为2的数组进行修改,赋值为yes
布长切片:
names[0:-1:2] 从0下标开始取,到倒数第1位,且跳2位取一位 ----0可以省略
names[::2] 简写
names[:]
10、for循环:
for i in names:
print(i) for循环列表,赋值给i变量,输出i
11、元组:
特点,只能读取,不能修改。
方法:
count:names.count(参数) 如果能匹配到元组里的参数则返回 1 , 匹配不到返回 0
index:names.index(参数) 返回匹配到元组的下标
for index names in enumerate(a) 同时输出下标号和元组内容
12、.isdigit方法:
salary = input("输出工资")
if salary.isdigit() isdigit判断salary接收的数值是否为整数,如果是输出为真不是输出为假
13、购物车实例:
shoping = [('iphone',1200),('ipad',2300),('XiaoMi',5200),('Linux book',100)] ----定义物品列表
shoping2 = [] ----定义一个空列表
salary = input("输入你的工资>>:") ----输入工资
if salary.isdigit(): ----判断输入值是否为整数
salary = int(salary) ------如果是整数转换为int型
while True: -----循环
for index,time in enumerate(shoping): -----循环出列表内容和下标号,分别赋值给index和time
print(index,time) ---输出内容
user_choice = input("选择商品>>:") ---输入选择的商品
if user_choice.isdigit(): -----判断输入的商品编号是否为整数
user_choice = int(user_choice) ---把输入的编号转换为int型
if user_choice < len(shoping) and user_choice >=0: ----判断,如果输入的编号小于列表的长度 且 输入编号大于等0
time = shoping[user_choice] ---time里数组等于:用户输入编号下标的数组
if time[1] <= salary: ---判断,如果time里下标为1的数组的值小于或者等于输入的工资
shoping2.append(time) ---就把time的数组添加到shopping2的空列表中去
salary -= time[1] ---然后现在的工资减去原有的工资,在赋给time里下标为1的数组
print("购买的商品:%s,剩余的钱:%s"%(time,salary)) ----打印出购买的商品,使用%s格式化传参 --%s and %s %(a,b)
else:
print("余额:%s,买不起了"%salary) -----如果工资大于了商品的输出工资
else:
print("你输入:%s商品不存在。。。"%user_choice) ---如果商品编号不等于下标数的,输出商品不存在
elif user_choice == 'a': ----如果中途输入a 执行下列条件
print("---------------shoping list---------------")
for p in shoping2: -----循环shopping2 空列表里的内容,并打印
print(p)
print("you are money :%s"%salary) ----打印出工资
exit()
14、字符串的常用操作:
name = "john ish tdk"
name.capitalize() 首写字母大写
.count("H") 统计指定字符个数,例:里边有2个H
.center(22,'-') 保证name里的字符长度为22个,不够的用 - 填充
.endswith(@.com) 判断指定结尾字符串,如邮箱:@.com 匹配成功返回True 和 Flase
.expandtabs(tabsize=30) 把table转成30个空格,没什么用
.find(“ish”) 最字符索引,查看ish是从多少个字符开始的
方法:name[name.find("ish"):] 从ish开始切片,到最后
.format(a='aa',b='bb') 格式化输出,如:a=1 b=2 print ("{c},{d}".format(c=a,d=b)) ,最后输出ab的结果
.isalnum() 英文和数字返回为真:‘abc’.isalnum() 返回为True
.isalpha() 纯英文字母返回为真,其它返回为假
.isdecimal() 十进制返回为真,其它为假
.isdigit() 整数为真,其它为假
.isidentifier() 判断是否是一个合法的变量名、合法的标识符
.isnumeric() 判断只有数字在里面返回为真,是数字为真,否则为假
.istitle() 判断是否为标题,每个单词首写字母大写,为真
.isupper() 判断字母全大写为真
.join 字符串连接,例:print('+'.join(['a','b','c']))
.ljust(23,'+') 保证字符的长度为23位,如果不够后面补齐
..rjust(23,'+') 同上相反
.lower() 把大写字母变小写
.upper() 把小写字母变大写
.lstrip() 去除左边的空格和回车
.rstrip() 去除右边的空格和回车
.strip() 全去掉
.maketrans('原始参数','对应参数') 对应参数赋值:
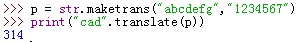
.replace('n','N',1) 把n替换成N,后面参数是替换多少个n,替换后:Nan
.rfind('n') 找到最后一个n的下标,返回下标
.split() 把字符串分割成列表,默认是空格,可以用字符串里的特殊指定值为分割符,('1')指定1为分割符
.splitlines() 按分行符来分割
.swapcase() 把大写的变小写,小写的变大写
.title() 变成标题,把每个单词的首写字母变成大写
.zfill(20) 如果字符不够20位长,用0填充
15、字典的使用:
info = {
‘stu1101’:"TaoBao", stu1101 为字典中的key,后面的为value值
'stu1102':"JinDong",
'stu1103':"BaiDu",
}
print(info["stu1102"]) 输出JinDong,不显示key
增改:
info["1104"] = "MeiTuan" 直接通过key添加,如果有就直接修改
删除:
标准删除:info.pop("stu1104")
DEL删除:del info["stu1104"]
随机删除:info.popitem()
查找:
标准用法:“stu1102” in info 有返回True没有返回Flose
最安全的用法:info.get('stu1103') 有返回为True、没有返回为None不会报错
values:只打印所有的值,不打印key :info.values
keys:只打印所有的key,:info.keys()
setdefault 如果找到指定的就取出来,如果未找到就直接添加,例:info.setdefault("stu1106","DoDo")
update() 合并两个字典,如果字典里有相同的将合并替换,没有的添加,例:info.update(b),合并b字典到info里
循环:
方法1:常用建议用这个
for key in info:
print(key,info[key])
方法2:dict循环,这个会先把dict转换成list,数据大的时候很消耗资源
for k,v in info.items():
print(k,v)
16、三级菜单案例:
# ------------------三级菜单---------------
date = {
"中国":{
"重庆":{
"江北":["北音桥","大庙"],
"渝北":["光电园","人和"]
},
"上海":{
"海边":["北音桥","大庙"],
"海里":["光电园","人和"]
}
},
"外国":{
"美国":{
"洛杉矶":["白宫","黑市"],
"北岸":["光阳","太和"]
}
}
}
exit_flag = False #定义一个布尔值
while not exit_flag: #默认只要为false就不退出,为True就退出
for i in date: #循环date第一层
print(i) #输出date
choice = input("选择进入1:") #输入你选择的那一层
if choice in date: #匹配choice的值在不在date字典里
while not exit_flag: #默认循环
for i2 in date[choice]: #循环date下choice输入的值下的字典,赋给i2
print(i2)
choice2 = input("输入进入2:") #输入打印i2,里的值
if choice2 in date[choice]: #如果输入和date下choice下的值匹配,往下执行
while not exit_flag: #默认循环
for i3 in date[choice][choice2]: #循环date[][]下的值 赋给i3
print(i3) #输出
choice3 = input("输入进入3:") #输入i3打印出来的值进行选择
if choice3 in date[choice][choice2]: #如果输入的值和date[][]下的值匹配
for i4 in date[choice][choice2][choice3]: #循环date[][][]下的值
print(i4)
choice4 = input("返回按A>>:")
if choice4 == 'a': #如果输入的是A,什么都不做,继续循环
pass
elif choice4 == 'q': #输入的为q,exit_fila变为真,则退出
exit_flag = True
if choice3 == 'a':
break
elif choice3 == 'q':
exit_flag == True
if choice2 == 'a':
break
elif choice2 == 'q':
exit_flag == True
-----感觉有点跟不起,绕得有点多,跟不上套路,可能是写得少
第二周Python讲课内容--日记的更多相关文章
- 第一周Python讲课内容--日记
1.python的发展史,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年...... 2.第一个helloword程序的开始 3.变量的含义,赋值传参数的作 ...
- Python学习之旅--第二周--python基础
一.什么是pyc? 1.Python是解释性语言,那么.pyc是什么文件? 2.解释性语言和编译型语言区别: 计算机是不能够识别高级语言的,所以当我们运行一个高级别语言程序时,就需要一个&quo ...
- 第二周Python笔记 数据类型 列表 字典
列表,拉锁式儿合并. [ [a,b] for a,b in zip(list1,list2)] #最笨的 a=[1,2,3,4,5] b=[2,3,4,5,6] d=[] for i in range ...
- 第二周Python学习笔记
分支结构: ① 单分支结构: 非常简单,if 条件语句,如果为true 则输出结果.否则不输出结果 ② 二分支结构: 条件结果为true则执行语句1,否则就执行语句2 If <条件>: ...
- 第二周Python笔记之 变量的三元运算
如果变量a小于b,则d的值取a变量的值,否则取c变量的值
- 第二周python作业
print("今有不知其数,三三数之剩二,五五数之剩三,七七数之剩二,问几何?\n") number=int(input("请输入您认为符合条件的数: ")) ...
- 20172302 《Java软件结构与数据结构》第二周学习总结
2018年学习总结博客总目录:第一周 第二周 教材学习内容总结 第三章 集合概述-栈 3.1 集合 (1) 集合是一种聚集,组织了其他对象的对象.它定义一张破那个特定的方式,可以访问.管理所包含的对象 ...
- 20145127《java程序设计》第二周学习总结
本周我又对java程序进行了更进一步的学习.相比与上一周的学习内容的宏观,这一周的所学更加的系统和调理明确. 本周是对java基础语法的学习.首先,我先是认识类型与变量. Java可区分为基本类型和类 ...
- Python 学习日记(第二周)
从这周开始我就正式学习Python 语言了.以后每周都会有一篇有关于学习Python的见闻与大家分享! Python的安装 学习的第一步首先要有一个运行的环境.所以接下来介绍一下安装的步骤. 通过Py ...
随机推荐
- java url demo
// File Name : URLDemo.java import java.net.*; import java.io.*; public class URLDemo { public stati ...
- Swift 之属性setter、getter方法
Swift 之属性setter.getter方法 Swift中的属性分为两种属性,一种就是计算型属性 一种就是存储型属性,开始我虽然知道这两种属性,但是了解并不深对于他的setter和getter方法 ...
- R实战 第三篇:数据处理(基础)
数据结构用于存储数据,不同的数据结构对应不同的操作方法,对应不同的分析目的,应选择合适的数据结构.在处理数据时,为了便于检查数据对象,可以通过函数attributes(x)来查看数据对象的属性,str ...
- Caused by:java.sql.SQLException:ORA-01008:并非所有变量都已绑定
1.错误描述 Caused by:java.sql.SQLException:ORA-01008:并非所有变量都已绑定 2.错误原因 3.解决办法
- asp.net mvc razor布局页中a标签的href的跳转问题
笔者做了一个文件上传系统,文件上传后,保存在wwwroot目录的file文件夹中,并把该文件的路径保存到数据库中, 如这样的一个路径保存在数据库: file/b775f487-0127-41e0-9d ...
- River Hopscotch POJ - 3258
Every year the cows hold an event featuring a peculiar version of hopscotch that involves carefully ...
- 异常-----freemarker.template.TemplateException: Expected collection or sequence. datas evaluated instead to freemarker.core.HashLiteral$SequenceHash on line 7, column 18 in inc/select.ftl.
1.错误描述 六月 26, 2014 11:26:27 下午 freemarker.log.JDK14LoggerFactory$JDK14Logger error 严重: Template proc ...
- C# 图解教程 第四章 类的基本概念
类的基本概念 类的概述声明类 类成员字段方法 创建变量和类的实例为数据分配内存实例成员访问修饰符 私有访问和公用访问 从类的内部访问成员从类的外部访问成员综合应用 类的基本概念 类的概述 类是一种活动 ...
- Aspose.Words for .NET
Aspose.Words for .NET Aspose.Words for .NET是 .NET 下先进的 Word 文档处理 API.它支持 DOC, OOXML, RTF, HTML, Open ...
- 如何在Java应用中提交Spark任务?
最近看到有几个Github友关注了Streaming的监控工程--Teddy,所以思来想去还是优化下代码,不能让别人看笑话,是不.于是就想改在一下之前最丑陋的一个地方--任务提交 本博客内容基于Spa ...